
সুইফট ৪-এ প্রবর্তিত সুইফটের কোডেবল এপিআই, কম্পাইলারের শক্তিকে কাজে লাগিয়ে সিরিয়ালাইজড ফরম্যাট থেকে সুইফট টাইপে ডেটা ম্যাপ করাকে আরও সহজ করে তোলে।
আপনি হয়তো একটি ওয়েব এপিআই থেকে আপনার অ্যাপের ডেটা মডেলে (এবং এর বিপরীতে) ডেটা ম্যাপ করার জন্য কোডেবল ব্যবহার করে আসছেন, কিন্তু এটি তার চেয়েও অনেক বেশি নমনীয়।
এই নির্দেশিকায় আমরা দেখব, কীভাবে কোডেবল ব্যবহার করে Cloud Firestore থেকে সুইফট টাইপে এবং সুইফট টাইপ থেকে ক্লাউড ফায়ারস্টোরে ডেটা ম্যাপ করা যায়।
Cloud Firestore থেকে কোনো ডকুমেন্ট আনার সময়, আপনার অ্যাপ কী/ভ্যালু জোড়ের একটি ডিকশনারি পাবে (অথবা ডিকশনারির একটি অ্যারে পাবে, যদি আপনি একাধিক ডকুমেন্ট ফেরত দেয় এমন কোনো অপারেশন ব্যবহার করেন)।
এখন, আপনি অবশ্যই সুইফটে সরাসরি ডিকশনারি ব্যবহার করা চালিয়ে যেতে পারেন, এবং এগুলো এমন কিছু দারুণ নমনীয়তা প্রদান করে যা আপনার ব্যবহারের ক্ষেত্রে একেবারে উপযুক্ত হতে পারে। তবে, এই পদ্ধতিটি টাইপ-সেফ নয় এবং অ্যাট্রিবিউটের নাম ভুল বানান করার মাধ্যমে, অথবা গত সপ্তাহে আপনার টিম যখন সেই আকর্ষণীয় নতুন ফিচারটি প্রকাশ করেছিল তখন যোগ করা নতুন অ্যাট্রিবিউটটি ম্যাপ করতে ভুলে যাওয়ার মাধ্যমে এমন বাগ তৈরি করা সহজ, যা খুঁজে বের করা কঠিন।
অতীতে, অনেক ডেভেলপার একটি সাধারণ ম্যাপিং লেয়ার প্রয়োগ করে এই সীমাবদ্ধতাগুলো কাটিয়ে উঠেছেন, যা তাদের ডিকশনারিগুলোকে সুইফট টাইপের সাথে ম্যাপ করার সুযোগ দিত। কিন্তু আবারও, এই বাস্তবায়নগুলোর বেশিরভাগই Cloud Firestore ডকুমেন্ট এবং আপনার অ্যাপের ডেটা মডেলের সংশ্লিষ্ট টাইপগুলোর মধ্যে ম্যাপিং ম্যানুয়ালি নির্দিষ্ট করার উপর ভিত্তি করে তৈরি।
Cloud Firestore সুইফটের কোডেবল এপিআই (Codable API) সমর্থিত হওয়ায়, এই কাজটি অনেক সহজ হয়ে যায়:
- আপনাকে আর ম্যানুয়ালি কোনো ম্যাপিং কোড প্রয়োগ করতে হবে না।
- ভিন্ন নামের অ্যাট্রিবিউটগুলোকে কীভাবে ম্যাপ করতে হবে তা নির্ধারণ করা সহজ।
- এতে সুইফটের অনেক ধরনের টাইপের জন্য অন্তর্নির্মিত সমর্থন রয়েছে।
- এবং কাস্টম টাইপ ম্যাপিংয়ের জন্য সমর্থন যোগ করা সহজ।
- সবচেয়ে ভালো ব্যাপার হলো: সাধারণ ডেটা মডেলের জন্য আপনাকে কোনো ম্যাপিং কোডই লিখতে হবে না।
ম্যাপিং ডেটা
Cloud Firestore ডেটা ডকুমেন্টে সংরক্ষণ করে, যেখানে কী-এর সাথে ভ্যালু ম্যাপ করা থাকে। কোনো একটি নির্দিষ্ট ডকুমেন্ট থেকে ডেটা আনার জন্য, আমরা DocumentSnapshot.data() কল করতে পারি, যা ফিল্ডের নামগুলোকে একটি Any সাথে ম্যাপ করে একটি ডিকশনারি রিটার্ন করে: func data() -> [String : Any]? ।
এর মানে হলো, আমরা সুইফটের সাবস্ক্রিপ্ট সিনট্যাক্স ব্যবহার করে প্রতিটি স্বতন্ত্র ফিল্ড অ্যাক্সেস করতে পারি।
import FirebaseFirestore
#warning("DO NOT MAP YOUR DOCUMENTS MANUALLY. USE CODABLE INSTEAD.")
func fetchBook(documentId: String) {
let docRef = db.collection("books").document(documentId)
docRef.getDocument { document, error in
if let error = error as NSError? {
self.errorMessage = "Error getting document: \(error.localizedDescription)"
}
else {
if let document = document {
let id = document.documentID
let data = document.data()
let title = data?["title"] as? String ?? ""
let numberOfPages = data?["numberOfPages"] as? Int ?? 0
let author = data?["author"] as? String ?? ""
self.book = Book(id:id, title: title, numberOfPages: numberOfPages, author: author)
}
}
}
}
যদিও এটি সহজবোধ্য এবং প্রয়োগ করা সহজ মনে হতে পারে, এই কোডটি ভঙ্গুর, রক্ষণাবেক্ষণ করা কঠিন এবং ত্রুটিপ্রবণ।
যেমনটা দেখতে পাচ্ছেন, আমরা ডকুমেন্ট ফিল্ডগুলোর ডেটা টাইপ সম্পর্কে কিছু অনুমান করে নিচ্ছি। এগুলো সঠিক হতেও পারে, আবার নাও হতে পারে।
মনে রাখবেন, যেহেতু কোনো স্কিমা নেই, আপনি সহজেই কালেকশনে একটি নতুন ডকুমেন্ট যোগ করতে পারেন এবং কোনো ফিল্ডের জন্য ভিন্ন টাইপ বেছে নিতে পারেন। আপনি হয়তো ভুলবশত numberOfPages ফিল্ডের জন্য স্ট্রিং বেছে নিতে পারেন, যার ফলে এমন একটি ম্যাপিং সমস্যা তৈরি হবে যা খুঁজে বের করা কঠিন হবে। এছাড়াও, যখনই কোনো নতুন ফিল্ড যোগ করা হবে, আপনাকে আপনার ম্যাপিং কোড আপডেট করতে হবে, যা বেশ ঝামেলার।
আর এটাও ভুলে গেলে চলবে না যে, আমরা সুইফটের শক্তিশালী টাইপ সিস্টেমের সুবিধা নিচ্ছি না, যা Book এর প্রতিটি প্রপার্টির জন্য একেবারে সঠিক টাইপটি জানে।
যাইহোক, কোডেবল (Codable) জিনিসটা কী?
অ্যাপলের ডকুমেন্টেশন অনুসারে, Codable হলো "এমন একটি টাইপ যা নিজেকে একটি বাহ্যিক উপস্থাপনায় রূপান্তর করতে এবং তা থেকে বেরিয়ে আসতে পারে।" প্রকৃতপক্ষে, Codable হলো Encodable এবং Decodable প্রোটোকলের একটি টাইপ অ্যালিয়াস। একটি সুইফট টাইপকে এই প্রোটোকলের সাথে সঙ্গতিপূর্ণ করার মাধ্যমে, কম্পাইলার JSON-এর মতো একটি সিরিয়ালাইজড ফরম্যাট থেকে এই টাইপের একটি ইনস্ট্যান্সকে এনকোড/ডিকোড করার জন্য প্রয়োজনীয় কোড সিন্থেসাইজ করবে।
একটি বই সম্পর্কিত ডেটা সংরক্ষণের একটি সহজ ধরন দেখতে এইরকম হতে পারে:
struct Book: Codable {
var title: String
var numberOfPages: Int
var author: String
}
যেমনটি দেখতে পাচ্ছেন, কোডেবল-এর সাথে টাইপটি সামঞ্জস্যপূর্ণ করা খুবই সহজ একটি প্রক্রিয়া। আমাদের শুধু প্রোটোকলে এই সামঞ্জস্যটি যোগ করতে হয়েছিল; অন্য কোনো পরিবর্তনের প্রয়োজন হয়নি।
এর ফলে, আমরা এখন সহজেই একটি বইকে JSON অবজেক্টে এনকোড করতে পারি:
do {
let book = Book(title: "The Hitchhiker's Guide to the Galaxy",
numberOfPages: 816,
author: "Douglas Adams")
let encoder = JSONEncoder()
let data = try encoder.encode(book)
}
catch {
print("Error when trying to encode book: \(error)")
}
একটি JSON অবজেক্টকে Book ইনস্ট্যান্সে ডিকোড করার প্রক্রিয়াটি নিম্নরূপ:
let decoder = JSONDecoder()
let data = /* fetch data from the network */
let decodedBook = try decoder.decode(Book.self, from: data)
কোডেবল ব্যবহার করে Cloud Firestore ডকুমেন্টে সিম্পল টাইপের সাথে ম্যাপিং করা
Cloud Firestore সাধারণ স্ট্রিং থেকে শুরু করে নেস্টেড ম্যাপ পর্যন্ত বিস্তৃত পরিসরের ডেটা টাইপ সমর্থন করে। এগুলোর বেশিরভাগই সুইফটের বিল্ট-ইন টাইপগুলোর সাথে সরাসরি মিলে যায়। আরও জটিল ডেটা টাইপগুলোতে যাওয়ার আগে, চলুন প্রথমে কিছু সাধারণ ডেটা টাইপের ম্যাপিং দেখে নেওয়া যাক।
Cloud Firestore ডকুমেন্টগুলোকে সুইফট টাইপের সাথে ম্যাপ করতে, এই ধাপগুলো অনুসরণ করুন:
- আপনার প্রজেক্টে
FirebaseFirestoreফ্রেমওয়ার্কটি যুক্ত করা হয়েছে কিনা তা নিশ্চিত করুন। এই কাজটি করার জন্য আপনি Swift Package Manager অথবা CocoaPods ব্যবহার করতে পারেন। - আপনার Swift ফাইলে
FirebaseFirestoreইম্পোর্ট করুন। - আপনার টাইপটি
Codableসাথে সামঞ্জস্যপূর্ণ করুন। - (ঐচ্ছিক, যদি আপনি
Listভিউতে টাইপটি ব্যবহার করতে চান) আপনার টাইপে একটিidপ্রপার্টি যোগ করুন, এবং Cloud Firestore ডকুমেন্ট আইডির সাথে এটি ম্যাপ করতে বলার জন্য@DocumentIDব্যবহার করুন। আমরা নিচে এ বিষয়ে আরও বিস্তারিত আলোচনা করব। - একটি ডকুমেন্ট রেফারেন্সকে সুইফট টাইপের সাথে ম্যাপ করতে
documentReference.data(as: )ব্যবহার করুন। - সুইফট টাইপ থেকে Cloud Firestore ডকুমেন্টে ডেটা ম্যাপ করতে
documentReference.setData(from: )ব্যবহার করুন। - (ঐচ্ছিক, তবে অত্যন্ত সুপারিশকৃত) যথাযথ ত্রুটি ব্যবস্থাপনা প্রয়োগ করুন।
চলুন সেই অনুযায়ী আমাদের Book ধরন আপডেট করি:
struct Book: Codable {
@DocumentID var id: String?
var title: String
var numberOfPages: Int
var author: String
}
যেহেতু এই টাইপটি আগে থেকেই কোডযোগ্য ছিল, তাই আমাদের শুধু id প্রপার্টিটি যোগ করতে হয়েছিল এবং এটিকে @DocumentID প্রপার্টি র্যাপার দিয়ে অ্যানোটেট করতে হয়েছিল।
ডকুমেন্ট ফেচ এবং ম্যাপ করার জন্য আগের কোড স্নিপেটটি ব্যবহার করে, আমরা সমস্ত ম্যানুয়াল ম্যাপিং কোড একটি মাত্র লাইন দিয়ে প্রতিস্থাপন করতে পারি:
func fetchBook(documentId: String) {
let docRef = db.collection("books").document(documentId)
docRef.getDocument { document, error in
if let error = error as NSError? {
self.errorMessage = "Error getting document: \(error.localizedDescription)"
}
else {
if let document = document {
do {
self.book = try document.data(as: Book.self)
}
catch {
print(error)
}
}
}
}
}
getDocument(as:) কল করার সময় ডকুমেন্টের টাইপ উল্লেখ করে আপনি এটি আরও সংক্ষিপ্তভাবে লিখতে পারেন। এটি আপনার জন্য ম্যাপিংটি সম্পাদন করবে এবং ম্যাপ করা ডকুমেন্ট সম্বলিত একটি Result টাইপ রিটার্ন করবে, অথবা ডিকোডিং ব্যর্থ হলে একটি এরর রিটার্ন করবে।
private func fetchBook(documentId: String) {
let docRef = db.collection("books").document(documentId)
docRef.getDocument(as: Book.self) { result in
switch result {
case .success(let book):
// A Book value was successfully initialized from the DocumentSnapshot.
self.book = book
self.errorMessage = nil
case .failure(let error):
// A Book value could not be initialized from the DocumentSnapshot.
self.errorMessage = "Error decoding document: \(error.localizedDescription)"
}
}
}
বিদ্যমান কোনো ডকুমেন্ট আপডেট করা documentReference.setData(from: ) কল করার মতোই সহজ। কিছু প্রাথমিক ত্রুটি পরিচালনা সহ, একটি Book ইনস্ট্যান্স সংরক্ষণ করার কোডটি নিচে দেওয়া হলো:
func updateBook(book: Book) {
if let id = book.id {
let docRef = db.collection("books").document(id)
do {
try docRef.setData(from: book)
}
catch {
print(error)
}
}
}
নতুন ডকুমেন্ট যোগ করার সময়, Cloud Firestore স্বয়ংক্রিয়ভাবে ডকুমেন্টটিতে একটি নতুন ডকুমেন্ট আইডি নির্ধারণ করে দেবে। অ্যাপটি অফলাইনে থাকলেও এটি কাজ করে।
func addBook(book: Book) {
let collectionRef = db.collection("books")
do {
let newDocReference = try collectionRef.addDocument(from: self.book)
print("Book stored with new document reference: \(newDocReference)")
}
catch {
print(error)
}
}
সাধারণ ডেটা টাইপ ম্যাপিং করার পাশাপাশি, Cloud Firestore আরও বেশ কিছু ডেটাটাইপ সমর্থন করে, যার মধ্যে কয়েকটি হলো স্ট্রাকচার্ড টাইপ, যা ব্যবহার করে একটি ডকুমেন্টের ভেতরে নেস্টেড অবজেক্ট তৈরি করা যায়।
নেস্টেড কাস্টম প্রকার
আমাদের ডকুমেন্টে আমরা যে অ্যাট্রিবিউটগুলো ম্যাপ করতে চাই, তার বেশিরভাগই সাধারণ ভ্যালু, যেমন বইয়ের শিরোনাম বা লেখকের নাম। কিন্তু এমন ক্ষেত্রে কী হবে যখন আমাদের আরও জটিল কোনো অবজেক্ট সংরক্ষণ করার প্রয়োজন হয়? উদাহরণস্বরূপ, আমরা হয়তো বইয়ের কভারের ইউআরএলগুলো বিভিন্ন রেজোলিউশনে সংরক্ষণ করতে চাইতে পারি।
Cloud Firestore এটি করার সবচেয়ে সহজ উপায় হলো একটি ম্যাপ ব্যবহার করা:

সংশ্লিষ্ট Swift struct লেখার সময়, আমরা এই সুবিধাটি নিতে পারি যে Cloud Firestore URL সমর্থন করে — যখন কোনো ফিল্ডে URL সংরক্ষণ করা হয়, তখন সেটি স্ট্রিং-এ রূপান্তরিত হবে এবং এর বিপরীতটিও ঘটবে:
struct CoverImages: Codable {
var small: URL
var medium: URL
var large: URL
}
struct BookWithCoverImages: Codable {
@DocumentID var id: String?
var title: String
var numberOfPages: Int
var author: String
var cover: CoverImages?
}
লক্ষ্য করুন, আমরা Cloud Firestore ডকুমেন্টের কভার ম্যাপের জন্য কীভাবে CoverImages নামে একটি স্ট্রাক্ট সংজ্ঞায়িত করেছি। BookWithCoverImages এর কভার প্রপার্টিকে ঐচ্ছিক (optional) হিসেবে চিহ্নিত করার মাধ্যমে, আমরা এই বিষয়টি সামলাতে পারি যে কিছু ডকুমেন্টে কভার অ্যাট্রিবিউট নাও থাকতে পারে।
ডেটা আনা বা আপডেট করার জন্য কেন কোনো কোড স্নিপেট নেই, তা জানতে যদি আপনার কৌতূহল থাকে, তবে আপনি জেনে খুশি হবেন যে Cloud Firestore থেকে ডেটা পড়া বা লেখার জন্য কোডে কোনো পরিবর্তনের প্রয়োজন নেই: এই সবকিছুই প্রাথমিক অংশে লেখা কোড দিয়েই কাজ করে।
অ্যারে
কখনও কখনও, আমরা একটি ডকুমেন্টে একাধিক মান সংরক্ষণ করতে চাই। একটি বইয়ের ধরণগুলো এর একটি ভালো উদাহরণ: ‘The Hitchhiker's Guide to the Galaxy’- এর মতো একটি বই বিভিন্ন শ্রেণীতে পড়তে পারে — এই ক্ষেত্রে "সাই-ফাই" এবং "কমেডি"।

Cloud Firestore , আমরা ভ্যালুর একটি অ্যারে ব্যবহার করে এটি মডেল করতে পারি। এটি যেকোনো কোডেবল টাইপের (যেমন String , Int , ইত্যাদি) জন্য সমর্থিত। নিচে দেখানো হলো কীভাবে আমাদের Book মডেলে জনরার একটি অ্যারে যোগ করতে হয়:
public struct BookWithGenre: Codable {
@DocumentID var id: String?
var title: String
var numberOfPages: Int
var author: String
var genres: [String]
}
যেহেতু এটি যেকোনো কোডেবল টাইপের জন্য কাজ করে, আমরা কাস্টম টাইপও ব্যবহার করতে পারি। ধরুন, আমরা প্রতিটি বইয়ের জন্য ট্যাগের একটি তালিকা সংরক্ষণ করতে চাই। ট্যাগের নামের পাশাপাশি, আমরা ট্যাগের রঙটিও সংরক্ষণ করতে চাই, ঠিক এইভাবে:
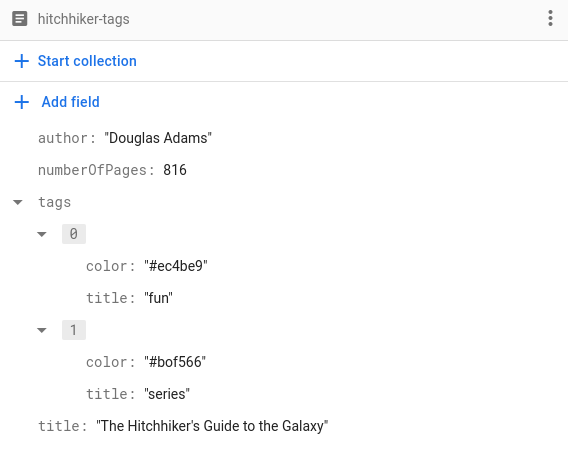
এইভাবে ট্যাগ সংরক্ষণ করার জন্য, আমাদের শুধু একটি ট্যাগকে উপস্থাপন করতে একটি Tag struct ইমপ্লিমেন্ট করতে হবে এবং এটিকে কোডেবল করে তুলতে হবে:
struct Tag: Codable, Hashable {
var title: String
var color: String
}
আর ঠিক এভাবেই আমরা আমাদের Book ডকুমেন্টগুলোতে Tags একটি অ্যারে সংরক্ষণ করতে পারি!
struct BookWithTags: Codable {
@DocumentID var id: String?
var title: String
var numberOfPages: Int
var author: String
var tags: [Tag]
}
ডকুমেন্ট আইডি ম্যাপিং সম্পর্কে একটি সংক্ষিপ্ত কথা।
আরও ধরনের ম্যাপিং-এ যাওয়ার আগে, চলুন কিছুক্ষণ ডকুমেন্ট আইডি ম্যাপিং নিয়ে আলোচনা করা যাক।
আমরা পূর্ববর্তী কিছু উদাহরণে আমাদের Cloud Firestore ডকুমেন্টগুলোর ডকুমেন্ট আইডিকে আমাদের সুইফট টাইপগুলোর id প্রপার্টির সাথে ম্যাপ করার জন্য @DocumentID প্রপার্টি র্যাপারটি ব্যবহার করেছি। এটি বিভিন্ন কারণে গুরুত্বপূর্ণ:
- ব্যবহারকারী স্থানীয়ভাবে কোনো পরিবর্তন করলে কোন ডকুমেন্টটি আপডেট করতে হবে, তা জানতে এটি আমাদের সাহায্য করে।
- SwiftUI-এর
Listথাকা উপাদানগুলোকেIdentifiableহতে হয়, যাতে সেগুলো যুক্ত করার সময় স্থান পরিবর্তন না করে।
এটা উল্লেখ করা প্রয়োজন যে, @DocumentID হিসেবে চিহ্নিত কোনো অ্যাট্রিবিউট ডকুমেন্টটি পুনরায় লেখার সময় Cloud Firestore এনকোডার দ্বারা এনকোড করা হবে না। এর কারণ হলো, ডকুমেন্ট আইডি ডকুমেন্টটির নিজের কোনো অ্যাট্রিবিউট নয় — তাই এটিকে ডকুমেন্টে লেখা একটি ভুল হবে।
নেস্টেড টাইপ নিয়ে কাজ করার সময় (যেমন এই গাইডের আগের একটি উদাহরণে Book এর ট্যাগগুলোর অ্যারে), @DocumentID প্রপার্টি যোগ করার প্রয়োজন নেই: নেস্টেড প্রপার্টিগুলো Cloud Firestore ডকুমেন্টেরই একটি অংশ এবং এগুলো কোনো পৃথক ডকুমেন্ট গঠন করে না। তাই, এগুলোর কোনো ডকুমেন্ট আইডির প্রয়োজন হয় না।
তারিখ এবং সময়
Cloud Firestore তারিখ এবং সময় পরিচালনার জন্য একটি অন্তর্নির্মিত ডেটা টাইপ রয়েছে, এবং Cloud Firestore কোডেবল (Codable) সমর্থনের কারণে, সেগুলি ব্যবহার করা খুবই সহজ।
আসুন এই নথিটি দেখি যা ১৮৪৩ সালে আবিষ্কৃত, সকল প্রোগ্রামিং ভাষার জননী অ্যাডা-কে উপস্থাপন করে:

এই ডকুমেন্টটি ম্যাপ করার জন্য একটি সুইফট টাইপ দেখতে এইরকম হতে পারে:
struct ProgrammingLanguage: Codable {
@DocumentID var id: String?
var name: String
var year: Date
}
@ServerTimestamp নিয়ে আলোচনা না করে আমরা তারিখ ও সময় সম্পর্কিত এই অংশটি শেষ করতে পারি না। আপনার অ্যাপে টাইমস্ট্যাম্প নিয়ে কাজ করার ক্ষেত্রে এই প্রপার্টি র্যাপারটি একটি অত্যন্ত শক্তিশালী হাতিয়ার।
যেকোনো ডিস্ট্রিবিউটেড সিস্টেমে, এমন সম্ভাবনা থাকে যে স্বতন্ত্র সিস্টেমগুলোর ঘড়িগুলো সব সময় পুরোপুরি সিঙ্কে থাকে না। আপনার মনে হতে পারে এটা কোনো বড় ব্যাপার নয়, কিন্তু একটি স্টক ট্রেড সিস্টেমের জন্য ঘড়ির সামান্য অসামঞ্জস্যের প্রভাব কল্পনা করুন: একটি ট্রেড সম্পাদনের সময় এমনকি এক মিলিসেকেন্ডের বিচ্যুতিও লক্ষ লক্ষ ডলারের পার্থক্য তৈরি করতে পারে।
Cloud Firestore @ServerTimestamp দিয়ে চিহ্নিত অ্যাট্রিবিউটগুলোকে নিম্নোক্তভাবে পরিচালনা করে: আপনি যখন অ্যাট্রিবিউটটি সংরক্ষণ করেন (উদাহরণস্বরূপ, addDocument() ব্যবহার করে), তখন যদি এটি nil থাকে, Cloud Firestore ডেটাবেসে লেখার সময়কার বর্তমান সার্ভার টাইমস্ট্যাম্প দিয়ে ফিল্ডটি পূরণ করে। আপনি যখন addDocument() বা updateData() কল করেন, তখন যদি ফিল্ডটি nil না থাকে, Cloud Firestore অ্যাট্রিবিউটের মান অপরিবর্তিত রাখে। এইভাবে, createdAt এবং lastUpdatedAt মতো ফিল্ডগুলো বাস্তবায়ন করা সহজ হয়।
জিওপয়েন্ট
আমাদের অ্যাপগুলোতে জিওলোকেশন বা ভৌগোলিক অবস্থান এখন সর্বত্রই বিদ্যমান। এগুলো সংরক্ষণ করার মাধ্যমে অনেক আকর্ষণীয় ফিচার সম্ভব হয়ে ওঠে। উদাহরণস্বরূপ, কোনো কাজের জন্য তার অবস্থান সংরক্ষণ করা উপকারী হতে পারে, যাতে আপনি গন্তব্যে পৌঁছালে আপনার অ্যাপ আপনাকে সেই কাজটি সম্পর্কে মনে করিয়ে দিতে পারে।
Cloud Firestore GeoPoint একটি বিল্ট-ইন ডেটা টাইপ রয়েছে, যা যেকোনো অবস্থানের দ্রাঘিমাংশ এবং অক্ষাংশ সংরক্ষণ করতে পারে। Cloud Firestore ডকুমেন্ট থেকে বা ডকুমেন্টে অবস্থান ম্যাপ করার জন্য, আমরা GeoPoint টাইপটি ব্যবহার করতে পারি:
struct Office: Codable {
@DocumentID var id: String?
var name: String
var location: GeoPoint
}
সুইফটে এর সংশ্লিষ্ট টাইপটি হলো CLLocationCoordinate2D , এবং আমরা নিম্নলিখিত অপারেশনটির মাধ্যমে এই দুটি টাইপের মধ্যে ম্যাপিং করতে পারি:
CLLocationCoordinate2D(latitude: office.location.latitude,
longitude: office.location.longitude)
ভৌতিক অবস্থান অনুযায়ী নথি অনুসন্ধান করার বিষয়ে আরও জানতে, এই সমাধান নির্দেশিকাটি দেখুন।
এনাম
সুইফটে এনাম (Enum) সম্ভবত সবচেয়ে কম আলোচিত ল্যাঙ্গুয়েজ ফিচারগুলোর মধ্যে একটি; আপাতদৃষ্টিতে যা মনে হয়, এর মধ্যে তার চেয়েও অনেক বেশি কিছু রয়েছে। এনামের একটি সাধারণ ব্যবহার হলো কোনো কিছুর স্বতন্ত্র অবস্থাগুলোকে মডেল করা। উদাহরণস্বরূপ, আমরা হয়তো আর্টিকেল পরিচালনার জন্য একটি অ্যাপ তৈরি করছি। একটি আর্টিকেলের স্ট্যাটাস ট্র্যাক করার জন্য, আমরা Status একটি এনাম ব্যবহার করতে চাইতে পারি।
enum Status: String, Codable {
case draft
case inReview
case approved
case published
}
Cloud Firestore স্বাভাবিকভাবে এনাম (enum) সমর্থন করে না (অর্থাৎ, এটি ভ্যালুগুলোর সেট প্রয়োগ করতে পারে না), কিন্তু আমরা এনামের টাইপযোগ্যতার সুবিধা নিতে পারি এবং একটি কোডেবল টাইপ বেছে নিতে পারি। এই উদাহরণে, আমরা String বেছে নিয়েছি, যার অর্থ হলো Cloud Firestore ডকুমেন্টে সংরক্ষণ করার সময় সমস্ত এনাম ভ্যালু স্ট্রিং-এ ম্যাপ করা হবে।
এবং, যেহেতু সুইফট কাস্টম র ভ্যালু (raw values) সমর্থন করে, আমরা এমনকি কাস্টমাইজও করতে পারি যে কোন ভ্যালু কোন এনাম কেসকে (enum case) নির্দেশ করবে। সুতরাং উদাহরণস্বরূপ, যদি আমরা Status.inReview কেসটিকে "in review" হিসাবে সংরক্ষণ করার সিদ্ধান্ত নিই, তাহলে আমরা উপরের এনামটিকে (enum) নিম্নরূপভাবে আপডেট করতে পারি:
enum Status: String, Codable {
case draft
case inReview = "in review"
case approved
case published
}
ম্যাপিং কাস্টমাইজ করা
কখনও কখনও, আমরা যে Cloud Firestore ডকুমেন্টগুলো ম্যাপ করতে চাই, সেগুলোর অ্যাট্রিবিউটের নামগুলো আমাদের সুইফট ডেটা মডেলের প্রপার্টির নামের সাথে মেলে না। উদাহরণস্বরূপ, আমাদের কোনো সহকর্মী হয়তো একজন পাইথন ডেভেলপার এবং তিনি তার সমস্ত অ্যাট্রিবিউটের নামের জন্য 'snake_case' ব্যবহার করার সিদ্ধান্ত নিয়েছেন।
চিন্তা করবেন না: কোডেবল আমাদের পাশে আছে!
এই ধরনের ক্ষেত্রে, আমরা CodingKeys ব্যবহার করতে পারি। এটি একটি enum যা আমরা একটি codable struct-এ যোগ করে নির্দিষ্ট করতে পারি যে বিশেষ অ্যাট্রিবিউটগুলো কীভাবে ম্যাপ করা হবে।
এই নথিটি বিবেচনা করুন:

এই ডকুমেন্টটিকে এমন একটি স্ট্রাক্টের সাথে ম্যাপ করতে, যার 'name' প্রপার্টির টাইপ String , আমাদেরকে ProgrammingLanguage স্ট্রাক্টে একটি CodingKeys enum যোগ করতে হবে এবং ডকুমেন্টে অ্যাট্রিবিউটের নামটি নির্দিষ্ট করে দিতে হবে:
struct ProgrammingLanguage: Codable {
@DocumentID var id: String?
var name: String
var year: Date
enum CodingKeys: String, CodingKey {
case id
case name = "language_name"
case year
}
}
ডিফল্টরূপে, কোডেবল এপিআই আমাদের সুইফট টাইপের প্রপার্টি নামগুলো ব্যবহার করে Cloud Firestore ডকুমেন্টের অ্যাট্রিবিউট নামগুলো নির্ধারণ করে, যেগুলোকে আমরা ম্যাপ করার চেষ্টা করছি। তাই যতক্ষণ অ্যাট্রিবিউট নামগুলো মিলে যায়, ততক্ষণ আমাদের কোডেবল টাইপগুলোতে CodingKeys যোগ করার কোনো প্রয়োজন নেই। তবে, যখন আমরা কোনো নির্দিষ্ট টাইপের জন্য CodingKeys ব্যবহার করি, তখন আমাদের ম্যাপ করতে চাওয়া সমস্ত প্রপার্টি নাম যোগ করতে হবে।
উপরের কোড স্নিপেটে, আমরা একটি id প্রপার্টি সংজ্ঞায়িত করেছি যা আমরা একটি SwiftUI List ভিউতে আইডেন্টিফায়ার হিসেবে ব্যবহার করতে চাইতে পারি। যদি আমরা এটিকে CodingKeys এ নির্দিষ্ট না করতাম, তাহলে ডেটা ফেচ করার সময় এটি ম্যাপ হতো না এবং ফলস্বরূপ nil ' হয়ে যেত। এর ফলে List ভিউটি প্রথম ডকুমেন্ট দিয়ে পূরণ হয়ে যেত।
যে কোনো প্রপার্টি যা সংশ্লিষ্ট CodingKeys enum-এ কেস হিসেবে তালিকাভুক্ত নয়, তা ম্যাপিং প্রক্রিয়ার সময় উপেক্ষা করা হবে। এটি বেশ সুবিধাজনক হতে পারে, যদি আমরা নির্দিষ্টভাবে কিছু প্রপার্টিকে ম্যাপিং থেকে বাদ দিতে চাই।
সুতরাং উদাহরণস্বরূপ, যদি আমরা reasonWhyILoveThis প্রপার্টিটিকে ম্যাপ হওয়া থেকে বাদ দিতে চাই, তাহলে আমাদের শুধু CodingKeys enum থেকে এটিকে সরিয়ে ফেলতে হবে:
struct ProgrammingLanguage: Identifiable, Codable {
@DocumentID var id: String?
var name: String
var year: Date
var reasonWhyILoveThis: String = ""
enum CodingKeys: String, CodingKey {
case id
case name = "language_name"
case year
}
}
মাঝে মাঝে আমাদের Cloud Firestore ডকুমেন্টে একটি খালি অ্যাট্রিবিউট লিখতে হতে পারে। কোনো মানের অনুপস্থিতি বোঝানোর জন্য সুইফটে অপশনাল (optional) এর ধারণা রয়েছে এবং Cloud Firestore null ) মান সমর্থন করে। তবে, nil ) মান থাকা অপশনাল এনকোড করার ক্ষেত্রে ডিফল্ট আচরণ হলো সেগুলোকে বাদ দিয়ে দেওয়া। @ExplicitNull আমাদেরকে সুইফট অপশনাল এনকোড করার সময় সেগুলোর পরিচালনার উপর কিছুটা নিয়ন্ত্রণ দেয়: একটি অপশনাল প্রপার্টিকে @ExplicitNull হিসেবে ফ্ল্যাগ করার মাধ্যমে, আমরা Cloud Firestore বলতে পারি যে যদি এতে nil (nil) মান থাকে, তবে প্রপার্টিটিকে ডকুমেন্টে নাল (null) মান দিয়ে লিখতে হবে।
রঙ ম্যাপিংয়ের জন্য একটি কাস্টম এনকোডার এবং ডিকোডার ব্যবহার করা
Codable ব্যবহার করে ডেটা ম্যাপিং সম্পর্কিত আমাদের আলোচনার শেষ বিষয় হিসেবে, চলুন কাস্টম এনকোডার এবং ডিকোডারের সাথে পরিচিত হওয়া যাক। এই বিভাগে Cloud Firestore কোনো নেটিভ ডেটাটাইপ নিয়ে আলোচনা করা হয়নি, কিন্তু কাস্টম এনকোডার এবং ডিকোডার আপনার Cloud Firestore অ্যাপগুলোতে ব্যাপকভাবে উপযোগী।
"আমি কীভাবে রং ম্যাপ করতে পারি" হলো ডেভেলপারদের কাছে সবচেয়ে বেশি জিজ্ঞাসিত প্রশ্নগুলোর মধ্যে একটি, শুধু Cloud Firestore জন্যই নয়, বরং সুইফট এবং JSON-এর মধ্যে ম্যাপিংয়ের ক্ষেত্রেও। এর জন্য অনেক সমাধান রয়েছে, কিন্তু সেগুলোর বেশিরভাগই JSON-কে কেন্দ্র করে তৈরি, এবং প্রায় সবগুলোই রংগুলোকে তাদের RGB উপাদান দিয়ে গঠিত একটি নেস্টেড ডিকশনারি হিসেবে ম্যাপ করে।
মনে হচ্ছে এর চেয়ে ভালো ও সহজ কোনো সমাধান থাকা উচিত। আমরা ওয়েব কালার (অথবা আরও নির্দিষ্ট করে বললে, CSS হেক্স কালার নোটেশন) ব্যবহার করি না কেন — এগুলো ব্যবহার করা সহজ (মূলত একটি স্ট্রিং মাত্র), এবং এগুলো স্বচ্ছতাও সমর্থন করে!
একটি সুইফট Color তার হেক্স ভ্যালুর সাথে ম্যাপ করতে হলে, আমাদের এমন একটি সুইফট এক্সটেনশন তৈরি করতে হবে যা Color -এ কোডেবল (Codable) যুক্ত করে।
extension Color {
init(hex: String) {
let rgba = hex.toRGBA()
self.init(.sRGB,
red: Double(rgba.r),
green: Double(rgba.g),
blue: Double(rgba.b),
opacity: Double(rgba.alpha))
}
//... (code for translating between hex and RGBA omitted for brevity)
}
extension Color: Codable {
public init(from decoder: Decoder) throws {
let container = try decoder.singleValueContainer()
let hex = try container.decode(String.self)
self.init(hex: hex)
}
public func encode(to encoder: Encoder) throws {
var container = encoder.singleValueContainer()
try container.encode(toHex)
}
}
decoder.singleValueContainer() ব্যবহার করে, আমরা RGBA কম্পোনেন্টগুলোকে নেস্ট না করেই একটি String তার সমতুল্য Color ডিকোড করতে পারি। এছাড়াও, আপনি এই ভ্যালুগুলোকে প্রথমে কনভার্ট না করেই আপনার অ্যাপের ওয়েব UI-তে ব্যবহার করতে পারবেন!
এর মাধ্যমে, আমরা ট্যাগ ম্যাপিংয়ের জন্য কোড আপডেট করতে পারি, ফলে আমাদের অ্যাপের UI কোডে ম্যানুয়ালি ট্যাগের রঙ ম্যাপ করার পরিবর্তে সরাসরি তা নিয়ন্ত্রণ করা আরও সহজ হয়ে যায়।
struct Tag: Codable, Hashable {
var title: String
var color: Color
}
struct BookWithTags: Codable {
@DocumentID var id: String?
var title: String
var numberOfPages: Int
var author: String
var tags: [Tag]
}
ত্রুটি পরিচালনা
উপরের কোড স্নিপেটগুলোতে আমরা ইচ্ছাকৃতভাবে এরর হ্যান্ডলিং ন্যূনতম রেখেছি, কিন্তু একটি প্রোডাকশন অ্যাপে, আপনাকে যেকোনো এরর সুন্দরভাবে হ্যান্ডেল করা নিশ্চিত করতে হবে।
এখানে একটি কোড স্নিপেট দেওয়া হলো যা দেখায় যে আপনি সম্মুখীন হতে পারেন এমন যেকোনো ত্রুটির পরিস্থিতি কীভাবে সামাল দিতে হয়:
class MappingSimpleTypesViewModel: ObservableObject {
@Published var book: Book = .empty
@Published var errorMessage: String?
private var db = Firestore.firestore()
func fetchAndMap() {
fetchBook(documentId: "hitchhiker")
}
func fetchAndMapNonExisting() {
fetchBook(documentId: "does-not-exist")
}
func fetchAndTryMappingInvalidData() {
fetchBook(documentId: "invalid-data")
}
private func fetchBook(documentId: String) {
let docRef = db.collection("books").document(documentId)
docRef.getDocument(as: Book.self) { result in
switch result {
case .success(let book):
// A Book value was successfully initialized from the DocumentSnapshot.
self.book = book
self.errorMessage = nil
case .failure(let error):
// A Book value could not be initialized from the DocumentSnapshot.
switch error {
case DecodingError.typeMismatch(_, let context):
self.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.valueNotFound(_, let context):
self.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.keyNotFound(_, let context):
self.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.dataCorrupted(let key):
self.errorMessage = "\(error.localizedDescription): \(key)"
default:
self.errorMessage = "Error decoding document: \(error.localizedDescription)"
}
}
}
}
}
লাইভ আপডেটে ত্রুটি পরিচালনা
পূর্ববর্তী কোড স্নিপেটটি দেখায় কিভাবে একটিমাত্র ডকুমেন্ট ফেচ করার সময় এরর হ্যান্ডেল করতে হয়। একবার ডেটা ফেচ করার পাশাপাশি, Cloud Firestore তথাকথিত স্ন্যাপশট লিসেনার ব্যবহার করে আপনার অ্যাপে আপডেট ঘটার সাথে সাথেই তা পৌঁছে দেওয়াও সমর্থন করে: আমরা একটি কালেকশন (বা কোয়েরি)-এর উপর একটি স্ন্যাপশট লিসেনার রেজিস্টার করতে পারি, এবং যখনই কোনো আপডেট আসবে, Cloud Firestore আমাদের লিসেনারটিকে কল করবে।
এখানে একটি কোড স্নিপেট দেওয়া হলো, যা দেখায় কীভাবে একটি স্ন্যাপশট লিসেনার রেজিস্টার করতে হয়, Codable ব্যবহার করে ডেটা ম্যাপ করতে হয় এবং যেকোনো সম্ভাব্য ত্রুটি সামাল দিতে হয়। এটি আরও দেখায় কীভাবে কালেকশনে একটি নতুন ডকুমেন্ট যোগ করতে হয়। আপনি দেখতে পাবেন, ম্যাপ করা ডকুমেন্টগুলো ধারণকারী লোকাল অ্যারেটি আমাদের নিজেদের আপডেট করার কোনো প্রয়োজন নেই, কারণ এই কাজটি স্ন্যাপশট লিসেনারের ভেতরের কোডই করে দেয়।
class MappingColorsViewModel: ObservableObject {
@Published var colorEntries = [ColorEntry]()
@Published var newColor = ColorEntry.empty
@Published var errorMessage: String?
private var db = Firestore.firestore()
private var listenerRegistration: ListenerRegistration?
public func unsubscribe() {
if listenerRegistration != nil {
listenerRegistration?.remove()
listenerRegistration = nil
}
}
func subscribe() {
if listenerRegistration == nil {
listenerRegistration = db.collection("colors")
.addSnapshotListener { [weak self] (querySnapshot, error) in
guard let documents = querySnapshot?.documents else {
self?.errorMessage = "No documents in 'colors' collection"
return
}
self?.colorEntries = documents.compactMap { queryDocumentSnapshot in
let result = Result { try queryDocumentSnapshot.data(as: ColorEntry.self) }
switch result {
case .success(let colorEntry):
if let colorEntry = colorEntry {
// A ColorEntry value was successfully initialized from the DocumentSnapshot.
self?.errorMessage = nil
return colorEntry
}
else {
// A nil value was successfully initialized from the DocumentSnapshot,
// or the DocumentSnapshot was nil.
self?.errorMessage = "Document doesn't exist."
return nil
}
case .failure(let error):
// A ColorEntry value could not be initialized from the DocumentSnapshot.
switch error {
case DecodingError.typeMismatch(_, let context):
self?.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.valueNotFound(_, let context):
self?.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.keyNotFound(_, let context):
self?.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.dataCorrupted(let key):
self?.errorMessage = "\(error.localizedDescription): \(key)"
default:
self?.errorMessage = "Error decoding document: \(error.localizedDescription)"
}
return nil
}
}
}
}
}
func addColorEntry() {
let collectionRef = db.collection("colors")
do {
let newDocReference = try collectionRef.addDocument(from: newColor)
print("ColorEntry stored with new document reference: \(newDocReference)")
}
catch {
print(error)
}
}
}
এই পোস্টে ব্যবহৃত সমস্ত কোড স্নিপেট একটি নমুনা অ্যাপ্লিকেশনের অংশ, যা আপনি এই গিটহাব রিপোজিটরি থেকে ডাউনলোড করতে পারেন।
এগিয়ে যান এবং কোডেবল ব্যবহার করুন!
সুইফটের কোডেবল এপিআই (Codable API) সিরিয়ালাইজড ফরম্যাট থেকে আপনার অ্যাপ্লিকেশনের ডেটা মডেলে ডেটা ম্যাপ করার এবং সেখান থেকে ডেটা ফিরিয়ে আনার একটি শক্তিশালী ও নমনীয় উপায় প্রদান করে। এই নির্দেশিকায় আপনি দেখেছেন, Cloud Firestore ডেটাস্টোর হিসেবে ব্যবহার করে এমন অ্যাপগুলোতে এটি ব্যবহার করা কতটা সহজ।
সহজ ডেটা টাইপ ব্যবহার করে একটি প্রাথমিক উদাহরণ থেকে শুরু করে, আমরা ক্রমান্বয়ে ডেটা মডেলের জটিলতা বাড়িয়েছি এবং এই পুরো সময়জুড়ে ম্যাপিং করার জন্য কোডেবল (Codable) ও ফায়ারবেস (Firebase)-এর বাস্তবায়নের উপর নির্ভর করতে পেরেছি।
কোডেবল সম্পর্কে আরও বিস্তারিত জানতে, আমি নিম্নলিখিত উৎসগুলো সুপারিশ করছি:
- জন সানডেলের কোডেবল-এর মৌলিক বিষয়গুলো নিয়ে একটি চমৎকার প্রবন্ধ রয়েছে।
- যদি বই আপনার বেশি পছন্দের হয়, তাহলে ম্যাটের ' ফ্লাইট স্কুল গাইড টু সুইফট কোডেবল ' বইটি দেখতে পারেন।
- এবং পরিশেষে, ডনি ওয়ালসের কোডেবল (Codable) নিয়ে একটি সম্পূর্ণ সিরিজ রয়েছে।
যদিও আমরা Cloud Firestore ডকুমেন্ট ম্যাপ করার জন্য একটি বিশদ নির্দেশিকা সংকলন করার যথাসাধ্য চেষ্টা করেছি, এটি সম্পূর্ণ নয় এবং আপনি আপনার ডেটা টাইপগুলো ম্যাপ করার জন্য অন্য কৌশল ব্যবহার করতে পারেন। নিচের 'মতামত পাঠান' বোতামটি ব্যবহার করে, আমাদের জানান যে আপনি অন্যান্য ধরণের Cloud Firestore ডেটা ম্যাপ করতে বা সুইফটে ডেটা উপস্থাপন করতে কী কৌশল ব্যবহার করেন।
Cloud Firestore কোডেবল সাপোর্ট ব্যবহার না করার আসলেই কোনো কারণ নেই।