
बेहतर परफ़ॉर्मेंस और भरोसेमंद तरीके से काम करने वाले ऐप्लिकेशन बनाने के लिए, इस दस्तावेज़ को पढ़ें. इस दस्तावेज़ में, Cloud Firestore के बारे में ज़्यादा जानकारी दी गई है. अगर आपने हाल ही में Cloud Firestore का इस्तेमाल शुरू किया है, तो क्विकस्टार्ट गाइड देखें.
Cloud Firestore, Firebase और Google Cloud का एक ऐसा डेटाबेस है जिसे ज़रूरत के हिसाब से बदला जा सकता है और बढ़ाया जा सकता है. इसका इस्तेमाल मोबाइल डिवाइस, वेब, और सर्वर डेवलपमेंट के लिए किया जा सकता है. Cloud Firestore का इस्तेमाल शुरू करना बहुत आसान है. साथ ही, इससे बेहतर और ज़्यादा फ़ंक्शन वाले ऐप्लिकेशन बनाए जा सकते हैं.
डेटाबेस का साइज़ और ट्रैफ़िक बढ़ने पर भी आपके ऐप्लिकेशन अच्छा परफ़ॉर्म करते रहें, इसके लिए Cloud Firestore बैकएंड में पढ़ने और लिखने की प्रोसेस को समझना ज़रूरी है. आपको यह भी समझना होगा कि स्टोरेज लेयर के साथ पढ़ने और लिखने की प्रोसेस कैसे काम करती है. साथ ही, उन बुनियादी शर्तों के बारे में भी जानना होगा जो परफ़ॉर्मेंस पर असर डाल सकती हैं.
अपना ऐप्लिकेशन बनाने से पहले, सबसे सही तरीके जानने के लिए यहां दिए गए सेक्शन देखें.
ऊपरी लेवल के कॉम्पोनेंट के बारे में जानकारी
इस डायग्राम में, Cloud Firestore एपीआई अनुरोध में शामिल मुख्य कॉम्पोनेंट दिखाए गए हैं.
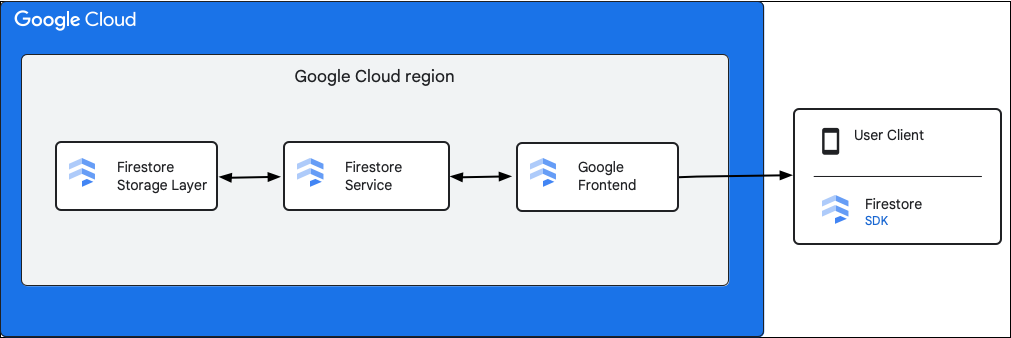
Cloud Firestore एसडीके और क्लाइंट लाइब्रेरी
Cloud Firestore अलग-अलग प्लैटफ़ॉर्म के लिए SDK टूल और क्लाइंट लाइब्रेरी के साथ काम करता है. कोई ऐप्लिकेशन, Cloud Firestore API को सीधे तौर पर एचटीटीपी और आरपीसी कॉल कर सकता है. हालांकि, क्लाइंट लाइब्रेरी, एपीआई के इस्तेमाल को आसान बनाने और सबसे सही तरीकों को लागू करने के लिए, ऐब्स्ट्रैक्शन की एक लेयर उपलब्ध कराती हैं. ये अतिरिक्त सुविधाएं भी दे सकते हैं, जैसे कि ऑफ़लाइन ऐक्सेस, कैश मेमोरी वगैरह.
Google फ़्रंट एंड (जीएफ़ई)
यह एक इंफ़्रास्ट्रक्चर सेवा है, जो Google की सभी क्लाउड सेवाओं के लिए उपलब्ध है. GFE, आने वाले अनुरोधों को स्वीकार करता है और उन्हें Google की संबंधित सेवा (इस संदर्भ में Cloud Firestore सेवा) को भेजता है. यह अन्य ज़रूरी सुविधाएं भी उपलब्ध कराता है. इनमें सेवा से इनकार करने वाले हमलों से सुरक्षा करना भी शामिल है.
Cloud Firestore सेवा
Cloud Firestore सेवा, एपीआई अनुरोध की जांच करती है. इसमें पुष्टि करना, अनुमति देना, कोटे की जांच करना, और सुरक्षा से जुड़े नियम शामिल हैं. यह सेवा, लेन-देन भी मैनेज करती है. इस Cloud Firestore सेवा में स्टोरेज क्लाइंट शामिल होता है. यह डेटा को पढ़ने और लिखने के लिए, स्टोरेज लेयर के साथ इंटरैक्ट करता है.
Cloud Firestore स्टोरेज लेयर
Cloud Firestore स्टोरेज लेयर, डेटा और मेटाडेटा, दोनों को सेव करने के लिए ज़िम्मेदार होती है. साथ ही, यह Cloud Firestore की ओर से उपलब्ध कराई गई डेटाबेस की सुविधाओं को भी सेव करती है. यहां दिए गए सेक्शन में बताया गया है कि Cloud Firestore स्टोरेज लेयर में डेटा कैसे व्यवस्थित किया जाता है और सिस्टम कैसे स्केल करता है. डेटा को व्यवस्थित करने के तरीके के बारे में जानने से, आपको एक ऐसा डेटा मॉडल डिज़ाइन करने में मदद मिल सकती है जिसे आसानी से बढ़ाया जा सके. साथ ही, आपको Cloud Firestore में सबसे सही तरीकों को बेहतर तरीके से समझने में मदद मिल सकती है.
कुंजी रेंज और स्प्लिट
Cloud Firestore एक NoSQL, दस्तावेज़-उन्मुख डेटाबेस है. डेटा को दस्तावेज़ों में सेव किया जाता है. इन दस्तावेज़ों को कलेक्शन के क्रम में व्यवस्थित किया जाता है. कलेक्शन के क्रम और दस्तावेज़ आईडी को हर दस्तावेज़ के लिए एक ही कुंजी में बदला जाता है. दस्तावेज़ों को इस एक कुंजी के हिसाब से, तार्किक तरीके से सेव किया जाता है और लेक्सिकोग्राफ़िक क्रम में लगाया जाता है. हम लेक्सिकोग्राफ़िक तौर पर लगातार मौजूद कुंजियों की रेंज के लिए, 'कुंजी रेंज' शब्द का इस्तेमाल करते हैं.
आम तौर पर, Cloud Firestore डेटाबेस इतना बड़ा होता है कि उसे एक ही फ़िज़िकल मशीन पर फ़िट नहीं किया जा सकता. ऐसे मामले भी होते हैं जिनमें डेटा पर वर्कलोड इतना ज़्यादा होता है कि एक मशीन उसे हैंडल नहीं कर पाती. ज़्यादा वर्कलोड को मैनेज करने के लिए, Cloud Firestore डेटा को अलग-अलग हिस्सों में बांटता है. इन हिस्सों को कई मशीनों या स्टोरेज सर्वर पर सेव किया जा सकता है और वहां से ऐक्सेस किया जा सकता है. ये विभाजन, डेटाबेस टेबल पर मुख्य रेंज के ब्लॉक में किए जाते हैं. इन्हें स्प्लिट कहा जाता है.
सिंक्रोनस रेप्लिकेशन
यह ध्यान रखना ज़रूरी है कि डेटाबेस हमेशा अपने-आप और एक साथ रेप्लिकेट होता रहता है. डेटा के स्प्लिट की रेप्लिका, अलग-अलग ज़ोन में मौजूद होती हैं. इससे यह पक्का किया जाता है कि किसी ज़ोन के ऐक्सेस न होने पर भी डेटा उपलब्ध रहे. स्प्लिट की अलग-अलग कॉपी में एक जैसा डेटा बनाए रखने के लिए, Paxos एल्गोरिदम का इस्तेमाल किया जाता है. हर स्प्लिट के एक रेप्लिका को Paxos लीडर के तौर पर चुना जाता है. यह स्प्लिट में डेटा लिखने की प्रोसेस को मैनेज करता है. सिंक्रोनस रेप्लिकेशन की मदद से, Cloud Firestore से डेटा के सबसे नए वर्शन को हमेशा पढ़ा जा सकता है.
इसकी वजह से, हमें ऐसा सिस्टम मिलता है जो बड़े पैमाने पर काम कर सकता है और हर समय उपलब्ध रहता है. साथ ही, यह पढ़ने और लिखने, दोनों के लिए कम समय लेता है. भले ही, इस पर कितना भी लोड हो और यह कितने भी बड़े पैमाने पर काम कर रहा हो.
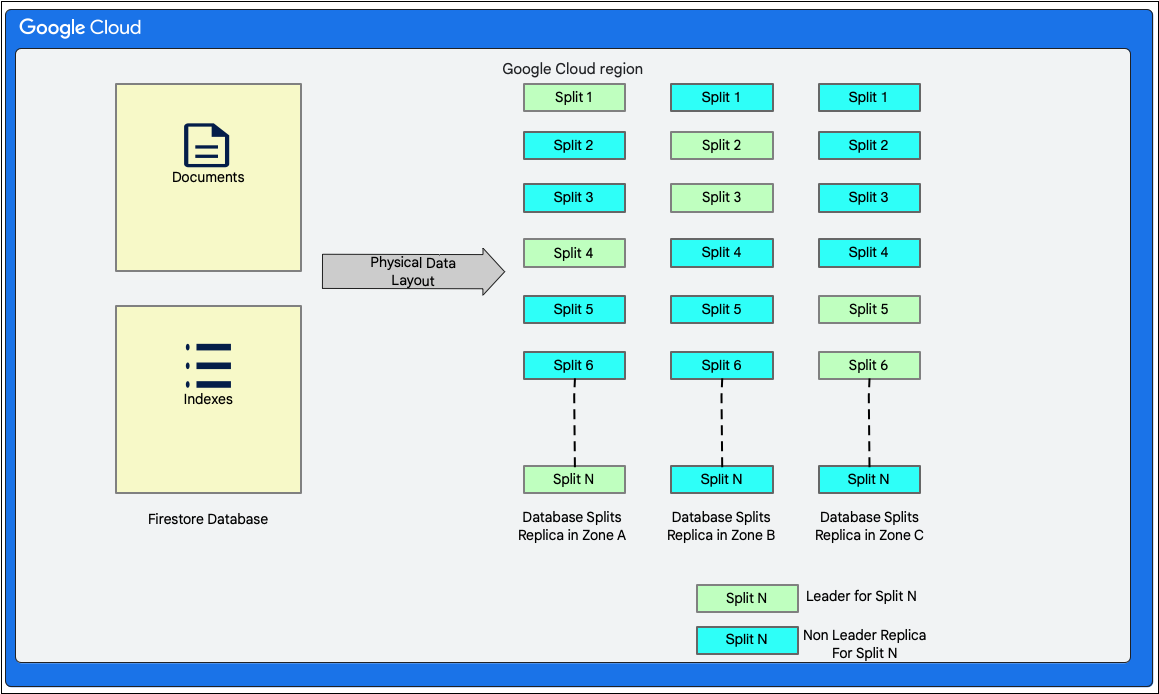
डेटा लेआउट
Cloud Firestore एक स्कीमालेस दस्तावेज़ डेटाबेस है. हालांकि, यह डेटा को मुख्य रूप से दो रिलेशनल डेटाबेस-स्टाइल टेबल में व्यवस्थित करता है. ये टेबल, स्टोरेज लेयर में इस तरह से व्यवस्थित होती हैं:
- दस्तावेज़ टेबल: इस टेबल में दस्तावेज़ सेव किए जाते हैं.
- इंडेक्स टेबल: इस टेबल में इंडेक्स एंट्री सेव की जाती हैं. इनकी मदद से, नतीजों को आसानी से और इंडेक्स वैल्यू के हिसाब से क्रम से लगाया जा सकता है.
इस डायग्राम में दिखाया गया है कि स्प्लिट करने के बाद, Cloud Firestore डेटाबेस की टेबल कैसी दिख सकती हैं. स्प्लिट को तीन अलग-अलग ज़ोन में दोहराया जाता है. साथ ही, हर स्प्लिट को Paxos लीडर असाइन किया जाता है.
एक क्षेत्र बनाम कई क्षेत्र
डेटाबेस बनाते समय, आपको कोई रीजन या मल्टी-रीजन चुनना होगा.
एक क्षेत्रीय जगह, कोई खास भौगोलिक जगह होती है. जैसे, us-west1. Cloud Firestore डेटाबेस के डेटा को अलग-अलग हिस्सों में बांटा जाता है. इन हिस्सों की रेप्लिका, चुने गए इलाके के अलग-अलग ज़ोन में मौजूद होती हैं. इसके बारे में ऊपर बताया गया है.
एक से ज़्यादा क्षेत्रों वाली जगह में, क्षेत्रों का एक ऐसा सेट होता है जहां डेटाबेस की रेप्लिका सेव की जाती हैं. Cloud Firestore को एक से ज़्यादा क्षेत्रों में डिप्लॉय करने पर, दो क्षेत्रों में डेटाबेस के पूरे डेटा के फ़ुल रेप्लिका होते हैं. तीसरे क्षेत्र में विटनेस रेप्लिका है. यह डेटा का पूरा सेट बनाए नहीं रखता, लेकिन रेप्लिकेशन में हिस्सा लेता है. डेटा को एक से ज़्यादा क्षेत्रों में कॉपी करने से, किसी एक क्षेत्र में डेटा उपलब्ध न होने पर भी, डेटा को लिखा और पढ़ा जा सकता है.
किसी इलाके की जगहों के बारे में ज़्यादा जानने के लिए, Cloud Firestore जगहें देखें.

Cloud Firestore में किसी फ़ाइल के लिखे जाने की प्रोसेस के बारे में जानकारी
Cloud Firestore क्लाइंट, एक दस्तावेज़ बनाकर, उसे अपडेट करके या मिटाकर डेटा लिख सकता है. किसी एक दस्तावेज़ में लिखने के लिए, दस्तावेज़ और उससे जुड़ी इंडेक्स एंट्री, दोनों को स्टोरेज लेयर में एक साथ अपडेट करना ज़रूरी होता है. Cloud Firestore, ऐटॉमिक ऑपरेशनों के साथ भी काम करता है. इनमें एक या एक से ज़्यादा दस्तावेज़ों को कई बार पढ़ा और/या लिखा जाता है.
सभी तरह के राइट ऑपरेशन के लिए, Cloud Firestore, रिलेशनल डेटाबेस की ACID प्रॉपर्टी (एटॉमिसिटी, कंसिस्टेंसी, आइसोलेशन, और ड्यूरेबिलिटी) उपलब्ध कराता है. Cloud Firestore सीरियलाइज़ेबिलिटी भी उपलब्ध कराता है. इसका मतलब है कि सभी लेन-देन, सीरियल ऑर्डर में किए गए दिखते हैं.
राइट लेन-देन के मुख्य चरण
जब Cloud Firestore क्लाइंट, ऊपर बताए गए किसी भी तरीके का इस्तेमाल करके, कोई लेन-देन लिखता है या करता है, तो स्टोरेज लेयर में इसे डेटाबेस रीड-राइट लेन-देन के तौर पर लागू किया जाता है. इस लेन-देन की वजह से, Cloud Firestore को पहले बताई गई ACID प्रॉपर्टी उपलब्ध कराने में मदद मिलती है.
लेन-देन के पहले चरण में, Cloud Firestore मौजूदा दस्तावेज़ को पढ़ता है. साथ ही, यह तय करता है कि Documents टेबल में मौजूद डेटा में कौनसे बदलाव करने हैं.
इसमें इंडेक्स टेबल में ज़रूरी अपडेट करना भी शामिल है. जैसे:
- दस्तावेज़ों में जोड़े जा रहे फ़ील्ड के लिए, इंडेक्स टेबल में उनसे जुड़े इंसर्ट होने चाहिए.
- दस्तावेज़ों से हटाए जा रहे फ़ील्ड के लिए, इंडेक्स टेबल में मौजूद फ़ील्ड को भी हटाना होगा.
- दस्तावेज़ों में जिन फ़ील्ड में बदलाव किया जा रहा है उनके लिए, इंडेक्स टेबल में पुरानी वैल्यू को मिटाने और नई वैल्यू डालने, दोनों की ज़रूरत होती है.
ऊपर बताए गए बदलावों का हिसाब लगाने के लिए, Cloud Firestore प्रोजेक्ट के इंडेक्सिंग कॉन्फ़िगरेशन को पढ़ता है. इंडेक्सिंग कॉन्फ़िगरेशन, किसी प्रोजेक्ट के इंडेक्स के बारे में जानकारी सेव करता है. Cloud Firestore दो तरह के इंडेक्स का इस्तेमाल करता है: सिंगल-फ़ील्ड और कंपोज़िट. Cloud Firestore में बनाए गए इंडेक्स के बारे में ज़्यादा जानने के लिए, Cloud Firestore में इंडेक्स के टाइप लेख पढ़ें.
म्यूटेशन का हिसाब लगाने के बाद, Cloud Firestore उन्हें एक लेन-देन में इकट्ठा करता है. इसके बाद, उन्हें लागू करता है.
स्टोरेज लेयर में राइट ट्रांज़ैक्शन को समझना
जैसा कि हमने पहले बताया था, Cloud Firestore में लिखने के लिए, स्टोरेज लेयर में रीड-राइट लेन-देन करना पड़ता है. डेटा के लेआउट के आधार पर, राइट में एक या उससे ज़्यादा स्प्लिट शामिल हो सकते हैं. इन्हें डेटा लेआउट में देखा जा सकता है.
नीचे दिए गए डायग्राम में, Cloud Firestore डेटाबेस को आठ हिस्सों (1 से 8 के तौर पर मार्क किया गया) में बांटा गया है. ये हिस्से, एक ही ज़ोन में तीन अलग-अलग स्टोरेज सर्वर पर होस्ट किए जाते हैं. साथ ही, हर हिस्से को तीन(या इससे ज़्यादा) अलग-अलग ज़ोन में दोहराया जाता है. हर स्प्लिट में एक Paxos लीडर होता है. यह अलग-अलग स्प्लिट के लिए अलग-अलग ज़ोन में हो सकता है.
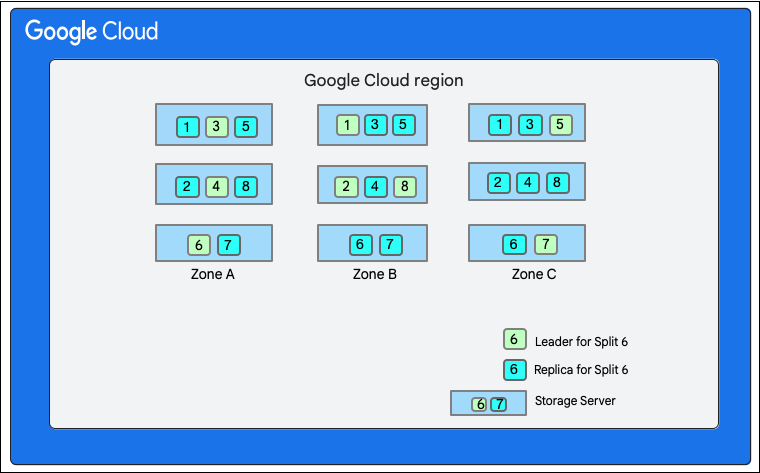 Cloud Firestore डेटाबेस को स्प्लिट करना">
Cloud Firestore डेटाबेस को स्प्लिट करना">
मान लें कि आपके पास एक Cloud Firestore डेटाबेस है, जिसमें Restaurants कलेक्शन इस तरह है:
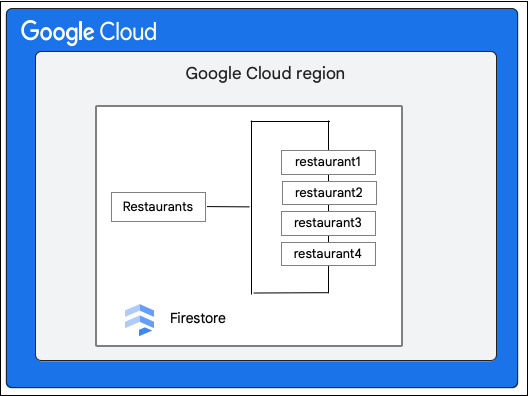
Cloud Firestore क्लाइंट, priceCategory फ़ील्ड की वैल्यू अपडेट करके, Restaurant कलेक्शन में मौजूद किसी दस्तावेज़ में यह बदलाव करने का अनुरोध करता है.
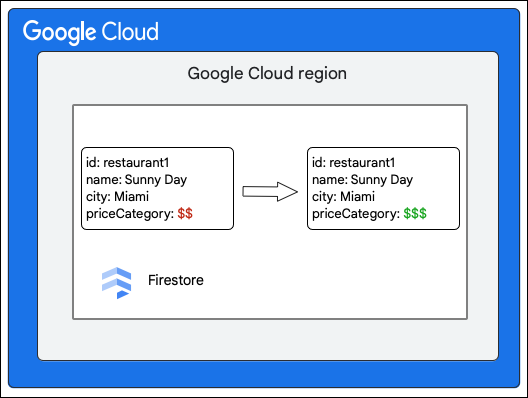
यहां दिए गए चरणों में, राइट ऑपरेशन के दौरान होने वाली प्रोसेस के बारे में बताया गया है:
- पढ़ने और लिखने का लेन-देन बनाएं.
- स्टोरेज लेयर में मौजूद दस्तावेज़ टेबल से,
Restaurantsकलेक्शन में मौजूदrestaurant1दस्तावेज़ को पढ़ें. - Indexes टेबल से, दस्तावेज़ के इंडेक्स पढ़ें.
- डेटा में किए जाने वाले बदलावों का हिसाब लगाएं. इस मामले में, पाँच म्यूटेशन हैं:
- M1:
priceCategoryफ़ील्ड की वैल्यू में हुए बदलाव को दिखाने के लिए, दस्तावेज़ टेबल मेंrestaurant1की लाइन को अपडेट करें. - M2 और M3: डिसेंडिंग और असेंडिंग इंडेक्स के लिए, Indexes टेबल में
priceCategoryकी पुरानी वैल्यू वाली लाइनें मिटाएं. - M4 और M5: डिसेंडिंग और असेंडिंग इंडेक्स के लिए, Indexes टेबल में
priceCategoryकी नई वैल्यू के लिए पंक्तियां डालें.
- M1:
- इन म्यूटेशन को कमिट करें.
Cloud Firestore सेवा में मौजूद स्टोरेज क्लाइंट, उन स्प्लिट को ढूंढता है जिनके पास बदली जाने वाली लाइनों की कुंजियां होती हैं. मान लें कि स्प्लिट 3, M1 को और स्प्लिट 6, M2 से M5 को टारगेट करता है. यह एक डिस्ट्रिब्यूटेड लेन-देन है, जिसमें ये सभी स्प्लिट भागीदार के तौर पर शामिल हैं. बंटवारे में शामिल लोगों के डेटा में, ऐसा कोई भी अन्य डेटा शामिल हो सकता है जिसे पहले पढ़ा गया था. ऐसा, पढ़ने और लिखने के लेन-देन के हिस्से के तौर पर किया गया था.
यहां दिए गए चरणों में बताया गया है कि कमिट करने के दौरान क्या होता है:
- स्टोरेज क्लाइंट, कमिट करने का अनुरोध भेजता है. इस कमिट में M1-M5 म्यूटेशन शामिल हैं.
- इस लेन-देन में स्प्लिट 3 और 6 शामिल हैं. मीटिंग में हिस्सा लेने वाले किसी व्यक्ति को कोऑर्डिनेटर के तौर पर चुना जाता है. जैसे, स्प्लिट 3. कोऑर्डिनेटर का काम यह पक्का करना है कि लेन-देन, सभी प्रतिभागियों के लिए एक साथ पूरा हो या एक साथ रद्द हो.
- इन स्प्लिट की लीडर रेप्लिका, हिस्सा लेने वाले लोगों और कोऑर्डिनेटर के काम के लिए ज़िम्मेदार होती हैं.
- मीटिंग में हिस्सा लेने वाला हर व्यक्ति और कोऑर्डिनेटर, अपनी-अपनी रेप्लिका के साथ Paxos एल्गोरिदम चलाता है.
- लीडर, रेप्लिका के साथ Paxos एल्गोरिदम चलाता है. अगर ज़्यादातर रेप्लिका, लीडर को
ok to commitरिस्पॉन्स भेजते हैं, तो कोरम पूरा हो जाता है. - इसके बाद, हर भागीदार कोऑर्डिनेटर को सूचना देता है कि वह तैयार है (दो-फ़ेज़ कमिट का पहला फ़ेज़). अगर कोई भी व्यक्ति लेन-देन पूरा नहीं कर पाता है, तो पूरा लेन-देन
aborts.
- लीडर, रेप्लिका के साथ Paxos एल्गोरिदम चलाता है. अगर ज़्यादातर रेप्लिका, लीडर को
- जब कोऑर्डिनेटर को पता चल जाता है कि सभी पक्ष (खुद भी) तैयार हैं, तो वह सभी पक्षों को
acceptलेन-देन के नतीजे के बारे में बताता है. यह दो चरणों में होने वाले कमिट का दूसरा चरण होता है. इस फ़ेज़ में, हर व्यक्ति कमिट करने के फ़ैसले को स्टेबल स्टोरेज में रिकॉर्ड करता है और लेन-देन कमिट हो जाता है. - कोऑर्डिनेटर, स्टोरेज क्लाइंट को Cloud Firestore में यह सूचना देता है कि लेन-देन पूरा हो गया है. इसके साथ ही, कोऑर्डिनेटर और सभी लोग डेटा में बदलाव करते हैं.

जब Cloud Firestore डेटाबेस छोटा होता है, तो ऐसा हो सकता है कि एक ही स्प्लिट में M1-M5 म्यूटेशन की सभी कुंजियां हों. ऐसे मामले में, लेन-देन में सिर्फ़ एक पक्ष शामिल होता है. इसलिए, पहले बताए गए दो फ़ेज़ वाले कमिट की ज़रूरत नहीं होती. इससे डेटा को तेज़ी से लिखा जा सकता है.
कई इलाकों में उपलब्ध है
एक से ज़्यादा क्षेत्रों में डिप्लॉयमेंट करने पर, अलग-अलग क्षेत्रों में रेप्लिका की संख्या बढ़ जाती है. इससे उपलब्धता बढ़ती है, लेकिन परफ़ॉर्मेंस पर असर पड़ता है. अलग-अलग क्षेत्रों में मौजूद रेप्लिका के बीच कम्यूनिकेशन में, राउंड ट्रिप में ज़्यादा समय लगता है. इसलिए, एक ही क्षेत्र में डिप्लॉयमेंट की तुलना में, Cloud Firestore कार्रवाइयों के लिए बेसलाइन लेटेन्सी थोड़ी ज़्यादा होती है.
हम रेप्लिका को इस तरह कॉन्फ़िगर करते हैं कि स्प्लिट के लिए लीडरशिप हमेशा प्राइमरी क्षेत्र में बनी रहे. प्राइमरी क्षेत्र वह होता है जहां से Cloud Firestore सर्वर को ट्रैफ़िक मिलता है. लीडरशिप के इस फ़ैसले से, Cloud Firestore में स्टोरेज क्लाइंट और रेप्लिका लीडर (या मल्टी-स्प्लिट लेन-देन के लिए कोऑर्डिनेटर) के बीच कम्यूनिकेशन में राउंड-ट्रिप में लगने वाला समय कम हो जाता है.
Cloud Firestore में हर राइट ऑपरेशन में, Cloud Firestore के रीयल-टाइम इंजन के साथ कुछ इंटरैक्शन भी शामिल होता है. रीयल-टाइम क्वेरी के बारे में ज़्यादा जानने के लिए, बड़े पैमाने पर रीयल-टाइम क्वेरी को समझना लेख पढ़ें.
Cloud Firestore में पढ़ने की सुविधा के बारे में जानकारी
इस सेक्शन में, Cloud Firestore में स्टैंडअलोन और नॉन-रीयलटाइम रीड के बारे में बताया गया है. Cloud Firestore सर्वर, इन क्वेरी को दो मुख्य चरणों में हैंडल करता है:
- Indexes टेबल पर सिंगल रेंज स्कैन
- दस्तावेज़ टेबल में, पहले के स्कैन के नतीजे के आधार पर पॉइंट लुकअप
स्टोरेज लेयर से डेटा को पढ़ने की प्रोसेस, अंदरूनी तौर पर डेटाबेस ट्रांज़ैक्शन का इस्तेमाल करके की जाती है. इससे यह पक्का किया जाता है कि डेटा को लगातार पढ़ा जा रहा है. हालांकि, राइट के लिए इस्तेमाल किए जाने वाले लेन-देन के उलट, ये लेन-देन लॉक नहीं करते. इसके बजाय, ये टाइमस्टैंप चुनकर काम करते हैं. इसके बाद, उस टाइमस्टैंप पर सभी रीड ऑपरेशन पूरे करते हैं. ये लॉक नहीं करते, इसलिए ये एक साथ रीड-राइट लेन-देन को ब्लॉक नहीं करते. इस लेन-देन को पूरा करने के लिए, स्टोरेज क्लाइंट Cloud Firestore टाइमस्टैंप बाउंड तय करता है. इससे स्टोरेज लेयर को यह पता चलता है कि रीड टाइमस्टैंप कैसे चुना जाए. Cloud Firestore में स्टोरेज क्लाइंट की ओर से चुना गया टाइमस्टैंप, Read अनुरोध के लिए रीड विकल्पों से तय होता है.
स्टोरेज लेयर में रीड ट्रांज़ैक्शन को समझना
इस सेक्शन में, रीड के टाइप और Cloud Firestore में स्टोरेज लेयर में उन्हें प्रोसेस करने के तरीके के बारे में बताया गया है.
बेहतरीन किताबें
डिफ़ॉल्ट रूप से, Cloud Firestore ज़्यादातर एक जैसे होते हैं. इसका मतलब है कि Cloud Firestore रीड करने पर, डेटा का सबसे नया वर्शन मिलता है. इसमें रीड करने की प्रोसेस शुरू होने तक किए गए सभी बदलाव शामिल होते हैं.
सिंगल स्प्लिट रीड
Cloud Firestore में मौजूद स्टोरेज क्लाइंट, उन स्प्लिट को ढूंढता है जिनके पास पढ़ी जाने वाली लाइनों की कुंजियां होती हैं. मान लें कि इसे पहले वाले सेक्शन से Split 3 को पढ़ना है. क्लाइंट, डेटा पढ़ने का अनुरोध सबसे नज़दीकी रेप्लिका को भेजता है, ताकि राउंड ट्रिप में लगने वाला समय कम हो.
इस समय, चुनी गई रेप्लिका के आधार पर ये स्थितियां हो सकती हैं:
- पढ़ने का अनुरोध, लीडर रेप्लिका (ज़ोन A) को भेजा जाता है.
- लीडर हमेशा अप-टू-डेट रहता है. इसलिए, रीड ऑपरेशन सीधे तौर पर किया जा सकता है.
- पढ़ने का अनुरोध, लीडर रेप्लिका के बजाय किसी दूसरी रेप्लिका (जैसे, ज़ोन B) को भेजा जाता है
- स्प्लिट 3 को अपनी इंटरनल स्थिति से पता चल सकता है कि उसके पास पढ़ने के लिए ज़रूरी जानकारी है. इसलिए, वह ऐसा करता है.
- स्प्लिट 3 को यह पक्का नहीं है कि उसे नया डेटा मिला है या नहीं. यह लीडर को एक मैसेज भेजता है. इसमें, लीडर से उस आखिरी लेन-देन का टाइमस्टैंप मांगा जाता है जिसे रीड करने के लिए लागू करना है. वह लेन-देन लागू होने के बाद, कार्ड को पढ़ा जा सकता है.
Cloud Firestore इसके बाद, यह अपने क्लाइंट को जवाब भेजता है.
मल्टी-स्प्लिट रीड
अगर कई स्प्लिट से डेटा पढ़ा जाना है, तो यह प्रोसेस सभी स्प्लिट में एक जैसी होती है. जब सभी स्प्लिट से डेटा मिल जाता है, तब Cloud Firestore में मौजूद स्टोरेज क्लाइंट, नतीजों को एक साथ जोड़ देता है. इसके बाद, Cloud Firestore इस डेटा के साथ अपने क्लाइंट को जवाब देता है.
पुरानी जानकारी
Cloud Firestore में, स्ट्रॉन्ग रीड डिफ़ॉल्ट मोड होता है. हालांकि, इसमें लीडर के साथ कम्यूनिकेट करने की ज़रूरत पड़ सकती है. इस वजह से, लेटेन्सी बढ़ सकती है. अक्सर, आपके Cloud Firestore ऐप्लिकेशन को डेटा के नए वर्शन को पढ़ने की ज़रूरत नहीं होती है. साथ ही, यह कुछ सेकंड पुराने डेटा के साथ भी अच्छी तरह काम करता है.
ऐसे मामले में, क्लाइंट read_time रीड विकल्प का इस्तेमाल करके, पुरानी जानकारी पाने का विकल्प चुन सकता है. इस मामले में, डेटा को read_time के हिसाब से पढ़ा जाता है. साथ ही, सबसे मिलते-जुलते रेप्लिका की पुष्टि पहले ही हो चुकी होती है कि उसमें read_time के हिसाब से डेटा मौजूद है.
बेहतर परफ़ॉर्मेंस के लिए, 15 सेकंड पुरानी वैल्यू का इस्तेमाल करना सही है. यहां तक कि पुरानी जानकारी को पढ़ने के लिए भी, दिखाई गई लाइनें एक-दूसरे से मेल खाती हैं.
हॉटस्पॉट से बचें
Cloud Firestore में मौजूद स्प्लिट को अपने-आप छोटे-छोटे हिस्सों में बांट दिया जाता है. इससे, ज़रूरत पड़ने पर या कुंजी स्पेस बढ़ने पर, ज़्यादा स्टोरेज सर्वर को ट्रैफ़िक मैनेज करने का काम सौंपा जा सकता है. ज़्यादा ट्रैफ़िक को मैनेज करने के लिए बनाए गए स्प्लिट, ट्रैफ़िक कम होने के बाद भी ~24 घंटे तक बने रहते हैं. इसलिए, अगर ट्रैफ़िक में बार-बार अचानक बढ़ोतरी होती है, तो स्प्लिट को बनाए रखा जाता है. साथ ही, जब भी ज़रूरत होती है, तब ज़्यादा स्प्लिट जोड़े जाते हैं. इन तरीकों से, Cloud Firestore डेटाबेस को ट्रैफ़िक लोड या डेटाबेस के साइज़ के हिसाब से अपने-आप स्केल करने में मदद मिलती है. हालांकि, इसके लिए कुछ सीमाएं तय की गई हैं. इनके बारे में यहां बताया गया है.
स्टोरेज और लोड को अलग-अलग करने में समय लगता है. साथ ही, ट्रैफ़िक को बहुत तेज़ी से बढ़ाने पर, ज़्यादा इंतज़ार करना पड़ सकता है या समयसीमा खत्म होने की गड़बड़ियां हो सकती हैं. इन्हें आम तौर पर हॉटस्पॉट कहा जाता है. ऐसा तब होता है, जब सेवा में बदलाव किया जा रहा हो. सबसे सही तरीका यह है कि मुख्य रेंज में कार्रवाइयों को डिस्ट्रिब्यूट किया जाए. साथ ही, डेटाबेस में किसी कलेक्शन पर ट्रैफ़िक बढ़ाया जाए. इस डेटाबेस में हर सेकंड 500 कार्रवाइयां की जाती हैं. धीरे-धीरे ट्रैफ़िक बढ़ाने के बाद, हर पांच मिनट में ट्रैफ़िक को 50% तक बढ़ाएं. इस प्रोसेस को 500/50/5 नियम कहा जाता है. इससे डेटाबेस को इस तरह से सेट किया जाता है कि वह आपके वर्कलोड के हिसाब से सबसे सही तरीके से स्केल हो सके.
लोड बढ़ने पर स्प्लिट अपने-आप बन जाते हैं. हालांकि, Cloud Firestore किसी कुंजी की रेंज को सिर्फ़ तब तक स्प्लिट कर सकता है, जब तक वह रेप्लिका स्टोरेज सर्वर के डेडीकेटेड सेट का इस्तेमाल करके किसी एक दस्तावेज़ को दिखाता है. इस वजह से, किसी एक दस्तावेज़ पर एक साथ कई कार्रवाइयां करने से, उस दस्तावेज़ पर हॉटस्पॉट बन सकता है. अगर आपको किसी एक दस्तावेज़ में लगातार ज़्यादा समय लग रहा है, तो आपको अपने डेटा मॉडल में बदलाव करना चाहिए. इससे डेटा को कई दस्तावेज़ों में बांटा या डुप्लीकेट किया जा सकेगा.
जब कई कार्रवाइयां एक ही दस्तावेज़ को एक साथ पढ़ने और/या लिखने की कोशिश करती हैं, तब कंटेंशन से जुड़ी गड़बड़ियां होती हैं.
हॉटस्पॉटिंग का एक और खास उदाहरण तब होता है, जब Cloud Firestore में दस्तावेज़ आईडी के तौर पर, क्रम से बढ़ने/घटने वाली कुंजी का इस्तेमाल किया जाता है. साथ ही, हर सेकंड में काफ़ी ज़्यादा कार्रवाइयां की जाती हैं. ज़्यादा स्प्लिट बनाने से कोई फ़ायदा नहीं होता, क्योंकि ट्रैफ़िक में अचानक हुई बढ़ोतरी, नए स्प्लिट पर चली जाती है. Cloud Firestore डिफ़ॉल्ट रूप से, दस्तावेज़ के सभी फ़ील्ड को अपने-आप इंडेक्स करता है. इसलिए, इस तरह के मूविंग हॉटस्पॉट, दस्तावेज़ के ऐसे फ़ील्ड के इंडेक्स स्पेस पर भी बनाए जा सकते हैं जिनमें क्रम से बढ़ती/घटती वैल्यू होती है. जैसे, टाइमस्टैंप.
ध्यान दें कि ऊपर बताए गए तरीकों को अपनाने से, Cloud Firestore को किसी भी कॉन्फ़िगरेशन में बदलाव किए बिना, बड़े वर्कलोड को मैनेज करने के लिए स्केल किया जा सकता है.
समस्या का हल
Cloud Firestore, Key Visualizer को डाइग्नोस्टिक्स टूल के तौर पर उपलब्ध कराता है. इसे इस्तेमाल के पैटर्न का विश्लेषण करने और हॉटस्पॉटिंग से जुड़ी समस्याओं को हल करने के लिए डिज़ाइन किया गया है.
आगे क्या करना है
- सबसे सही तरीकों के बारे में ज़्यादा जानें
- बड़े पैमाने पर रीयल-टाइम क्वेरी के बारे में जानें