
Uygulamalarınızı yüksek performans ve güvenilirlik için tasarlama konusunda bilinçli kararlar vermek üzere bu belgeyi okuyun. Bu belgede gelişmiş Cloud Firestore konuları ele alınmaktadır. Cloud Firestore'ı kullanmaya yeni başlıyorsanız bunun yerine hızlı başlangıç kılavuzuna bakın.
Cloud Firestore, Firebase ve Google Cloud tarafından geliştirilen mobil cihaz, web ve sunucu geliştirme için esnek ve ölçeklenebilir bir veritabanıdır. Cloud Firestore ile zengin ve güçlü uygulamalar yazmaya başlamak çok kolaydır.
Veritabanı boyutunuz ve trafiğiniz arttıkça uygulamalarınızın iyi performans göstermeye devam etmesini sağlamak için Cloud Firestore arka uçtakiCloud Firestore okuma ve yazma işlemlerinin mekanizmasını anlamak önemlidir. Ayrıca okuma ve yazma işlemlerinizin depolama katmanıyla etkileşimini ve performansı etkileyebilecek temel kısıtlamaları da anlamanız gerekir.
Uygulamanızı tasarlamadan önce en iyi uygulamalar için aşağıdaki bölümlere bakın.
Üst düzey bileşenleri anlama
Aşağıdaki şemada, Cloud Firestore API isteğinde yer alan üst düzey bileşenler gösterilmektedir.
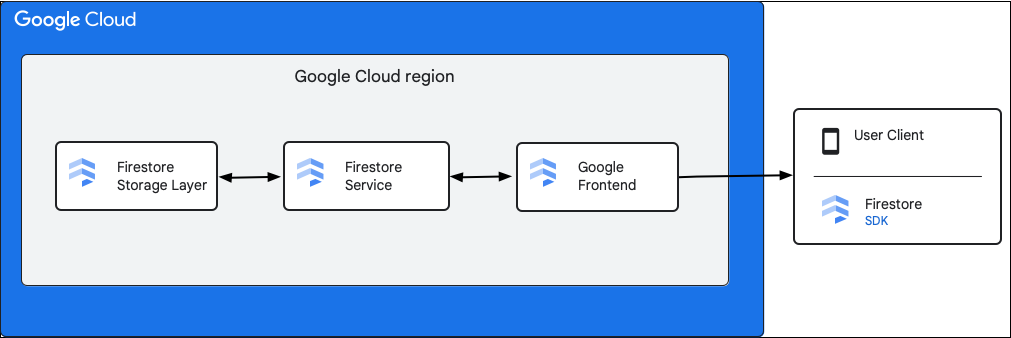
Cloud Firestore SDK ve istemci kitaplıkları
Cloud Firestore, farklı platformlar için SDK'ları ve istemci kitaplıklarını destekler. Bir uygulama, Cloud Firestore API'ye doğrudan HTTP ve RPC çağrıları yapabilir ancak istemci kitaplıkları, API kullanımını basitleştirmek ve en iyi uygulamaları uygulamak için bir soyutlama katmanı sağlar. Ayrıca çevrimdışı erişim ve önbellek gibi ek özellikler de sunabilirler.
Google Front End (GFE)
Bu, tüm Google Cloud hizmetlerinde ortak olan bir altyapı hizmetidir. GFE, gelen istekleri kabul eder ve bunları ilgili Google hizmetine (bu bağlamda Cloud Firestore hizmeti) yönlendirir. Ayrıca hizmet reddi saldırılarına karşı koruma gibi diğer önemli işlevleri de sağlar.
Cloud Firestore hizmet
Cloud Firestore hizmeti, kimlik doğrulama, yetkilendirme, kota kontrolleri ve güvenlik kuralları dahil olmak üzere API isteği üzerinde kontroller gerçekleştirir ve işlemleri de yönetir. Bu Cloud Firestore hizmet, veri okuma ve yazma işlemleri için depolama katmanıyla etkileşimde bulunan bir depolama istemcisi içerir.
Cloud Firestore depolama katmanı
Cloud Firestore depolama katmanı, hem verileri hem de meta verileri ve Cloud Firestore tarafından sağlanan ilişkili veritabanı özelliklerini depolamaktan sorumludur. Aşağıdaki bölümlerde, verilerin Cloud Firestore depolama katmanında nasıl düzenlendiği ve sistemin nasıl ölçeklendirildiği açıklanmaktadır. Verilerin nasıl düzenlendiğini öğrenmek, ölçeklenebilir bir veri modeli tasarlamanıza ve Cloud Firestore'daki en iyi uygulamaları daha iyi anlamanıza yardımcı olabilir.
Anahtar Aralıkları ve Bölünmeler
Cloud Firestore, NoSQL belge tabanlı bir veritabanıdır. Verileri, koleksiyon hiyerarşileri içinde düzenlenen dokümanlarda saklarsınız. Koleksiyon hiyerarşisi ve doküman kimliği, her doküman için tek bir anahtara çevrilir. Dokümanlar, bu tek anahtara göre mantıksal olarak depolanır ve sözlük sırasına göre sıralanır. Sözlükbilimsel olarak bitişik bir anahtar aralığını ifade etmek için anahtar aralığı terimini kullanırız.
Tipik bir Cloud Firestore veritabanı, tek bir fiziksel makineye sığamayacak kadar büyüktür. Veriler üzerindeki iş yükünün tek bir makinenin işleyemeyeceği kadar ağır olduğu senaryolar da vardır. Cloud Firestore, büyük iş yüklerini işlemek için verileri birden fazla makinede veya depolama sunucusunda depolanıp sunulabilen ayrı parçalara böler. Bu bölümler, anahtar aralıkları bloklarındaki veritabanı tablolarında oluşturulur ve bölme olarak adlandırılır.
Eşzamanlı Çoğaltma
Veritabanının her zaman otomatik ve eşzamanlı olarak kopyalandığını unutmayın. Veri bölümlerinin, bir bölgeye erişilemediğinde bile kullanılabilir kalması için farklı bölgelerde kopyaları bulunur. Bölünmenin farklı kopyalarına tutarlı şekilde replikasyon, fikir birliği için Paxos algoritması tarafından yönetilir. Her bölümün bir kopyası, Paxos lideri olarak hareket etmek üzere seçilir. Bu kopya, söz konusu bölüme yazma işlemlerini yönetmekten sorumludur. Senkronize replikasyon, Cloud Firestore'dan her zaman verilerin en son sürümünü okuyabilmenizi sağlar.
Bunun sonucunda, ağır iş yüklerinden bağımsız olarak ve çok büyük ölçekte hem okuma hem de yazma işlemleri için düşük gecikme süreleri sağlayan, ölçeklenebilir ve yüksek oranda kullanılabilir bir sistem elde edilir.
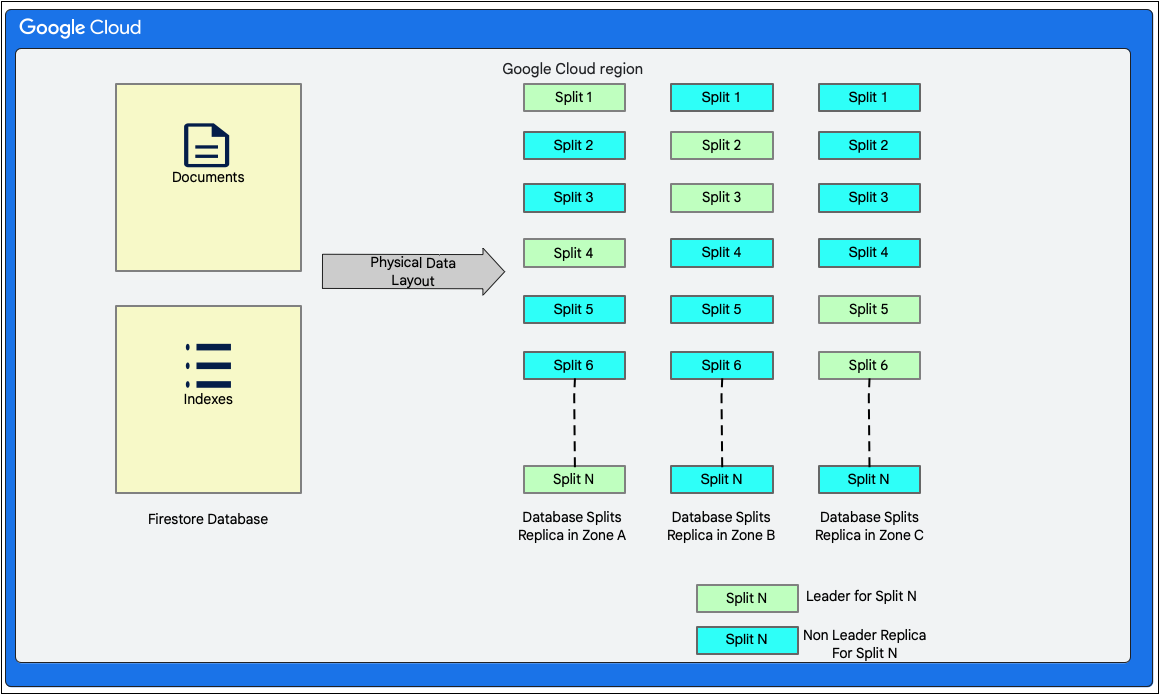
Veri düzeni
Cloud Firestore, şemasız bir belge veritabanıdır. Ancak dahili olarak verileri, depolama katmanında öncelikle iki ilişkisel veritabanı tarzı tabloda aşağıdaki gibi düzenler:
- Dokümanlar tablosu: Dokümanlar bu tabloda saklanır.
- Dizinler tablosu: Sonuçların verimli bir şekilde alınmasını ve dizin değerine göre sıralanmasını sağlayan dizin girişleri bu tabloda saklanır.
Aşağıdaki şemada, Cloud Firestore veritabanı tablolarının bölmelerle nasıl görünebileceği gösterilmektedir. Bölmeler üç farklı bölgede çoğaltılır ve her bölmeye bir Paxos lideri atanır.
Tek bölgeye karşı çoklu bölge
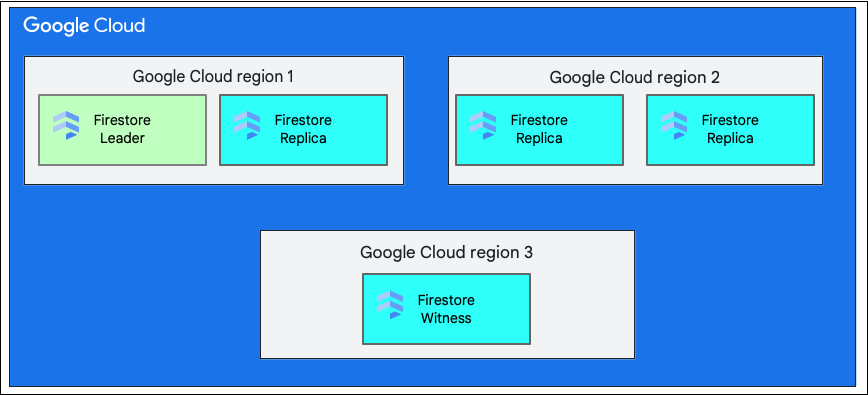
Veritabanı oluştururken bir bölge veya çoklu bölge seçmeniz gerekir.
Tek bir bölgesel konum, us-west1 gibi belirli bir coğrafi konumdur. Cloud Firestore veritabanının veri bölümleri, daha önce açıklandığı gibi seçilen bölgedeki farklı bölgelerde replikalara sahiptir.
Çok bölgeli konum, veritabanı replikalarının depolandığı tanımlı bir bölge grubundan oluşur. Cloud Firestore'nın çok bölgeli dağıtımında, bölgelerden ikisinde veritabanındaki tüm verilerin tam kopyaları bulunur. Üçüncü bir bölgede, tam bir veri kümesini korumayan ancak replikasyona katılan bir tanık replikası bulunur. Veriler birden çok bölge arasında çoğaltıldığından, bir bölgenin tamamı kaybolsa bile veriler yazılabilir ve okunabilir.
Bir bölgenin konumları hakkında daha fazla bilgi için Cloud Firestore konumları konusuna bakın.
Yazma işleminin ömrünü anlama Cloud Firestore
Bir Cloud Firestore istemcisi, tek bir doküman oluşturarak, güncelleyerek veya silerek veri yazabilir. Tek bir belgeye yazma işlemi, hem belgenin hem de ilişkili dizin girişlerinin depolama katmanında atomik olarak güncellenmesini gerektirir. Cloud Firestore, bir veya daha fazla dokümanda birden fazla okuma ve/veya yazma işleminden oluşan atomik işlemleri de destekler.
Cloud Firestore, her türlü yazma işlemi için ilişkisel veritabanlarının ACID özelliklerini (atomiklik, tutarlılık, izolasyon ve dayanıklılık) sağlar. Cloud Firestore ayrıca serileştirilebilirlik de sağlar. Bu, tüm işlemlerin seri sırada yürütülmüş gibi görünmesi anlamına gelir.
Yazma işlemindeki üst düzey adımlar
Cloud Firestore istemcisi, daha önce bahsedilen yöntemlerden herhangi birini kullanarak yazma işlemi gerçekleştirdiğinde veya bir işlemi onayladığında bu işlem, depolama katmanında dahili olarak veritabanı okuma/yazma işlemi olarak yürütülür. İşlem, Cloud Firestore'nın daha önce bahsedilen ACID özelliklerini sağlamasına olanak tanır.
Bir işlemin ilk adımı olarak Cloud Firestore, mevcut dokümanı okur ve Dokümanlar tablosundaki verilerde yapılacak değişiklikleri belirler.
Ayrıca, dizinler tablosunda aşağıdaki gibi gerekli güncellemelerin yapılması da gerekir:
- Belgelere eklenen alanlar için Dizinler tablosunda ilgili eklemeler gerekir.
- Belgelerden kaldırılan alanların dizinler tablosunda da silinmesi gerekir.
- Belgelerde değiştirilen alanlar için hem silme (eski değerler için) hem de ekleme (yeni değerler için) işlemleri gerekir.
Daha önce bahsedilen mutasyonları hesaplamak için Cloud Firestore, projenin dizin oluşturma yapılandırmasını okur. Dizin oluşturma yapılandırması, bir projenin dizinleriyle ilgili bilgileri saklar. Cloud Firestore, tek alanlı ve birleşik olmak üzere iki tür dizin kullanır. Cloud Firestore'da oluşturulan dizinler hakkında ayrıntılı bilgi için Cloud Firestore'daki dizin türleri başlıklı makaleyi inceleyin.
Değişiklikler hesaplandıktan sonra Cloud Firestore bunları bir işlem içinde toplar ve ardından işler.
Depolama katmanındaki yazma işlemlerini anlama
Daha önce de belirtildiği gibi, Cloud Firestore içinde yazma işlemi, depolama katmanında okuma-yazma işlemi içerir. Verilerin düzenine bağlı olarak, bir yazma işlemi veri düzeninde görüldüğü gibi bir veya daha fazla bölme içerebilir.
Aşağıdaki şemada, Cloud Firestore veritabanı tek bir bölgedeki üç farklı depolama sunucusunda barındırılan sekiz bölüme (1-8 olarak işaretlenmiş) sahiptir ve her bölüm 3(veya daha fazla) farklı bölgede çoğaltılır. Her bölümün bir Paxos lideri vardır. Bu lider, farklı bölümler için farklı bir bölgede olabilir.
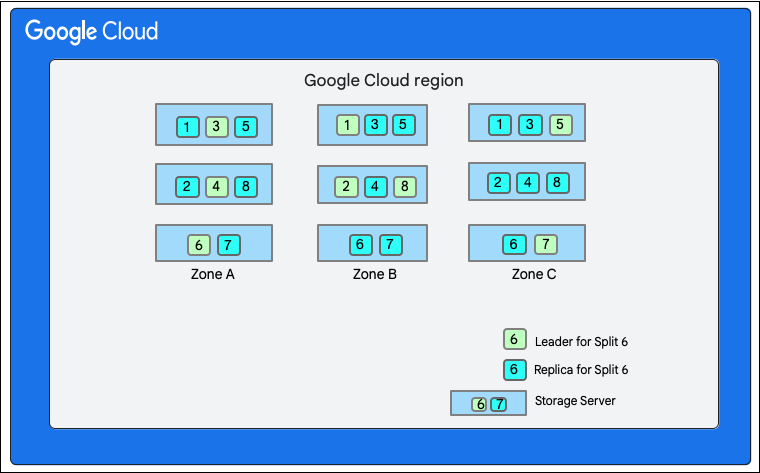 Cloud Firestore veritabanı bölme">
Cloud Firestore veritabanı bölme">
Cloud Firestore koleksiyonuna sahip bir Restaurants veritabanını ele alalım:
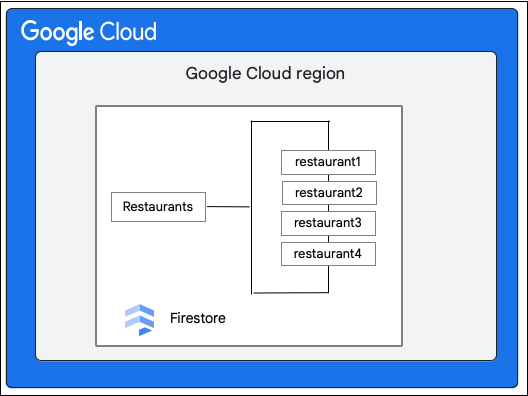
Cloud Firestore istemcisi, priceCategory alanının değerini güncelleyerek Restaurant koleksiyonundaki bir belgede aşağıdaki değişikliği istiyor.
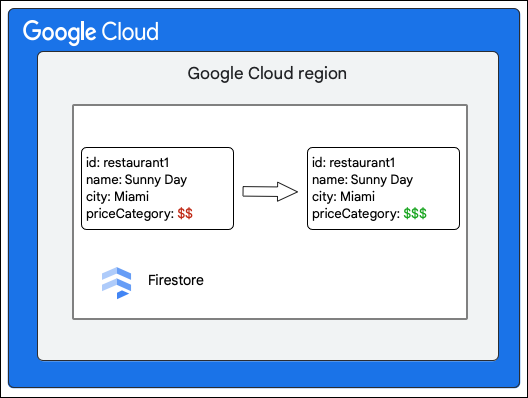
Aşağıdaki genel adımlarda yazma işlemi sırasında neler olduğu açıklanmaktadır:
- Okuma/yazma işlemi oluşturun.
- Depolama katmanındaki Belgeler tablosundan
restaurant1koleksiyonundakiRestaurantsdokümanını okuyun. - Dizinler tablosundan dokümanın dizinlerini okuyun.
- Verilerde yapılacak mutasyonları hesaplayın. Bu durumda beş mutasyon vardır:
- 1. adım: Belgeler tablosunda
restaurant1satırını,priceCategoryalanındaki değer değişikliğini yansıtacak şekilde güncelleyin. - M2 ve M3: Azalan ve artan dizinler için Dizinler tablosunda
priceCategorydeğerinin eski satırlarını silin. - M4 ve M5: Azalan ve artan dizinler için
priceCategorydeğerinin yeni satırlarını Dizinler tablosuna ekleyin.
- 1. adım: Belgeler tablosunda
- Bu mutasyonları işleyin.
Cloud Firestore hizmetindeki depolama istemcisi, değiştirilecek satırların anahtarlarına sahip olan bölümleri arar. 3. Bölüm'ün M1'i, 6. Bölüm'ün ise M2-M5'i yayınladığı bir durumu ele alalım. Tüm bu bölümleri katılımcı olarak içeren dağıtılmış bir işlem vardır. Katılımcı bölümleri, okuma/yazma işlemi kapsamında daha önce verilerin okunduğu diğer bölümleri de içerebilir.
Aşağıdaki adımlarda, commit işlemi sırasında neler olduğu açıklanmaktadır:
- Depolama istemcisi bir commit işlemi gerçekleştirir. Taahhüt, M1-M5 değişikliklerini içeriyor.
- Bu işlemdeki katılımcılar 3 ve 6 numaralı ödemelerdir. Katılımcılardan biri koordinatör olarak seçilir (ör. 3. Bölüm). Koordinatörün görevi, işlemin tüm katılımcılar arasında atomik olarak işlenmesini veya iptal edilmesini sağlamaktır.
- Bu bölümlerin lider kopyaları, katılımcıların ve koordinatörlerin yaptığı işlerden sorumludur.
- Her katılımcı ve koordinatör, kendi kopyalarıyla bir Paxos algoritması çalıştırır.
- Lider, kopyalarla bir Paxos algoritması çalıştırır. Çoğu kopya, liderin isteğine
ok to commityanıtı verirse kvorum sağlanır. - Ardından her katılımcı, hazır olduğunda koordinatörü bilgilendirir (iki aşamalı onaylamanın ilk aşaması). Herhangi bir katılımcı işlemi onaylayamazsa tüm işlem
aborts.
- Lider, kopyalarla bir Paxos algoritması çalıştırır. Çoğu kopya, liderin isteğine
- Koordinatör, kendisi de dahil olmak üzere tüm katılımcıların hazır olduğunu öğrendikten sonra
acceptişlem sonucunu tüm katılımcılara bildirir (iki aşamalı onaylamanın ikinci aşaması). Bu aşamada her katılımcı, commit kararını kararlı depolama alanına kaydeder ve işlem commit edilir. - Koordinatör, depolama istemcisine Cloud Firestore içinde işlemin kaydedildiğini bildirir. Aynı anda, koordinatör ve tüm katılımcılar verilerde değişiklik yapar.
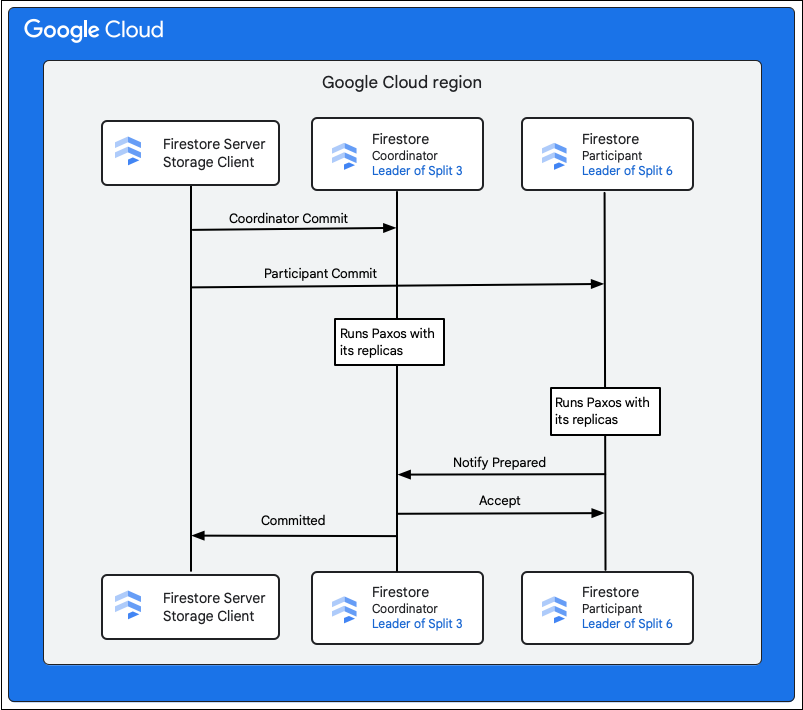
Cloud Firestore veritabanı küçük olduğunda, tek bir bölünme, M1-M5 mutasyonlarındaki tüm anahtarlara sahip olabilir. Bu durumda, işlemde yalnızca bir katılımcı vardır ve daha önce bahsedilen iki aşamalı kesinleştirme gerekli değildir. Bu nedenle yazma işlemleri daha hızlı gerçekleşir.
Çok bölgeli yazma
Çok bölgeli dağıtımda, replikaların bölgelere yayılması kullanılabilirliği artırır ancak performans maliyetiyle birlikte gelir. Farklı bölgelerdeki kopyalar arasındaki iletişim daha uzun gidiş dönüş süreleri gerektirir. Bu nedenle, Cloud Firestore işlemlerinin temel gecikme süresi, tek bölgeli dağıtımlara kıyasla biraz daha fazladır.
Bölümlerin liderliğinin her zaman birincil bölgede kalacağı şekilde replikaları yapılandırırız. Birincil bölge, Cloud Firestore sunucusuna gelen trafiğin geldiği bölgedir. Yönetimin bu kararı, Cloud Firestore içindeki depolama istemcisi ile kopya yöneticisi (veya çoklu bölme işlemleri için koordinatör) arasındaki iletişimde gidiş-dönüş gecikmesini azaltır.
Cloud Firestore içindeki her yazma işlemi, Cloud Firestore içindeki anlık motorla bir etkileşim de içerir. Gerçek zamanlı sorgular hakkında daha fazla bilgi için Büyük ölçekte gerçek zamanlı sorguları anlama başlıklı makaleyi inceleyin.
Cloud Firestore dilinde okuma ömrünü anlama
Bu bölümde, Cloud Firestore'daki bağımsız ve anlık olmayan okumalar ele alınır. Cloud Firestore sunucusu, bu sorguların çoğunu dahili olarak iki ana aşamada işler:
- Dizinler tablosunda tek bir aralık taraması
- Önceki taramanın sonucuna göre Dokümanlar tablosundaki nokta aramaları
Depolama katmanından okunan veriler, tutarlı okumalar sağlamak için dahili olarak bir veritabanı işlemi kullanılarak yapılır. Ancak yazma işlemleri için kullanılan işlemlerin aksine, bu işlemler kilitlenmez. Bunun yerine, bir zaman damgası seçip tüm okuma işlemlerini bu zaman damgasında gerçekleştirerek çalışırlar. Kilit edinmedikleri için eşzamanlı okuma/yazma işlemlerini engellemezler. Bu işlemi yürütmek için Cloud Firestore içindeki depolama istemcisi, depolama katmanına okuma zaman damgasının nasıl seçileceğini bildiren bir zaman damgası sınırı belirtir. Cloud Firestore içinde depolama istemcisi tarafından seçilen zaman damgası türü, okuma isteğinin okuma seçenekleriyle belirlenir.
Depolama katmanındaki okuma işlemlerini anlama
Bu bölümde, okuma türleri ve bunların Cloud Firestore'daki depolama katmanında nasıl işlendiği açıklanmaktadır.
Güçlü okumalar
Varsayılan olarak Cloud Firestore okumaları güçlü ve tutarlıdır. Bu güçlü tutarlılık, Cloud Firestore okuma işleminin, okuma işleminin başlangıcına kadar işlenen tüm yazma işlemlerini yansıtan verilerin en son sürümünü döndürdüğü anlamına gelir.
Tek bölme okuma
Cloud Firestore içindeki depolama istemcisi, okunacak satırların anahtarlarını içeren bölümleri arar. Önceki bölümdeki Split 3'ten okuma yapması gerektiğini varsayalım. İstemci, gidiş dönüş gecikmesini azaltmak için okuma isteğini en yakın kopyaya gönderir.
Bu noktada, seçilen replikaya bağlı olarak aşağıdaki durumlar yaşanabilir:
- Okuma isteği, bir lider replikasına (A Bölgesi) gider.
- Lider her zaman güncel olduğundan okuma işlemi doğrudan devam edebilir.
- Okuma isteği, lider olmayan bir replikaya (ör. B bölgesi) gider.
- 3. bölüm, okuma isteğini karşılamak için yeterli bilgiye sahip olduğunu kendi içindeki durumuna bakarak anlayabilir ve isteği karşılar.
- 3. bölüm, en son verileri görüp görmediğinden emin değil. Okuma işlemini gerçekleştirmek için uygulaması gereken son işlemin zaman damgasını istemek üzere lider sunucuya bir mesaj gönderir. Bu işlem uygulandıktan sonra okuma işlemine devam edilebilir.
Cloud Firestore ardından yanıtı istemciye döndürür.
Çoklu bölme okuma
Okumaların birden fazla bölümden yapılması gerektiği durumlarda, aynı mekanizma tüm bölümlerde geçerlidir. Veriler tüm bölümlerden döndürüldükten sonra Cloud Firestore içindeki depolama istemcisi sonuçları birleştirir. Cloud Firestore daha sonra bu verilerle müşterisine yanıt verir.
Eski okuma işlemleri
Cloud Firestore'da varsayılan mod, güçlü okumadır. Ancak, liderle iletişim kurulması gerekebileceğinden gecikme süresi daha yüksek olabilir. Cloud Firestore uygulamanızın genellikle verilerin en son sürümünü okuması gerekmez ve işlevsellik, birkaç saniye eski olabilecek verilerle iyi çalışır.
Bu gibi durumlarda istemci, read_time okuma seçeneklerini kullanarak eski okumalar almayı tercih edebilir. Bu durumda, okuma işlemleri veriler read_time konumundayken yapılır ve en yakın kopya, belirtilen read_time konumunda verilerin olduğunu doğrulamış olabilir.
Performansı belirgin şekilde artırmak için 15 saniye makul bir eskime değeridir. Eski okumalarda bile döndürülen satırlar birbiriyle tutarlıdır.
Yoğun bölgelerden kaçınma
Cloud Firestore içindeki bölümler, gerektiğinde veya anahtar alanı genişlediğinde trafiğe hizmet verme işini daha fazla depolama sunucusuna dağıtmak için otomatik olarak daha küçük parçalara ayrılır. Aşırı trafiği yönetmek için oluşturulan bölünmeler, trafik ortadan kalksa bile yaklaşık 24 saat boyunca korunur. Bu nedenle, yinelenen trafik artışları varsa bölünmeler korunur ve gerektiğinde daha fazla bölünme uygulanır. Bu mekanizmalar, artan trafik yükü veya veritabanı boyutu altında Cloud Firestore veritabanlarının otomatik olarak ölçeklenmesine yardımcı olur. Ancak aşağıda açıklandığı gibi dikkat etmeniz gereken bazı sınırlamalar vardır.
Depolama ve yükü bölmek zaman alır. Trafiği çok hızlı artırmak, hizmet ayarlanırken genellikle yoğun noktalar olarak adlandırılan yüksek gecikme veya son tarih aşıldı hatalarına neden olabilir. En iyi uygulama, işlemleri anahtar aralığına dağıtırken saniyede 500 işlem içeren bir veritabanındaki koleksiyonda trafiği artırmaktır. Bu kademeli artıştan sonra, trafiği her beş dakikada bir% 50'ye kadar artırın. 500/50/5 kuralı olarak adlandırılan bu işlem, veritabanını iş yükünüzü karşılayacak şekilde optimum düzeyde ölçeklendirir.
Bölünmeler artan yükle birlikte otomatik olarak oluşturulsa da Cloud Firestore, bir anahtar aralığını yalnızca, çoğaltılmış depolama sunucularının özel bir kümesini kullanarak tek bir dokümana hizmet verene kadar bölebilir. Sonuç olarak, tek bir belgede eşzamanlı işlemlerin yüksek ve sürekli hacimleri, bu belgede hotspot'a yol açabilir. Tek bir dokümanda sürekli olarak yüksek gecikmelerle karşılaşırsanız veri modelinizi, verileri birden fazla dokümana bölecek veya kopyalayacak şekilde değiştirmeyi düşünebilirsiniz.
Çakışma hataları, birden fazla işlem aynı belgeyi aynı anda okumaya ve/veya yazmaya çalıştığında oluşur.
Sırayla artan/azalan bir anahtarın Cloud Firestore içinde belge kimliği olarak kullanıldığı ve saniyede önemli ölçüde yüksek sayıda işlem olduğu durumlarda da başka bir özel nokta oluşumu durumu söz konusudur. Trafiğin artması durumunda, yeni oluşturulan bölüme geçiş yapıldığından daha fazla bölüm oluşturmak bu sorunu çözmez. Cloud Firestore, varsayılan olarak dokümandaki tüm alanları otomatik olarak indekslediğinden, bu tür hareketli etkin noktalar, zaman damgası gibi sıralı olarak artan/azalan bir değer içeren bir belge alanının indeks alanında da oluşturulabilir.
Yukarıda belirtilen uygulamaları izleyerek Cloud Firestore'nın, herhangi bir yapılandırma ayarlamanıza gerek kalmadan rastgele büyük iş yüklerine hizmet verecek şekilde ölçeklenebileceğini unutmayın.
Sorun giderme
Cloud Firestore, kullanım kalıplarını analiz etmek ve hotspotting sorunlarını gidermek için tasarlanmış bir teşhis aracı olan Key Visualizer'ı sunar.
Sonraki Adımlar
- Diğer en iyi uygulamalar hakkında bilgi edinin.
- Geniş ölçekte anlık sorgular hakkında bilgi edinin.