
Wtyczka Google Cloud eksportuje dane telemetrii i logowania Firebase Genkit do pakietu Cloud Observability, który obsługuje panel Firebase AI Monitoring.
Instalacja
npm i --save @genkit-ai/google-cloudAby lokalnie uruchamiać kod Genkit, który zawiera tę wtyczkę, musisz też mieć zainstalowane narzędzie Google Cloud CLI.
Konfigurowanie konta Google Cloud
Ten dodatek wymaga konta lub projektu Google Cloud. Wszystkie projekty Firebase zawierają domyślnie konsolę GCP. Możesz też zarejestrować się na stronie https://cloud.google.com.
Zanim dodasz wtyczkę, sprawdź, czy w projekcie GCP są włączone te interfejsy API:
Te interfejsy API powinny być wymienione w panelu interfejsów API Twojego projektu.
Aby dowiedzieć się więcej o włączaniu i wyłączaniu interfejsów API, kliknij tutaj.
Konfiguracja Genkit
Aby włączyć śledzenie, rejestrowanie i monitorowanie w chmurze (dane), wystarczy wykonać te czynności:
enableGoogleCloudTelemetry():
import { enableGoogleCloudTelemetry } from '@genkit-ai/google-cloud';
enableGoogleCloudTelemetry();
W wersji produkcyjnej telemetria jest eksportowana automatycznie.
Uwierzytelnianie i autoryzacja
Wtyczka wymaga identyfikatora projektu Google Cloud i danych logowania do aplikacji.
Google Cloud
Jeśli wdrażasz kod w środowisku Google Cloud (np. Cloud Functions czy Cloud Run), identyfikator projektu i dane uwierzytelniające zostaną automatycznie znalezione za pomocą domyślnych danych uwierzytelniających aplikacji.
Musisz przypisać te role do konta usługi, które uruchamia Twój kod (czyli „dołączone konto usługi”), korzystając z konsoli IAM:
roles/monitoring.metricWriterroles/cloudtrace.agentroles/logging.logWriter
Programowanie lokalne
Aby podczas tworzenia w sposób lokalny dane logowania użytkownika były dostępne dla wtyczki, musisz wykonać dodatkowe czynności.
Ustaw zmienną środowiskową
GCLOUD_PROJECTna projekt Google Cloud.Uwierzytelnij się za pomocą interfejsu wiersza poleceń
gcloud:gcloud auth application-default login
Środowiska produkcyjne poza Google Cloud
W miarę możliwości zalecamy jednak korzystanie z procesu domyślnego uwierzytelniania aplikacji, aby udostępnić dane logowania wtyczce.
Zwykle wymaga to wygenerowania klucza konta usługi lub pary kluczy i wdrożenia tych danych logowania do środowiska produkcyjnego.
Postępuj zgodnie z instrukcjami, aby skonfigurować klucz konta usługi.
Upewnij się, że konto usługi ma przypisane te role:
roles/monitoring.metricWriterroles/cloudtrace.agentroles/logging.logWriter
Wdrożyć plik danych logowania w środowisku produkcyjnym (nie dodawać do kodu źródłowego).
Ustaw zmienną środowiskową
GOOGLE_APPLICATION_CREDENTIALSjako ścieżkę do pliku z danymi logowania.GOOGLE_APPLICATION_CREDENTIALS = "path/to/your/key/file"
W niektórych środowiskach bez serwera nie można wdrożyć pliku z danymi logowania. W tym przypadku zamiast kroków 3 i 4 powyżej możesz ustawić zmienną środowiskową GCLOUD_SERVICE_ACCOUNT_CREDS za pomocą zawartości pliku z danymi logowania w ten sposób:
GCLOUD_SERVICE_ACCOUNT_CREDS='{
"type": "service_account",
"project_id": "your-project-id",
"private_key_id": "your-private-key-id",
"private_key": "your-private-key",
"client_email": "your-client-email",
"client_id": "your-client-id",
"auth_uri": "https://accounts.google.com/o/oauth2/auth",
"token_uri": "https://accounts.google.com/o/oauth2/token",
"auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/v1/certs",
"client_x509_cert_url": "your-cert-url"
}'
Konfiguracja wtyczki
Funkcja enableGoogleCloudTelemetry() przyjmuje opcjonalny obiekt konfiguracji, który konfiguruje instancję OpenTelemetry NodeSDK.
import { AlwaysOnSampler } from '@opentelemetry/sdk-trace-base';
enableGoogleCloudTelemetry({
forceDevExport: false, // Set this to true to export telemetry for local runs
sampler: new AlwaysOnSampler(),
autoInstrumentation: true,
autoInstrumentationConfig: {
'@opentelemetry/instrumentation-fs': { enabled: false },
'@opentelemetry/instrumentation-dns': { enabled: false },
'@opentelemetry/instrumentation-net': { enabled: false },
},
metricExportIntervalMillis: 5_000,
});
Obiekty konfiguracji umożliwiają szczegółową kontrolę nad różnymi aspektami eksportu danych telemetrycznych opisanego poniżej.
dane logowania
Umożliwia określenie danych logowania bezpośrednio za pomocą JWTInput z biblioteki google-auth.
sampler
W przypadku, gdy eksportowanie wszystkich ścieżek nie jest praktyczne, OpenTelemetry umożliwia próbkowanie ścieżek.
Dostępne są 4 wstępnie skonfigurowane próbnik:
- AlwaysOnSampler – próbkuje wszystkie ścieżki.
- AlwaysOffSampler – próbkowanie bez śladów
- ParentBased – próbki oparte na nadrzędnym zakresie.
- TraceIdRatioBased – próbkowanie określonego odsetka logów czasu (z możliwością konfiguracji).
autoInstrumentation i autoInstrumentationConfig
Włączenie automatycznego pomiaru pozwala OpenTelemetry rejestrować dane telemetryczne z bibliotek innych firm bez konieczności modyfikowania kodu.
metricExportIntervalMillis
To pole określa interwał eksportowania danych w milisekundach.
metricExportTimeoutMillis
To pole określa czas oczekiwania na eksport danych w milisekundach.
disableMetrics
Umożliwia zastąpienie ustawień, które wyłączają eksport danych, zachowując jednocześnie eksportowanie dzienników i śladów.
disableTraces
Umożliwia zastąpienie ustawień, które wyłącza eksportowanie dzienników, zachowując przy tym eksport danych i logów.
disableLoggingIO
Zapewnia zastąpienie, które wyłącza zbieranie logów wejściowych i wyjściowych.
forceDevExport
Ta opcja spowoduje, że Genkit wyeksportuje dane telemetryczne i dane dziennika podczas działania w środowisku dev (np. lokalnie).
Testowanie integracji
Podczas konfigurowania wtyczki użyj opcji forceDevExport: true, aby włączyć eksport telemetrii na potrzeby lokalnych testów. Aby wyświetlić dane telemetryczne, otwórz Eksploratora dzienników, danych lub śladów Google Cloud.
Pakiet Google Cloud Observability
Po wdrożonym kodzie (np. przepływie) otwórz panel Monitorowanie usługi Cloud i wybierz swój projekt. Możesz z niego łatwo przechodzić do eksploratorów Logów, Danych i Śladów, aby monitorować produkcję.

Logi i ślady
W menu po lewej stronie w sekcji „Eksplorowanie” kliknij „Przeglądarka dzienników”.
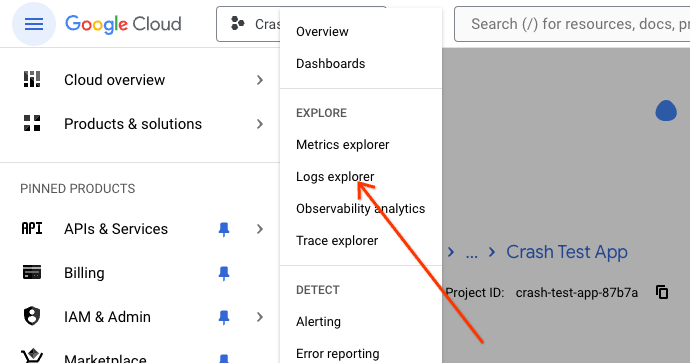
Tutaj zobaczysz wszystkie dzienniki powiązane z wdrożonym kodem Genkit, console.log(). Każdy plik dziennika z prefiksem [genkit] to wewnętrzny plik dziennika Genkit, który zawiera informacje, które mogą być przydatne do debugowania. Na przykład dzienniki Genkit w formacie Config[...] zawierają metadane takie jak temperatura i wartości topK dotyczące konkretnych wnioskowań LLM.
Dzienniki w formacie Output[...] zawierają odpowiedzi LLM, a Input[...] – prompty. Rejestrowanie w chmurze ma niezawodne listy kontroli dostępu, które umożliwiają szczegółową kontrolę dostępu do poufnych dzienników.
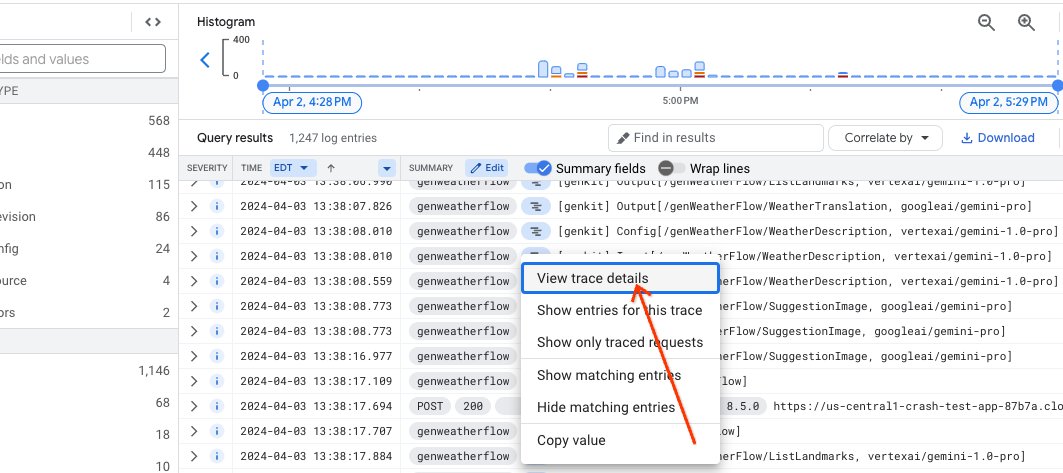
Otworzy się panel podglądu śledzenia, który zawiera podsumowanie szczegółów śledzenia. Aby zobaczyć pełne szczegóły, w prawym górnym rogu panelu kliknij link „Wyświetl w śledzeniu”.
Najważniejszym elementem nawigacji w Cloud Trace jest wykres rozrzutu. Zawiera wszystkie zebrane ślady w danym przedziale czasu.
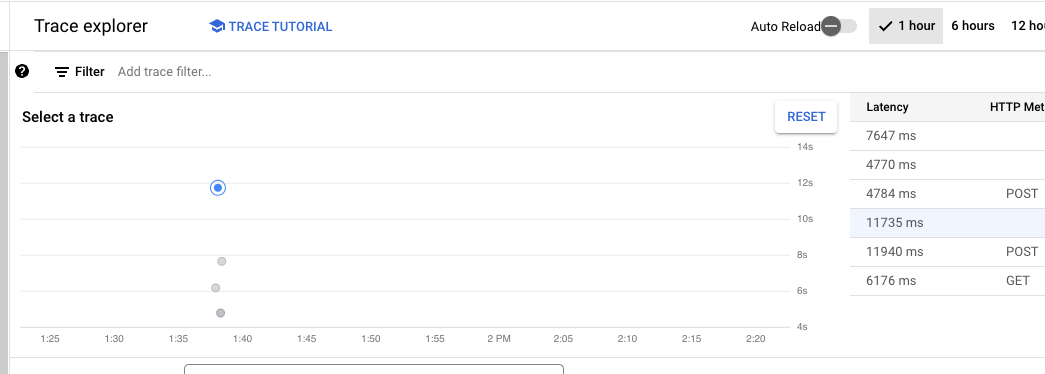
Kliknięcie każdego punktu danych spowoduje wyświetlenie jego szczegółów pod wykresem punktowym.
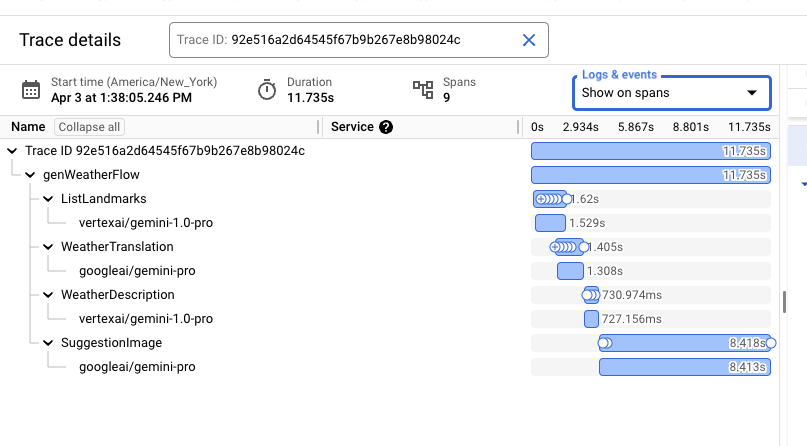
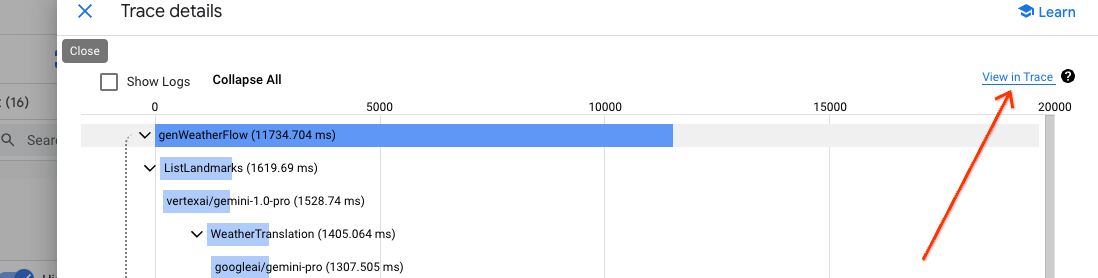
Widok szczegółowy zawiera kształt przepływu danych, w tym wszystkie kroki, oraz ważne informacje o czasie. Cloud Trace może przeplatać wszystkie logi powiązane z danym śladem w tym widoku. W menu „Logi i zdarzenia” kliknij „Pokaż rozwinięcie”.
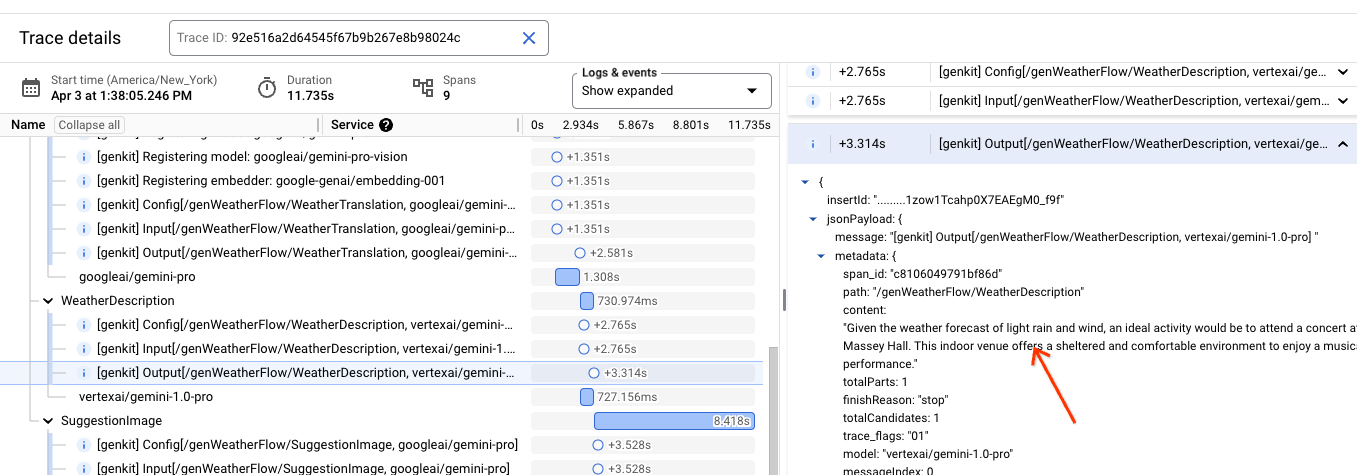
Wygenerowany widok umożliwia szczegółowe zapoznanie się z logami w kontekście ścieżki, w tym z promptami i odpowiedziami LLM.
Dane
Aby wyświetlić wszystkie dane wyeksportowane przez Genkit, w menu po lewej stronie kliknij „Zarządzanie danymi” w sekcji „Konfigurowanie”.
Konsola zarządzania danymi zawiera tabelę ze wszystkimi zebranymi danymi, w tym z danymi dotyczącymi Cloud Run i jego otoczenia.
Po kliknięciu opcji „Workload” (Obciążenie) zobaczysz listę z danymi zebranymi przez Genkit. Każdy rodzaj danych z prefiksem genkit to wewnętrzny rodzaj danych Genkit.
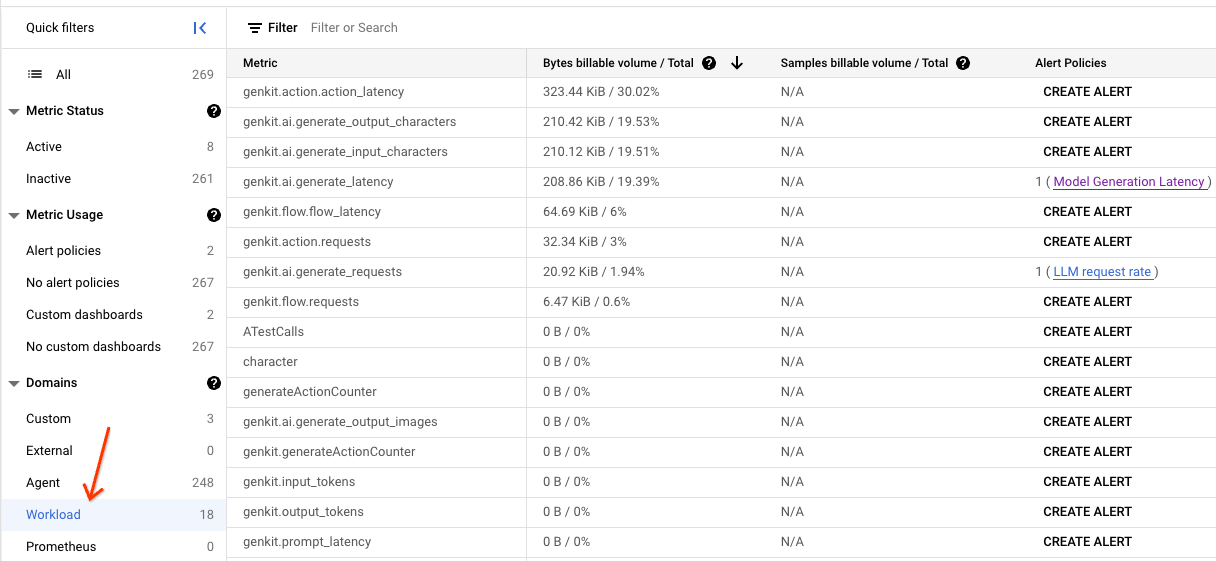
Genkit zbiera kilka kategorii danych, w tym: funkcje, działania i generowanie. Każdy rodzaj danych ma kilka przydatnych wymiarów, które ułatwiają filtrowanie i grupowanie.
Typowe wymiary:
flow_name– nazwa najwyższego poziomu przepływu.flow_path– element i jego element nadrzędny tworzą łańcuch aż do elementu wyższego poziomu.error_code– w przypadku błędu odpowiedni kod błędu.error_message– w przypadku błędu odpowiedni komunikat o błędzie.model– nazwa modelu.
Dane o cechach
Funkcje to najwyższy poziom dostępu do kodu Genkit. W większości przypadków będzie to proces. W przeciwnym razie będzie to najwyższy przedział w śladzie.
| Nazwa | Typ | Opis |
|---|---|---|
| genkit/feature/requests | Licznik | Liczba żądań |
| genkit/feature/latency | Histogram | Czas oczekiwania w ms |
Każdy rodzaj danych zawiera te wymiary:
| Nazwa | Opis |
|---|---|
| nazwa | Nazwa funkcji. W większości przypadków jest to najwyższy poziom Genkit |
| status | „success” (udało się) lub „failure” (nie udało się) w zależności od tego, czy udało się dodać funkcję. |
| błąd | Ustawiany tylko wtedy, gdy status=failure. Zawiera typ błędu, który spowodował błąd. |
| źródło | Język źródłowy Genkit. 'ts' |
| sourceVersion | Wersja platformy Genkit |
Dane o działaniach
Działania to ogólny krok wykonania w Genkit. Każdy z tych kroków będzie śledzony pod kątem tych danych:
| Nazwa | Typ | Opis |
|---|---|---|
| genkit/action/requests | Licznik | Liczba przypadków wykonania tej czynności |
| genkit/action/latency | Histogram | Czas oczekiwania na wykonanie w ms |
Każdy rodzaj danych o działaniach zawiera te wymiary:
| Nazwa | Opis |
|---|---|
| nazwa | Nazwa działania |
| featureName | Nazwa nadrzędnej funkcji, która jest wykonywana |
| ścieżka | Ścieżka wykonania od katalogu głównego funkcji do tego działania, np. '/mojeUsługi/działanieNadająceSię/toDziałanie' |
| status | „success” (skuteczne) lub „failure” (nieskuteczne) w zależności od tego, czy działanie zostało wykonane. |
| błąd | Ustawiany tylko wtedy, gdy status=failure. Zawiera typ błędu, który spowodował błąd. |
| źródło | Język źródłowy Genkit. 'ts' |
| sourceVersion | Wersja platformy Genkit |
Generowanie danych
Są to specjalne dane o działaniach związanych z działaniami, które wchodzą w interakcję z modelem. Oprócz żądań i opóźnień śledzone są też dane wejściowe i wyjściowe, a także wymiary specyficzne dla modelu, które ułatwiają debugowanie i dostrajanie konfiguracji.
| Nazwa | Typ | Opis |
|---|---|---|
| genkit/ai/generate/requests | Licznik | Liczba wywołań tego modelu |
| genkit/ai/generate/latency | Histogram | Czas oczekiwania w ms |
| genkit/ai/generate/input/tokens | Licznik | Tokeny wejściowe |
| genkit/ai/generate/output/tokens | Licznik | Tokeny wyjściowe |
| genkit/ai/generate/input/characters | Licznik | Wprowadzanie znaków |
| genkit/ai/generate/output/characters | Licznik | Znaki wyjściowe |
| genkit/ai/generate/input/images | Licznik | Obrazy wejściowe |
| genkit/ai/generate/output/images | Licznik | Obrazy wyjściowe |
| genkit/ai/generate/input/audio | Licznik | Wprowadzanie plików audio |
| genkit/ai/generate/output/audio | Licznik | Pliki wyjściowe |
Każdy rodzaj danych zawiera te wymiary:
| Nazwa | Opis |
|---|---|
| modelName | Nazwa modelu |
| featureName | Nazwa nadrzędnej funkcji, która jest wykonywana |
| ścieżka | Ścieżka wykonania od katalogu głównego funkcji do tego działania, np. '/myFeature/parentAction/thisAction' |
| latencyMs | Czas odpowiedzi modelu |
| status | „success” (udało się) lub „failure” (nie udało się) w zależności od tego, czy udało się dodać funkcję. |
| błąd | Ustawiany tylko wtedy, gdy status=failure. Zawiera typ błędu, który spowodował błąd. |
| źródło | Język źródłowy Genkit. 'ts' |
| sourceVersion | Wersja platformy Genkit |
Wizualizację wskaźników można wykonać w narzędziu Metrics Explorer. W menu po lewej stronie kliknij „Eksplorator danych” pod nagłówkiem „Eksplorowanie”.
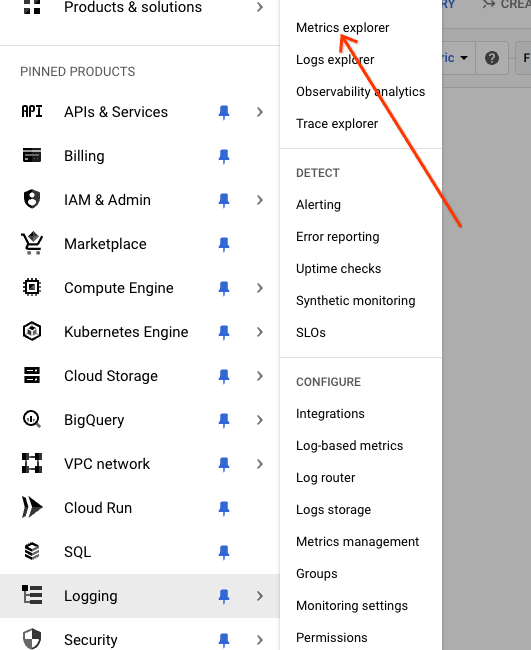
Wybierz dane, klikając menu „Wybierz dane”, wybierając „Generic Node”, „Genkit” i dane.
Wizualizacja danych zależy od ich typu (licznik, histogram itp.). Narzędzie Metrics Explorer udostępnia zaawansowane funkcje agregacji i wysyłania zapytań, aby ułatwić przedstawianie danych na wykresach z uwzględnieniem różnych wymiarów.
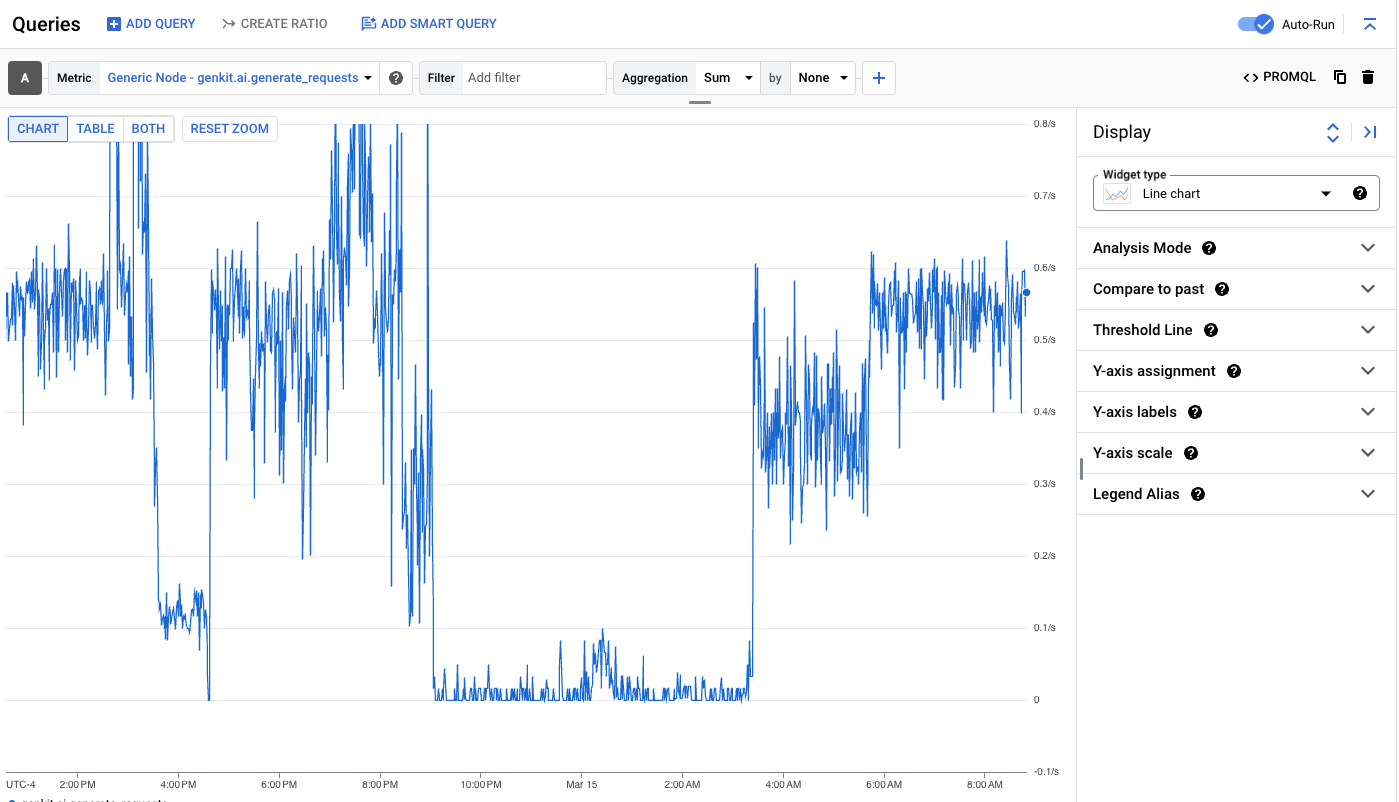
Opóźnienie danych telemetrycznych
Może minąć trochę czasu, zanim dane telemetryczne dotyczące konkretnego wykonania przepływu zostaną wyświetlone w pakiecie operacyjnym Cloud. W większości przypadków opóźnienie nie przekracza 1 minuty.
Limity
Należy pamiętać o kilku ważnych limitach:
Koszt
Usługi Cloud Logging, Cloud Trace i Cloud Monitoring mają obszerne bezpłatne poziomy. Szczegółowe ceny znajdziesz pod tymi linkami: