
In diesem Dokument finden Sie Informationen, die Ihnen helfen, fundierte Entscheidungen zur Architektur Ihrer Anwendungen für hohe Leistung und Zuverlässigkeit zu treffen. Dieses Dokument enthält erweiterte Cloud Firestore-Themen. Wenn Sie gerade erst mit Cloud Firestore beginnen, lesen Sie stattdessen die Kurzanleitung.
Cloud Firestore ist eine flexible, skalierbare Datenbank für die Mobil-, Web- und Serverentwicklung über Firebase und Google Cloud. Der Einstieg in Cloud Firestore und das Schreiben leistungsstarker Anwendungen ist sehr einfach.
Damit Ihre Anwendungen auch bei zunehmender Datenbankgröße und steigendem Traffic weiterhin gut funktionieren, sollten Sie die Mechanismen von Lese- und Schreibvorgängen im Cloud Firestore-Backend kennen. Sie müssen auch die Interaktion Ihrer Lese- und Schreibvorgänge mit der Speicherebene und die zugrunde liegenden Einschränkungen verstehen, die sich auf die Leistung auswirken können.
In den folgenden Abschnitten finden Sie Best Practices, die Sie bei der Entwicklung Ihrer Anwendung berücksichtigen sollten.
Allgemeine Komponenten
Das folgende Diagramm zeigt die übergeordneten Komponenten, die an einer Cloud Firestore API-Anfrage beteiligt sind.
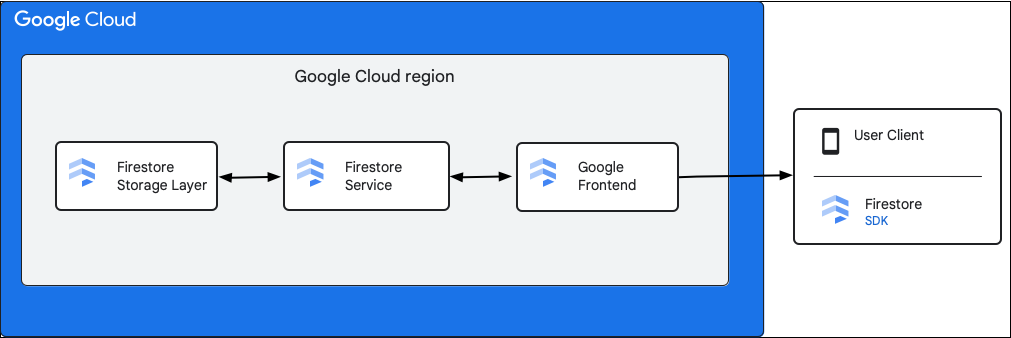
Cloud Firestore SDK und Clientbibliotheken
Cloud Firestore unterstützt SDKs und Clientbibliotheken für verschiedene Plattformen. Eine App kann zwar direkte HTTP- und RPC-Aufrufe an die Cloud Firestore API senden, die Clientbibliotheken bieten jedoch eine Abstraktionsebene, um die API-Nutzung zu vereinfachen und Best Practices zu implementieren. Sie bieten möglicherweise auch zusätzliche Funktionen wie Offlinezugriff, Caches usw.
Google Front End (GFE)
Dieser Infrastrukturdienst gilt für alle Google Cloud-Dienste. Das GFE akzeptiert eingehende Anfragen und leitet sie an den entsprechenden Google-Dienst weiter (in diesem Fall den Dienst Cloud Firestore). Außerdem bietet es weitere wichtige Funktionen, darunter Schutz vor Denial-of-Service-Angriffen.
Dienst Cloud Firestore
Der Cloud Firestore-Dienst führt Prüfungen der API-Anfrage durch, einschließlich Authentifizierung, Autorisierung, Kontingentprüfungen und Sicherheitsregeln, und verwaltet auch Transaktionen. Dieser Cloud Firestore-Dienst umfasst einen Speicherclient, der für das Lesen und Schreiben von Daten mit der Speicherebene interagiert.
Cloud Firestore Speicherebene
Die Cloud Firestore-Speicherebene ist für das Speichern von Daten und Metadaten sowie der zugehörigen Datenbankfunktionen von Cloud Firestore verantwortlich. In den folgenden Abschnitten wird beschrieben, wie Daten in der Cloud Firestore-Speicherebene organisiert sind und wie das System skaliert wird. Wenn Sie wissen, wie Daten organisiert sind, können Sie ein skalierbares Datenmodell entwerfen und die Best Practices in Cloud Firestore besser nachvollziehen.
Schlüsselbereiche und Aufteilungen
Cloud Firestore ist eine dokumentenbasierte NoSQL-Datenbank. Sie speichern Daten in Dokumenten, die in Hierarchien von Sammlungen organisiert sind. Die Sammlungshierarchie und die Dokument-ID werden für jedes Dokument in einen einzelnen Schlüssel übersetzt. Dokumente werden logisch gespeichert und lexikografisch nach diesem einzelnen Schlüssel sortiert. Der Begriff „Schlüsselbereich“ bezieht sich auf einen lexikografisch zusammenhängenden Bereich von Schlüsseln.
Eine typische Cloud Firestore-Datenbank ist zu groß, um auf einer einzelnen physischen Maschine gespeichert zu werden. Es gibt auch Szenarien, in denen die Arbeitslast für die Daten zu hoch ist, um von einem einzelnen Rechner verarbeitet zu werden. Zur Verarbeitung großer Arbeitslasten partitioniert Cloud Firestore die Daten in separate Teile, die auf mehreren Maschinen oder Speicherservern gespeichert und bereitgestellt werden können. Diese Partitionen werden in den Datenbanktabellen in Blöcken von Schlüsselbereichen erstellt, die als Splits bezeichnet werden.
Synchrone Replikation
Die Datenbank wird immer automatisch und synchron repliziert. Die Datenaufteilungen haben Replikate in verschiedenen Zonen, damit sie auch dann verfügbar sind, wenn eine Zone nicht mehr zugänglich ist. Die konsistente Replikation in den verschiedenen Kopien des Splits wird vom Paxos-Algorithmus für den Konsens verwaltet. Ein Replikat jedes Splits wird zum Paxos-Leader bestimmt, der für die Verarbeitung von Schreibvorgängen für diesen Split verantwortlich ist. Dank der synchronen Replikation können Sie immer die neueste Version der Daten aus Cloud Firestore lesen.
Das Ergebnis ist ein skalierbares und hochverfügbares System, das niedrige Latenz sowohl für Lese- als auch für Schreibvorgänge bietet, unabhängig von starker Auslastung und in großem Umfang.
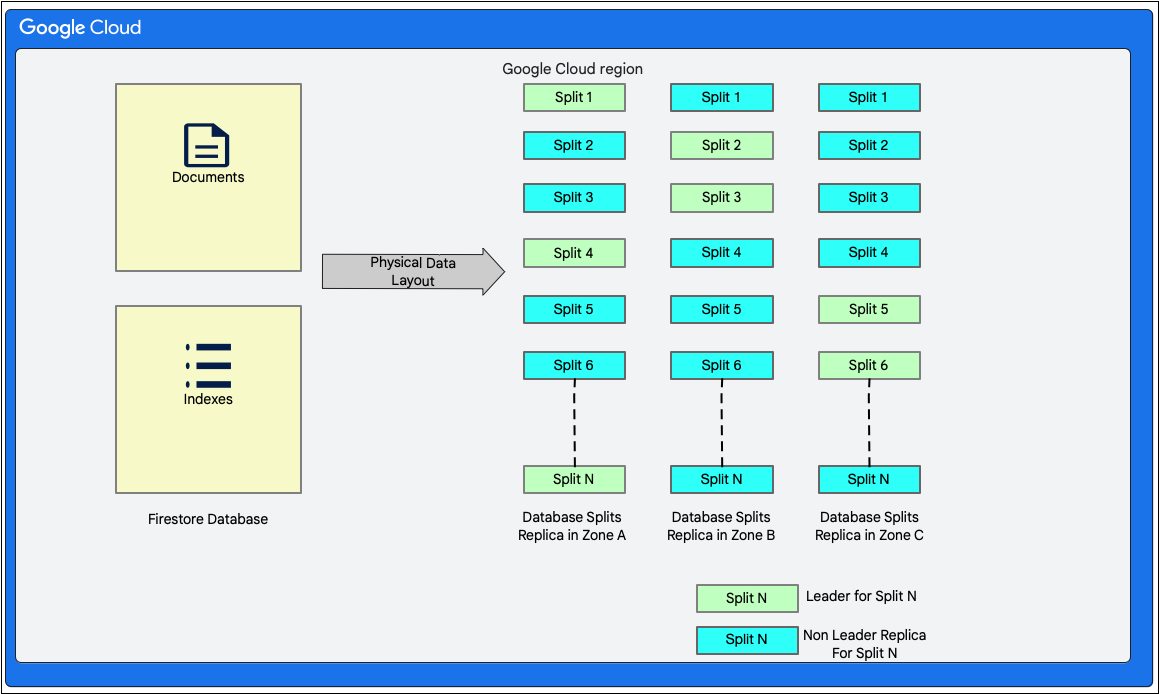
Datenlayout
Cloud Firestore ist eine schemalose Dokumentdatenbank. Intern werden die Daten jedoch hauptsächlich in zwei Tabellen im Stil relationaler Datenbanken in der Speicherebene angeordnet:
- Tabelle Documents: In dieser Tabelle werden Dokumente gespeichert.
- Tabelle Indexe: In dieser Tabelle werden Indexeinträge gespeichert, mit denen Ergebnisse effizient und nach Indexwert sortiert abgerufen werden können.
Das folgende Diagramm zeigt, wie die Tabellen für eine Cloud Firestore-Datenbank mit den Aufteilungen aussehen könnten. Die Splits werden in drei verschiedenen Zonen repliziert und jedem Split ist ein Paxos-Leader zugewiesen.
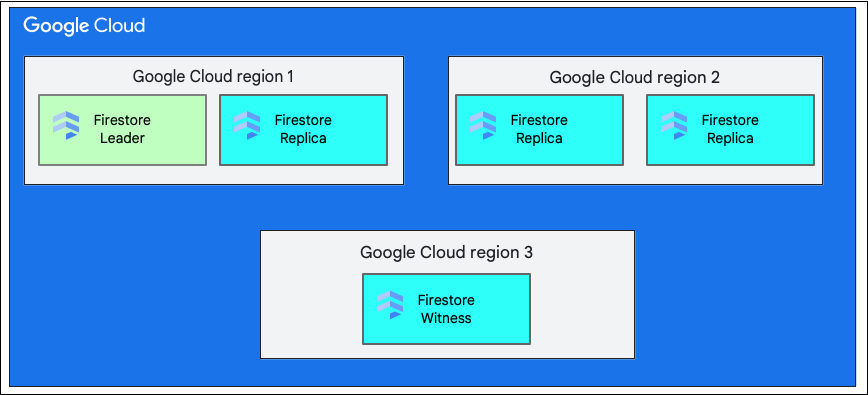
Eine Region im Vergleich zu mehreren Regionen
Wenn Sie eine Datenbank erstellen, müssen Sie eine Region oder Multiregion auswählen.
Ein einzelner regionaler Standort ist ein bestimmter geografischer Ort, z. B. us-west1. Die Datenaufteilungen einer Cloud Firestore-Datenbank haben Replikate in verschiedenen Zonen innerhalb der ausgewählten Region, wie bereits beschrieben.
Ein multiregionaler Standort besteht aus einer definierten Gruppe von Regionen, in denen Replikate der Datenbank gespeichert werden. Bei einer multiregionalen Bereitstellung von Cloud Firestore haben zwei der Regionen vollständige Replikate der gesamten Daten in der Datenbank. In einer dritten Region gibt es ein Zeugenreplikat, das keine vollständigen Daten enthält, aber an der Replikation teilnimmt. Durch die Replikation der Daten zwischen mehreren Regionen können Daten auch bei Verlust einer ganzen Region geschrieben und gelesen werden.
Weitere Informationen zu den Standorten einer Region finden Sie unter Cloud Firestore-Standorte.
Lebenszyklus eines Schreibvorgangs in Cloud Firestore
Ein Cloud Firestore-Client kann Daten schreiben, indem er ein einzelnes Dokument erstellt, aktualisiert oder löscht. Für einen Schreibvorgang in ein einzelnes Dokument müssen sowohl das Dokument als auch die zugehörigen Indexeinträge in der Speicherebene atomar aktualisiert werden. Cloud Firestore unterstützt auch atomare Vorgänge, die aus mehreren Lese- und/oder Schreibvorgängen für ein oder mehrere Dokumente bestehen.
Für alle Arten von Schreibvorgängen bietet Cloud Firestore die ACID-Eigenschaften (Atomarität, Konsistenz, Isolation und Langlebigkeit) von relationalen Datenbanken. Cloud Firestore bietet auch Serialisierbarkeit. Das bedeutet, dass alle Transaktionen so erscheinen, als ob sie in einer seriellen Reihenfolge ausgeführt würden.
Allgemeine Schritte bei einer Schreibtransaktion
Wenn der Cloud Firestore-Client einen Schreibvorgang ausführt oder eine Transaktion mit einer der oben genannten Methoden committet, wird dies intern als Lese-/Schreib-Transaktion für die Datenbank in der Speicherebene ausgeführt. Die Transaktion ermöglicht es Cloud Firestore, die oben genannten ACID-Attribute bereitzustellen.
Als ersten Schritt einer Transaktion liest Cloud Firestore das vorhandene Dokument und bestimmt die Änderungen, die an den Daten in der Tabelle „Documents“ vorgenommen werden sollen.
Dazu gehört auch, dass Sie die Tabelle „Indizes“ wie folgt aktualisieren:
- Felder, die den Dokumenten hinzugefügt werden, erfordern entsprechende Einfügungen in der Tabelle „Indexes“.
- Felder, die aus den Dokumenten entfernt werden, müssen in der Tabelle „Indexes“ entsprechend gelöscht werden.
- Für Felder, die in den Dokumenten geändert werden, sind sowohl Löschvorgänge (für alte Werte) als auch Einfügungen (für neue Werte) in der Tabelle „Indexes“ erforderlich.
Um die oben genannten Mutationen zu berechnen, liest Cloud Firestore die Indexierungskonfiguration für das Projekt. In der Indexierungskonfiguration werden Informationen zu den Indexen für ein Projekt gespeichert. Cloud Firestore verwendet zwei Arten von Indexen: Einzelfeldindexe und zusammengesetzte Indexe. Eine detaillierte Beschreibung der in Cloud Firestore erstellten Indexe finden Sie unter Indextypen in Cloud Firestore.
Sobald die Mutationen berechnet wurden, erfasst Cloud Firestore sie in einer Transaktion und führt dann einen Commit aus.
Schreibtransaktion in der Speicherebene verstehen
Wie bereits erwähnt, beinhaltet ein Schreibvorgang in Cloud Firestore eine Lese-/Schreibtransaktion in der Speicherebene. Je nach Datenlayout kann ein Schreibvorgang einen oder mehrere Splits umfassen, wie im Datenlayout zu sehen ist.
Im folgenden Diagramm hat die Datenbank Cloud Firestore acht Splits (1–8), die auf drei verschiedenen Speicherservern in einer einzelnen Zone gehostet werden. Jeder Split wird in drei(oder mehr) verschiedenen Zonen repliziert. Jeder Split hat einen Paxos-Leader, der sich für verschiedene Splits in einer anderen Zone befinden kann.
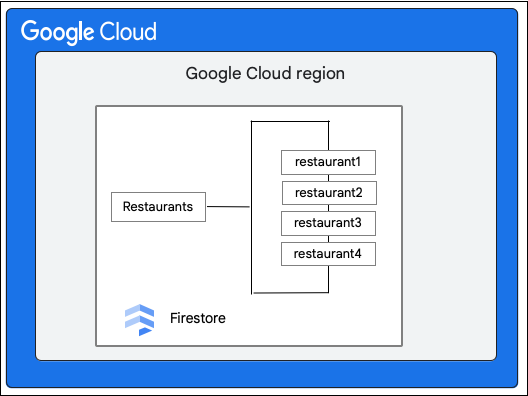
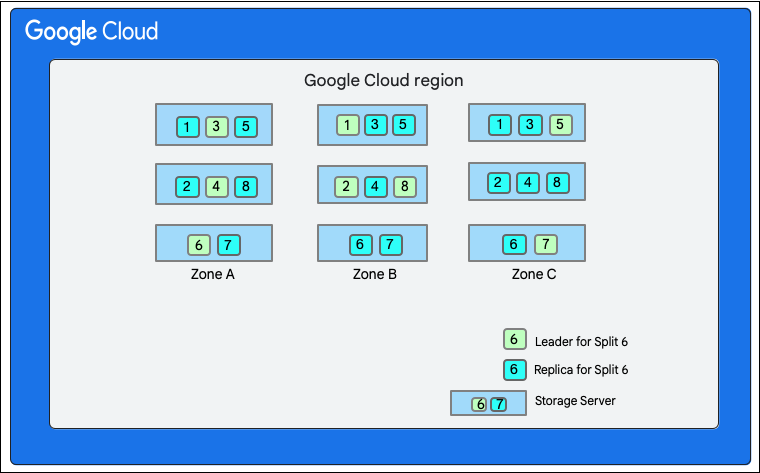 Cloud Firestore-Datenbank aufteilen">
Cloud Firestore-Datenbank aufteilen">
Angenommen, eine Cloud Firestore-Datenbank hat die Restaurants-Sammlung wie folgt:
Der Cloud Firestore-Client fordert die folgende Änderung an einem Dokument in der Sammlung Restaurant an, indem er den Wert des Felds priceCategory aktualisiert.
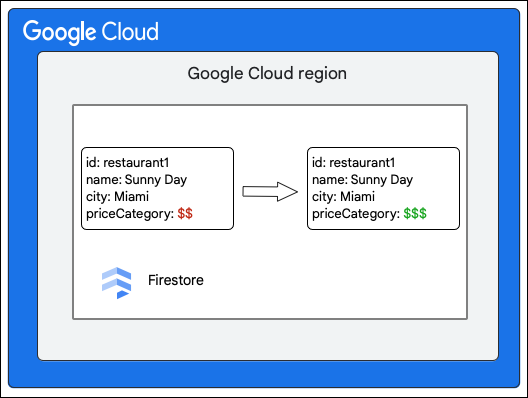
Im Folgenden wird beschrieben, was beim Schreiben passiert:
- Erstellen Sie eine Lese-/Schreibtransaktion.
- Lesen Sie das Dokument
restaurant1in der SammlungRestaurantsaus der Tabelle Documents der Speicherebene. - Lesen Sie die Indexe für das Dokument aus der Tabelle Indexe.
- Berechnen Sie die Änderungen, die an den Daten vorgenommen werden sollen. In diesem Fall gibt es fünf Mutationen:
- M1: Aktualisieren Sie die Zeile für
restaurant1in der Tabelle Documents, um die Änderung des Werts des FeldspriceCategorywiderzuspiegeln. - M2 und M3: Löschen Sie die Zeilen für den alten Wert von
priceCategoryin der Tabelle Indexes für absteigende und aufsteigende Indexe. - M4 und M5: Fügen Sie die Zeilen für den neuen Wert von
priceCategoryin die Tabelle Indexe für absteigende und aufsteigende Indexe ein.
- M1: Aktualisieren Sie die Zeile für
- Führen Sie ein Commit für diese Mutationen durch.
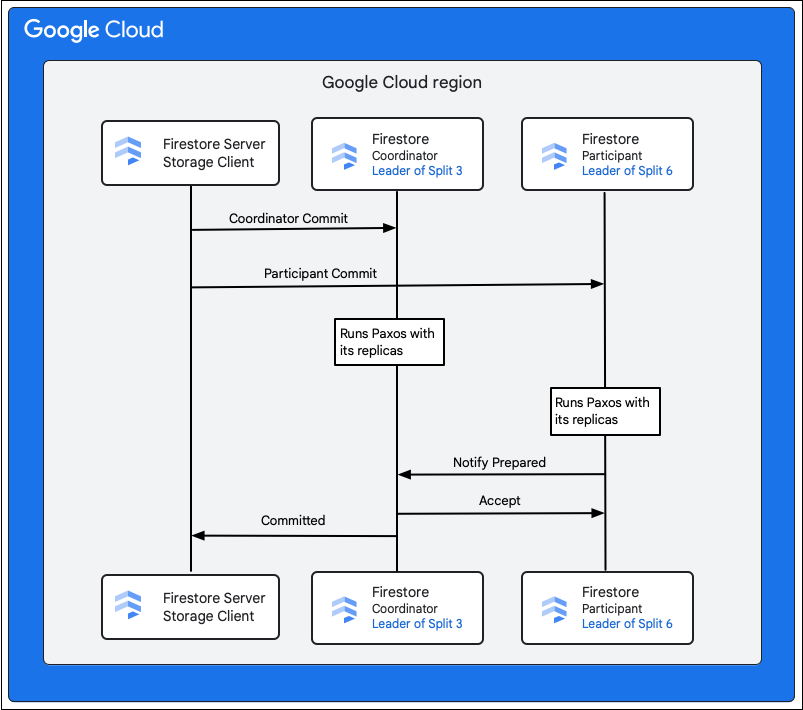
Der Speicherdienst im Cloud Firestore-Dienst sucht nach den Splits, die die Schlüssel der zu ändernden Zeilen enthalten. Nehmen wir an, Split 3 stellt M1 bereit und Split 6 stellt M2 bis M5 bereit. Es gibt eine verteilte Transaktion, an der alle diese Splits als Teilnehmer beteiligt sind. Die Teilnehmeraufteilungen können auch alle anderen Aufteilungen enthalten, aus denen zuvor im Rahmen der Lese-/Schreibtransaktion Daten gelesen wurden.
In den folgenden Schritten wird beschrieben, was im Rahmen des Commits passiert:
- Der Speicherclient gibt einen Commit aus. Der Commit enthält die Mutationen M1 bis M5.
- Split 3 und Split 6 sind die Teilnehmer an dieser Transaktion. Einer der Teilnehmer wird als Koordinator ausgewählt, z. B. Split 3. Die Aufgabe des Koordinators besteht darin, sicherzustellen, dass die Transaktion entweder für alle Teilnehmer übergeben oder individuell abgebrochen wird.
- Die Leader-Replikate dieser Splits sind für die Arbeit der Teilnehmer und Koordinatoren verantwortlich.
- Jeder Teilnehmer und Koordinator führt einen Paxos-Algorithmus mit seinen jeweiligen Replikaten aus.
- Der Leader führt einen Paxos-Algorithmus mit den Replikaten aus. Ein Quorum wird erreicht, wenn die meisten Replikate dem Leader mit einer
ok to commit-Antwort antworten. - Jeder Teilnehmer benachrichtigt dann den Koordinator, wenn er bereit ist (erste Phase des zweiphasigen Commit). Wenn ein Teilnehmer den Commit der Transaktion nicht durchführen kann, wird die gesamte Transaktion
aborts.
- Der Leader führt einen Paxos-Algorithmus mit den Replikaten aus. Ein Quorum wird erreicht, wenn die meisten Replikate dem Leader mit einer
- Sobald der Koordinator weiß, dass alle Teilnehmer, einschließlich er selbst, bereit sind, teilt er allen Teilnehmern das Transaktionsergebnis
acceptmit (zweite Phase des Two-Phase-Commit). In dieser Phase speichert jeder Teilnehmer die Commit-Entscheidung in einem stabilen Speicher und die Transaktion wird übergeben. - Der Koordinator antwortet dem Speicherclient in Cloud Firestore, dass die Transaktion übergeben wurde. Parallel dazu wenden der Koordinator und alle Teilnehmer die Mutationen auf die Daten an.
Wenn die Cloud Firestore-Datenbank klein ist, kann es vorkommen, dass ein einzelner Split alle Schlüssel in den Mutationen M1–M5 enthält. In diesem Fall gibt es nur einen Teilnehmer an der Transaktion und das oben erwähnte zweiphasige Commit ist nicht erforderlich, wodurch die Schreibvorgänge schneller werden.
Schreibvorgänge in mehreren Regionen
Bei einer Bereitstellung in mehreren Regionen erhöht die Verteilung von Replikaten auf Regionen die Verfügbarkeit, geht aber mit Leistungseinbußen einher. Die Kommunikation zwischen Replikaten in verschiedenen Regionen dauert länger. Daher ist die Baseline-Latenz für Cloud Firestore-Vorgänge im Vergleich zu Bereitstellungen in einer einzelnen Region etwas höher.
Wir konfigurieren die Replikate so, dass die Führung für Splits immer in der primären Region bleibt. Die primäre Region ist die Region, aus der Traffic auf den Cloud Firestore-Server eingeht. Durch diese Entscheidung der Führungsebene wird die Umlaufverzögerung bei der Kommunikation zwischen dem Speicherclient in Cloud Firestore und dem Replikat-Leader (oder Koordinator für Transaktionen mit mehreren Splits) verringert.
Jeder Schreibvorgang in Cloud Firestore beinhaltet auch eine Interaktion mit der Echtzeit-Engine in Cloud Firestore. Weitere Informationen zu Echtzeitabfragen finden Sie unter Echtzeitabfragen im großen Maßstab.
Lebenszyklus eines Lesevorgangs in Cloud Firestore
In diesem Abschnitt geht es um eigenständige, nicht in Echtzeit erfolgende Lesevorgänge in Cloud Firestore. Intern werden die meisten dieser Anfragen vom Cloud Firestore-Server in zwei Hauptphasen verarbeitet:
- Ein einzelner Bereichsscan der Tabelle Indexes
- Punkt-Lookups in der Tabelle Dokumente basierend auf dem Ergebnis des vorherigen Scans
Die Datenlesevorgänge aus der Speicherebene werden intern mit einer Datenbanktransaktion ausgeführt, um konsistente Lesevorgänge zu gewährleisten. Im Gegensatz zu den für Schreibvorgänge verwendeten Transaktionen werden diese Transaktionen jedoch nicht gesperrt. Stattdessen wird ein Zeitstempel ausgewählt und alle Lesevorgänge werden zu diesem Zeitstempel ausgeführt. Da sie keine Sperren erhalten, blockieren sie keine gleichzeitigen Lese-Schreib-Transaktionen. Um diese Transaktion auszuführen, gibt der Speicherclient in Cloud Firestore eine Zeitstempelgrenze an, die der Speicherebene mitteilt, wie ein Lesezeitstempel ausgewählt werden soll. Der Typ der Zeitstempelgrenze, die vom Speicherclient in Cloud Firestore ausgewählt wird, wird durch die Leseoptionen für die Leseanforderung bestimmt.
Lesetransaktion in der Speicherebene verstehen
In diesem Abschnitt werden die Arten von Lesezugriffen und deren Verarbeitung in der Speicherebene in Cloud Firestore beschrieben.
Starke Lesevorgänge
Standardmäßig sind Cloud Firestore-Lesevorgänge strikt konsistent. Diese starke Konsistenz bedeutet, dass ein Cloud Firestore-Lesevorgang die aktuelle Version der Daten zurückgibt, die alle Schreibvorgänge widerspiegelt, die bis zum Beginn des Lesevorgangs mit einem Commit festgeschrieben wurden.
Lesevorgang mit einer Aufteilung
Der Speicherclient in Cloud Firestore sucht nach den Splits, die die Schlüssel der zu lesenden Zeilen enthalten. Angenommen, es muss einen Lesevorgang aus Split 3 aus dem vorherigen Abschnitt durchführen. Der Client sendet die Leseanfrage an das nächstgelegene Replikat, um die Roundtrip-Latenz zu reduzieren.
An dieser Stelle können je nach ausgewähltem Replikat die folgenden Fälle eintreten:
- Die Leseanfrage wird an ein Leader-Replikat gesendet (Zone A).
- Da der Leader immer aktuell ist, kann der Lesevorgang direkt ausgeführt werden.
- Die Leseanforderung wird an ein Replikat gesendet, das nicht als Leader fungiert (z. B. Zone B).
- Split 3 weiß möglicherweise anhand seines internen Status, dass er genügend Informationen hat, um den Lesevorgang zu verarbeiten, und tut dies.
- Split 3 ist nicht sicher, ob es die aktuellen Daten gesehen hat. Es sendet eine Nachricht an den Leader, um nach dem Zeitstempel der letzten Transaktion zu fragen, die es zum Verarbeiten des Lesevorgangs ausführen muss. Sobald diese Transaktion angewendet wurde, kann der Lesevorgang fortgesetzt werden.
Cloud Firestore gibt die Antwort dann an den Client zurück.
Lesevorgänge mit mehreren Splits
Wenn die Lesevorgänge aus mehreren Splits erfolgen müssen, wird derselbe Mechanismus für alle Splits angewendet. Sobald die Daten aus allen Splits zurückgegeben wurden, werden die Ergebnisse vom Speicherclient in Cloud Firestore zusammengeführt. Cloud Firestore antwortet dann mit diesen Daten auf die Anfrage des Clients.
Veraltete Lesevorgänge
„Stark lesen“ ist der Standardmodus in Cloud Firestore. Dies kann jedoch zu einer potenziell höheren Latenz führen, da möglicherweise eine Kommunikation mit dem Leader erforderlich ist. Oft muss Ihre Cloud Firestore-Anwendung nicht die neueste Version der Daten lesen und die Funktionalität funktioniert auch mit Daten, die einige Sekunden alt sind.
In diesem Fall kann der Client mit den read_time-Leseoptionen veraltete Lesevorgänge erhalten. In diesem Fall werden Lesevorgänge so ausgeführt, wie die Daten am read_time waren. Das nächste Replikat hat höchstwahrscheinlich bereits überprüft, dass es Daten am angegebenen read_time hat.
Für eine deutlich bessere Leistung sind 15 Sekunden ein angemessener Veralterungswert. Auch bei veralteten Lesevorgängen sind die ausgegebenen Zeilen miteinander konsistent.
Heißlaufen vermeiden
Die Splits in Cloud Firestore werden automatisch in kleinere Teile zerlegt, um die Arbeit der Bereitstellung von Traffic bei Bedarf oder bei einer Erweiterung des Schlüsselbereichs auf mehr Speicherserver zu verteilen. Splits, die zur Bewältigung von übermäßigem Traffic erstellt wurden, werden etwa 24 Stunden lang beibehalten, auch wenn der Traffic nachlässt. Bei wiederkehrenden Traffic-Spitzen bleiben die Aufteilungen also erhalten und bei Bedarf werden weitere eingeführt. Diese Mechanismen helfen Cloud Firestore-Datenbanken, bei steigender Traffic-Last oder Datenbankgröße automatisch zu skalieren. Es gibt jedoch einige Einschränkungen, die unten erläutert werden.
Das Aufteilen von Speicher und Last dauert einige Zeit. Wenn Sie den Traffic zu schnell steigern, kann dies zu einer hohen Latenz oder zu Fehlern aufgrund von überschrittenen Fristen führen, die häufig als Hotspots bezeichnet werden, während der Dienst sich anpasst. Als Best Practice wird empfohlen, Vorgänge über den Schlüsselbereich zu verteilen und gleichzeitig den Traffic für eine Sammlung in einer Datenbank mit 500 Vorgängen pro Sekunde zu erhöhen. Erhöhen Sie nach dieser schrittweisen Steigerung den Traffic alle fünf Minuten um bis zu 50 %. Dieser Prozess wird als 500/50/5-Regel bezeichnet und sorgt dafür, dass die Datenbank optimal skaliert werden kann, um Ihre Arbeitslast zu bewältigen.
Splits werden zwar automatisch bei steigender Last erstellt, Cloud Firestore kann einen Schlüsselbereich jedoch nur so lange aufteilen, bis er ein einzelnes Dokument über einen dedizierten Satz replizierter Speicherserver bereitstellt. Daher kann es bei einer hohen und anhaltenden Anzahl gleichzeitiger Vorgänge für ein einzelnes Dokument zu einem Hotspot für dieses Dokument kommen. Wenn Sie bei einem einzelnen Dokument dauerhaft hohe Latenzen feststellen, sollten Sie Ihr Datenmodell so ändern, dass die Daten auf mehrere Dokumente aufgeteilt oder repliziert werden.
Konfliktfehler treten auf, wenn mehrere Vorgänge gleichzeitig versuchen, dasselbe Dokument zu lesen und/oder zu schreiben.
Ein weiterer Sonderfall von Hotspotting tritt auf, wenn ein sequenziell ansteigender/absteigender Schlüssel als Dokument-ID in Cloud Firestore verwendet wird und eine beträchtlich hohe Anzahl von Vorgängen pro Sekunde erfolgt. Mehr Splits zu erstellen, hilft hier nicht, da die Trafficspitze einfach in den neu erstellten Split verschoben wird. Da Cloud Firestore standardmäßig alle Felder im Dokument automatisch indexiert, können solche sich bewegenden Hotspots auch im Indexbereich für ein Dokumentfeld erstellt werden, das einen sequenziell steigenden/sinkenden Wert wie einen Zeitstempel enthält.
Wenn Sie die oben beschriebenen Best Practices befolgen, kann Cloud Firestore beliebig große Arbeitslasten bewältigen, ohne dass Sie die Konfiguration anpassen müssen.
Fehlerbehebung
Cloud Firestore bietet Key Visualizer als Diagnosetool zur Analyse von Nutzungsmustern und zur Behebung von Hotspot-Problemen.