
API Codable в Swift, представленный в Swift 4, позволяет нам использовать возможности компилятора для упрощения сопоставления данных из сериализованных форматов с типами Swift.
Возможно, вы использовали Codable для сопоставления данных из веб-API с моделью данных вашего приложения (и наоборот), но он гораздо более гибок.
В этом руководстве мы рассмотрим, как Codable можно использовать для сопоставления данных из Cloud Firestore с типами Swift и наоборот.
При получении документа из Cloud Firestore ваше приложение получит словарь пар ключ/значение (или массив словарей, если вы используете одну из операций, возвращающих несколько документов).
Конечно, вы можете продолжать использовать словари напрямую в Swift, и они предлагают большую гибкость, которая может идеально подойти для вашей задачи. Однако такой подход не является типобезопасным, и легко допустить ошибки, которые трудно отследить, например, неправильно написать имена атрибутов или забыть сопоставить новый атрибут, добавленный вашей командой при выпуске новой интересной функции на прошлой неделе.
В прошлом многие разработчики обходили эти недостатки, реализуя простой слой сопоставления, который позволял им сопоставлять словари с типами Swift. Но опять же, большинство этих реализаций основаны на ручном указании соответствия между документами Cloud Firestore и соответствующими типами модели данных вашего приложения.
Благодаря поддержке Codable API в Cloud Firestore , это становится намного проще:
- Вам больше не придётся вручную реализовывать какой-либо код сопоставления.
- Легко определить, как сопоставлять атрибуты с разными именами.
- В нём реализована встроенная поддержка многих типов данных Swift.
- И добавить поддержку сопоставления пользовательских типов очень просто.
- Самое приятное: для простых моделей данных вам вообще не придётся писать код для сопоставления данных.
Картографические данные
Cloud Firestore хранит данные в документах, где ключи сопоставляются со значениями. Чтобы получить данные из отдельного документа, можно вызвать DocumentSnapshot.data() , который возвращает словарь, сопоставляющий имена полей с типом Any : func data() -> [String : Any]? .
Это означает, что мы можем использовать синтаксис индексации Swift для доступа к каждому отдельному полю.
import FirebaseFirestore
#warning("DO NOT MAP YOUR DOCUMENTS MANUALLY. USE CODABLE INSTEAD.")
func fetchBook(documentId: String) {
let docRef = db.collection("books").document(documentId)
docRef.getDocument { document, error in
if let error = error as NSError? {
self.errorMessage = "Error getting document: \(error.localizedDescription)"
}
else {
if let document = document {
let id = document.documentID
let data = document.data()
let title = data?["title"] as? String ?? ""
let numberOfPages = data?["numberOfPages"] as? Int ?? 0
let author = data?["author"] as? String ?? ""
self.book = Book(id:id, title: title, numberOfPages: numberOfPages, author: author)
}
}
}
}
Хотя на первый взгляд этот код может показаться простым и легким в реализации, он ненадежен, сложен в сопровождении и подвержен ошибкам.
Как видите, мы делаем предположения о типах данных полей документа. Эти предположения могут быть верными, а могут и не быть.
Помните, что поскольку схемы нет, вы можете легко добавить новый документ в коллекцию и выбрать другой тип для поля. Вы можете случайно выбрать строку для поля numberOfPages , что приведет к труднообнаружимой проблеме сопоставления. Кроме того, вам придется обновлять код сопоставления каждый раз, когда добавляется новое поле, что довольно обременительно.
И не будем забывать, что мы не используем преимущества строгой системы типов Swift, которая точно знает правильный тип для каждого из свойств класса Book .
Что же такое Codable?
Согласно документации Apple, Codable — это «тип, который может преобразовывать себя во внешнее представление и обратно». Фактически, Codable является псевдонимом для протоколов Encodable и Decodable. Приведя тип Swift в соответствие с этим протоколом, компилятор синтезирует код, необходимый для кодирования/декодирования экземпляра этого типа из сериализованного формата, такого как JSON.
Простой тип данных для хранения информации о книге может выглядеть так:
struct Book: Codable {
var title: String
var numberOfPages: Int
var author: String
}
Как видите, приведение типа в соответствие с Codable требует минимальных изменений. Нам нужно было лишь добавить соответствие протоколу; никаких других изменений не потребовалось.
Благодаря этому мы теперь можем легко преобразовать книгу в объект JSON:
do {
let book = Book(title: "The Hitchhiker's Guide to the Galaxy",
numberOfPages: 816,
author: "Douglas Adams")
let encoder = JSONEncoder()
let data = try encoder.encode(book)
}
catch {
print("Error when trying to encode book: \(error)")
}
Декодирование JSON-объекта в экземпляр Book осуществляется следующим образом:
let decoder = JSONDecoder()
let data = /* fetch data from the network */
let decodedBook = try decoder.decode(Book.self, from: data)
Преобразование типов в простые и промежуточные типы в документах Cloud Firestore с помощью Codable
Cloud Firestore поддерживает широкий набор типов данных, от простых строк до вложенных карт. Большинство из них напрямую соответствуют встроенным типам Swift. Давайте сначала рассмотрим сопоставление простых типов данных, прежде чем переходить к более сложным.
Чтобы сопоставить документы Cloud Firestore с типами Swift, выполните следующие шаги:
- Убедитесь, что вы добавили фреймворк
FirebaseFirestoreв свой проект. Для этого можно использовать либо Swift Package Manager, либо CocoaPods . - Импортируйте
FirebaseFirestoreв свой Swift-файл. - Приведите свой текст в соответствие с
Codable. - (Необязательно, если вы хотите использовать этот тип в представлении
List) Добавьте свойствоidк вашему типу и используйте@DocumentID, чтобы указать Cloud Firestore сопоставить его с идентификатором документа. Мы обсудим это подробнее ниже. - Используйте
documentReference.data(as: )для сопоставления ссылки на документ с типом Swift. - Используйте
documentReference.setData(from: )для сопоставления данных из типов Swift с документом Cloud Firestore . - (Необязательно, но настоятельно рекомендуется) Внедрить надлежащую обработку ошибок.
Давайте обновим наш тип Book соответствующим образом:
struct Book: Codable {
@DocumentID var id: String?
var title: String
var numberOfPages: Int
var author: String
}
Поскольку этот тип уже был пригоден для кодирования, нам оставалось только добавить свойство id и аннотировать его с помощью обертки свойства @DocumentID .
Взяв за основу предыдущий фрагмент кода для получения и сопоставления документа, мы можем заменить весь код ручного сопоставления одной строкой:
func fetchBook(documentId: String) {
let docRef = db.collection("books").document(documentId)
docRef.getDocument { document, error in
if let error = error as NSError? {
self.errorMessage = "Error getting document: \(error.localizedDescription)"
}
else {
if let document = document {
do {
self.book = try document.data(as: Book.self)
}
catch {
print(error)
}
}
}
}
}
Это можно записать ещё более лаконично, указав тип документа при вызове getDocument(as:) . Это выполнит сопоставление и вернёт объект типа Result , содержащий сопоставленный документ, или ошибку в случае сбоя декодирования:
private func fetchBook(documentId: String) {
let docRef = db.collection("books").document(documentId)
docRef.getDocument(as: Book.self) { result in
switch result {
case .success(let book):
// A Book value was successfully initialized from the DocumentSnapshot.
self.book = book
self.errorMessage = nil
case .failure(let error):
// A Book value could not be initialized from the DocumentSnapshot.
self.errorMessage = "Error decoding document: \(error.localizedDescription)"
}
}
}
Обновление существующего документа осуществляется очень просто: достаточно вызвать метод documentReference.setData(from: ) . Вот код для сохранения экземпляра Book , включающий базовую обработку ошибок:
func updateBook(book: Book) {
if let id = book.id {
let docRef = db.collection("books").document(id)
do {
try docRef.setData(from: book)
}
catch {
print(error)
}
}
}
При добавлении нового документа Cloud Firestore автоматически присваивает ему новый идентификатор. Это работает даже в автономном режиме.
func addBook(book: Book) {
let collectionRef = db.collection("books")
do {
let newDocReference = try collectionRef.addDocument(from: self.book)
print("Book stored with new document reference: \(newDocReference)")
}
catch {
print(error)
}
}
Помимо сопоставления простых типов данных, Cloud Firestore поддерживает ряд других типов данных, некоторые из которых являются структурированными типами, которые можно использовать для создания вложенных объектов внутри документа.
Вложенные пользовательские типы
Большинство атрибутов, которые мы хотим отобразить в наших документах, представляют собой простые значения, такие как название книги или имя автора. Но как быть в тех случаях, когда нам нужно хранить более сложный объект? Например, нам может потребоваться сохранить URL-адреса обложки книги в разных разрешениях.
Простейший способ сделать это в Cloud Firestore — использовать карту:

При написании соответствующей структуры Swift мы можем воспользоваться тем фактом, что Cloud Firestore поддерживает URL-адреса — при сохранении поля, содержащего URL-адрес, он будет преобразован в строку и наоборот:
struct CoverImages: Codable {
var small: URL
var medium: URL
var large: URL
}
struct BookWithCoverImages: Codable {
@DocumentID var id: String?
var title: String
var numberOfPages: Int
var author: String
var cover: CoverImages?
}
Обратите внимание, как мы определили структуру CoverImages для карты обложек в документе Cloud Firestore . Указав свойство cover в BookWithCoverImages как необязательное, мы можем обработать тот факт, что некоторые документы могут не содержать атрибута cover.
Если вам интересно, почему нет фрагмента кода для получения или обновления данных, вы будете рады узнать, что нет необходимости изменять код для чтения или записи из/в Cloud Firestore : все это работает с кодом, который мы написали в начальном разделе.
Массивы
Иногда нам нужно хранить в документе набор значений. Хорошим примером являются жанры книг: такая книга, как «Автостопом по Галактике», может относиться к нескольким категориям — в данном случае «Научная фантастика» и «Комедия»:

В Cloud Firestore мы можем смоделировать это с помощью массива значений. Это поддерживается для любого типа данных (например, String , Int и т. д.). Ниже показано, как добавить массив жанров в нашу модель Book :
public struct BookWithGenre: Codable {
@DocumentID var id: String?
var title: String
var numberOfPages: Int
var author: String
var genres: [String]
}
Поскольку это работает для любого типа данных, допускающего кодирование, мы можем использовать и пользовательские типы. Представьте, что мы хотим хранить список тегов для каждой книги. Наряду с названием тега, мы хотели бы хранить и цвет тега, вот так:
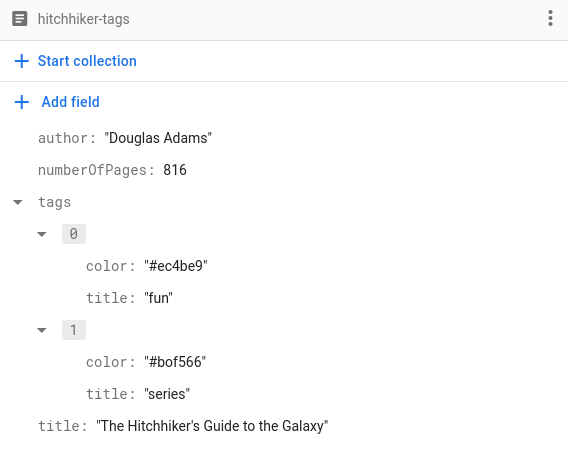
Для хранения тегов таким способом нам достаточно реализовать структуру Tag , представляющую тег, и сделать её пригодной для кодирования:
struct Tag: Codable, Hashable {
var title: String
var color: String
}
И вот так мы можем хранить массив Tags в наших документах Book !
struct BookWithTags: Codable {
@DocumentID var id: String?
var title: String
var numberOfPages: Int
var author: String
var tags: [Tag]
}
Несколько слов о сопоставлении идентификаторов документов.
Прежде чем перейти к сопоставлению других типов, давайте на мгновение поговорим о сопоставлении идентификаторов документов.
В некоторых предыдущих примерах мы использовали обертку свойства @DocumentID для сопоставления идентификатора документа в Cloud Firestore со свойством id наших типов Swift. Это важно по ряду причин:
- Это помогает нам понять, какой документ следует обновить в случае, если пользователь внесет локальные изменения.
- В SwiftUI для элементов
Listтребуется, чтобы они былиIdentifiable, чтобы предотвратить их перемещение при добавлении.
Стоит отметить, что атрибут, помеченный как @DocumentID не будет закодирован кодировщиком Cloud Firestore при записи документа обратно. Это связано с тем, что идентификатор документа не является атрибутом самого документа — поэтому запись его в документ была бы ошибкой.
При работе с вложенными типами (например, массивом тегов в примере с Book , приведенном ранее в этом руководстве) добавлять свойство @DocumentID не требуется: вложенные свойства являются частью документа Cloud Firestore и не представляют собой отдельный документ. Следовательно, им не нужен идентификатор документа.
Даты и время
Cloud Firestore есть встроенный тип данных для обработки дат и времени, и благодаря поддержке Codable в Cloud Firestore , использовать их очень просто.
Давайте взглянем на этот документ, представляющий собой прародительницу всех языков программирования, язык Ада, изобретенный в 1843 году:

Тип данных в Swift для сопоставления этого документа может выглядеть следующим образом:
struct ProgrammingLanguage: Codable {
@DocumentID var id: String?
var name: String
var year: Date
}
Мы не можем обойти стороной этот раздел о датах и времени, не упомянув @ServerTimestamp . Этот обертка для свойства — настоящий инструмент для работы с временными метками в вашем приложении.
В любой распределенной системе существует вероятность того, что часы на отдельных системах не всегда полностью синхронизированы. Вам может показаться, что это не имеет большого значения, но представьте себе последствия небольшого рассинхронизации часов для системы биржевой торговли: даже отклонение на миллисекунду может привести к разнице в миллионы долларов при совершении сделки.
Cloud Firestore обрабатывает атрибуты, помеченные аннотацией @ServerTimestamp следующим образом: если атрибут равен nil при сохранении (например, с помощью addDocument() ), Cloud Firestore заполнит поле текущей меткой времени сервера на момент записи в базу данных. Если поле не nil при вызове addDocument() или updateData() , Cloud Firestore оставит значение атрибута без изменений. Таким образом, легко реализовать поля типа createdAt и lastUpdatedAt .
Геоточки
Геолокация повсеместно используется в наших приложениях. Благодаря её хранению становится возможным множество интересных функций. Например, может быть полезно сохранить местоположение для выполнения задачи, чтобы приложение могло напомнить вам о ней, когда вы достигнете пункта назначения.
Cloud Firestore есть встроенный тип данных GeoPoint , который может хранить долготу и широту любого местоположения. Для сопоставления местоположений с документом Cloud Firestore можно использовать тип GeoPoint :
struct Office: Codable {
@DocumentID var id: String?
var name: String
var location: GeoPoint
}
Соответствующий тип в Swift — CLLocationCoordinate2D , и мы можем сопоставлять эти два типа с помощью следующей операции:
CLLocationCoordinate2D(latitude: office.location.latitude,
longitude: office.location.longitude)
Чтобы узнать больше о запросах к документам по физическому местоположению, ознакомьтесь с этим руководством по решению .
Перечисления
Перечисления (enums) — пожалуй, одна из самых недооцененных языковых возможностей Swift; в них гораздо больше, чем кажется на первый взгляд. Распространенный вариант использования перечислений — моделирование дискретных состояний чего-либо. Например, мы можем писать приложение для управления статьями. Для отслеживания статуса статьи мы можем использовать перечисление Status :
enum Status: String, Codable {
case draft
case inReview
case approved
case published
}
Cloud Firestore не поддерживает перечисления (т.е. не может принудительно задать набор значений), но мы все равно можем использовать тот факт, что перечисления могут быть типизированы, и выбрать тип, допускающий кодирование. В этом примере мы выбрали String , что означает, что все значения перечисления будут сопоставляться со строками при хранении в документе Cloud Firestore .
А поскольку Swift поддерживает пользовательские необработанные значения, мы можем даже настроить, какие значения относятся к какому варианту перечисления. Например, если мы решим хранить вариант Status.inReview как "в процессе проверки", мы можем просто обновить указанное выше перечисление следующим образом:
enum Status: String, Codable {
case draft
case inReview = "in review"
case approved
case published
}
Настройка сопоставления
Иногда имена атрибутов документов Cloud Firestore , которые мы хотим сопоставить, не совпадают с именами свойств в нашей модели данных в Swift. Например, один из наших коллег может быть разработчиком на Python и решить использовать snake_case для всех имен своих атрибутов.
Не беспокойтесь: Codable позаботится обо всем!
В подобных случаях мы можем использовать CodingKeys . Это перечисление, которое можно добавить к структуре, допускающей кодирование, чтобы указать, как будут сопоставляться определенные атрибуты.
Ознакомьтесь с этим документом:

Чтобы сопоставить этот документ со структурой, имеющей свойство name типа String , нам необходимо добавить перечисление CodingKeys в структуру ProgrammingLanguage и указать имя атрибута в документе:
struct ProgrammingLanguage: Codable {
@DocumentID var id: String?
var name: String
var year: Date
enum CodingKeys: String, CodingKey {
case id
case name = "language_name"
case year
}
}
По умолчанию API Codable использует имена свойств наших типов Swift для определения имен атрибутов в документах Cloud Firestore , которые мы пытаемся сопоставить. Поэтому, пока имена атрибутов совпадают, нет необходимости добавлять CodingKeys к нашим типам Codable. Однако, как только мы используем CodingKeys для конкретного типа, нам необходимо добавить все имена свойств, которые мы хотим сопоставить.
В приведенном выше фрагменте кода мы определили свойство id , которое, возможно, захотим использовать в качестве идентификатора в представлении List SwiftUI. Если бы мы не указали его в CodingKeys , оно не было бы сопоставлено при получении данных и, следовательно, стало бы nil . В результате представление List было бы заполнено первым документом.
Любое свойство, не указанное в качестве варианта в соответствующем перечислении CodingKeys будет игнорироваться в процессе сопоставления. Это может быть удобно, если мы хотим специально исключить некоторые свойства из процесса сопоставления.
Например, если мы хотим исключить свойство reasonWhyILoveThis из списка используемых свойств, нам достаточно удалить его из перечисления CodingKeys :
struct ProgrammingLanguage: Identifiable, Codable {
@DocumentID var id: String?
var name: String
var year: Date
var reasonWhyILoveThis: String = ""
enum CodingKeys: String, CodingKey {
case id
case name = "language_name"
case year
}
}
Иногда нам может потребоваться записать пустой атрибут обратно в документ Cloud Firestore . В Swift существует понятие опционалов для обозначения отсутствия значения, и Cloud Firestore также поддерживает значения null . Однако поведение по умолчанию при кодировании опционалов со значением nil — просто опускать их. Аннотация @ExplicitNull дает нам некоторый контроль над тем, как обрабатываются опционалы в Swift при их кодировании: пометив опциональное свойство как @ExplicitNull , мы можем указать Cloud Firestore записать это свойство в документ со значением null, если оно содержит значение nil .
Использование пользовательского кодировщика и декодера для сопоставления цветов.
В качестве заключительной темы нашего обзора сопоставления данных с помощью Codable, давайте познакомимся с пользовательскими кодировщиками и декодерами. В этом разделе не рассматривается собственный тип данных Cloud Firestore , но пользовательские кодировщики и декодеры очень полезны в ваших приложениях Cloud Firestore .
«Как сопоставить цвета?» — один из наиболее часто задаваемых вопросов разработчиков, не только по Cloud Firestore , но и по сопоставлению данных между Swift и JSON. Существует множество решений, но большинство из них ориентированы на JSON, и почти все они сопоставляют цвета как вложенный словарь, состоящий из его RGB-компонентов.
Кажется, должно быть более простое и удобное решение. Почему бы нам не использовать веб-цвета (или, точнее, шестнадцатеричную кодировку цветов в CSS) — они просты в использовании (по сути, это просто строка) и даже поддерживают прозрачность!
Чтобы сопоставить Color Swift с его шестнадцатеричным значением, нам нужно создать расширение Swift, которое добавит Codable к Color .
extension Color {
init(hex: String) {
let rgba = hex.toRGBA()
self.init(.sRGB,
red: Double(rgba.r),
green: Double(rgba.g),
blue: Double(rgba.b),
opacity: Double(rgba.alpha))
}
//... (code for translating between hex and RGBA omitted for brevity)
}
extension Color: Codable {
public init(from decoder: Decoder) throws {
let container = try decoder.singleValueContainer()
let hex = try container.decode(String.self)
self.init(hex: hex)
}
public func encode(to encoder: Encoder) throws {
var container = encoder.singleValueContainer()
try container.encode(toHex)
}
}
Используя decoder.singleValueContainer() , мы можем декодировать String в её Color эквивалент, не прибегая к вложенным компонентам RGBA. Кроме того, вы можете использовать эти значения в веб-интерфейсе вашего приложения, не выполняя предварительного преобразования!
Благодаря этому мы можем обновить код для сопоставления тегов, упростив обработку цветов тегов напрямую, вместо того чтобы сопоставлять их вручную в коде пользовательского интерфейса нашего приложения:
struct Tag: Codable, Hashable {
var title: String
var color: Color
}
struct BookWithTags: Codable {
@DocumentID var id: String?
var title: String
var numberOfPages: Int
var author: String
var tags: [Tag]
}
Обработка ошибок
В приведенных выше фрагментах кода мы намеренно свели обработку ошибок к минимуму, но в рабочем приложении вам потребуется обеспечить корректную обработку любых ошибок.
Вот фрагмент кода, демонстрирующий, как обрабатывать любые возможные ошибки:
class MappingSimpleTypesViewModel: ObservableObject {
@Published var book: Book = .empty
@Published var errorMessage: String?
private var db = Firestore.firestore()
func fetchAndMap() {
fetchBook(documentId: "hitchhiker")
}
func fetchAndMapNonExisting() {
fetchBook(documentId: "does-not-exist")
}
func fetchAndTryMappingInvalidData() {
fetchBook(documentId: "invalid-data")
}
private func fetchBook(documentId: String) {
let docRef = db.collection("books").document(documentId)
docRef.getDocument(as: Book.self) { result in
switch result {
case .success(let book):
// A Book value was successfully initialized from the DocumentSnapshot.
self.book = book
self.errorMessage = nil
case .failure(let error):
// A Book value could not be initialized from the DocumentSnapshot.
switch error {
case DecodingError.typeMismatch(_, let context):
self.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.valueNotFound(_, let context):
self.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.keyNotFound(_, let context):
self.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.dataCorrupted(let key):
self.errorMessage = "\(error.localizedDescription): \(key)"
default:
self.errorMessage = "Error decoding document: \(error.localizedDescription)"
}
}
}
}
}
Обработка ошибок в обновлениях в реальном времени
Приведенный выше фрагмент кода демонстрирует, как обрабатывать ошибки при получении одного документа. Помимо однократной загрузки данных, Cloud Firestore также поддерживает доставку обновлений в ваше приложение по мере их возникновения, используя так называемые обработчики снимков: мы можем зарегистрировать обработчик снимка для коллекции (или запроса), и Cloud Firestore будет вызывать наш обработчик всякий раз, когда происходит обновление.
Вот фрагмент кода, демонстрирующий, как зарегистрировать обработчик снимков, сопоставить данные с помощью Codable и обработать любые возможные ошибки. Он также показывает, как добавить новый документ в коллекцию. Как вы увидите, нет необходимости самостоятельно обновлять локальный массив, содержащий сопоставленные документы, поскольку это делается кодом в обработчике снимков.
class MappingColorsViewModel: ObservableObject {
@Published var colorEntries = [ColorEntry]()
@Published var newColor = ColorEntry.empty
@Published var errorMessage: String?
private var db = Firestore.firestore()
private var listenerRegistration: ListenerRegistration?
public func unsubscribe() {
if listenerRegistration != nil {
listenerRegistration?.remove()
listenerRegistration = nil
}
}
func subscribe() {
if listenerRegistration == nil {
listenerRegistration = db.collection("colors")
.addSnapshotListener { [weak self] (querySnapshot, error) in
guard let documents = querySnapshot?.documents else {
self?.errorMessage = "No documents in 'colors' collection"
return
}
self?.colorEntries = documents.compactMap { queryDocumentSnapshot in
let result = Result { try queryDocumentSnapshot.data(as: ColorEntry.self) }
switch result {
case .success(let colorEntry):
if let colorEntry = colorEntry {
// A ColorEntry value was successfully initialized from the DocumentSnapshot.
self?.errorMessage = nil
return colorEntry
}
else {
// A nil value was successfully initialized from the DocumentSnapshot,
// or the DocumentSnapshot was nil.
self?.errorMessage = "Document doesn't exist."
return nil
}
case .failure(let error):
// A ColorEntry value could not be initialized from the DocumentSnapshot.
switch error {
case DecodingError.typeMismatch(_, let context):
self?.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.valueNotFound(_, let context):
self?.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.keyNotFound(_, let context):
self?.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.dataCorrupted(let key):
self?.errorMessage = "\(error.localizedDescription): \(key)"
default:
self?.errorMessage = "Error decoding document: \(error.localizedDescription)"
}
return nil
}
}
}
}
}
func addColorEntry() {
let collectionRef = db.collection("colors")
do {
let newDocReference = try collectionRef.addDocument(from: newColor)
print("ColorEntry stored with new document reference: \(newDocReference)")
}
catch {
print(error)
}
}
}
Все фрагменты кода, использованные в этом посте, являются частью примера приложения, которое вы можете скачать из этого репозитория GitHub .
Вперед, используйте Codable!
API Codable в Swift предоставляет мощный и гибкий способ сопоставления данных из сериализованных форматов с моделью данных вашего приложения и обратно. В этом руководстве вы увидели, насколько легко его использовать в приложениях, использующих Cloud Firestore в качестве хранилища данных.
Начав с простого примера с базовыми типами данных, мы постепенно увеличивали сложность модели данных, при этом полагаясь на реализацию Codable и Firebase для выполнения сопоставления данных.
Для получения более подробной информации о Codable я рекомендую следующие ресурсы:
- У Джона Санделла есть отличная статья об основах Codable .
- Если вам больше по душе книги, обратите внимание на руководство Мэтта по Swift Codable от Flight School .
- И наконец, у Донни Уолса есть целая серия статей о Codable .
Хотя мы постарались составить исчерпывающее руководство по сопоставлению документов Cloud Firestore , оно не является полным, и вы можете использовать другие стратегии для сопоставления ваших типов. Используя кнопку «Отправить отзыв» ниже, сообщите нам, какие стратегии вы используете для сопоставления других типов данных Cloud Firestore или для представления данных в Swift.
На самом деле нет никаких причин не использовать поддержку Codable в Cloud Firestore .