
Hãy đọc tài liệu này để đưa ra quyết định sáng suốt về việc thiết kế ứng dụng của bạn nhằm đạt được hiệu suất và độ tin cậy cao. Tài liệu này bao gồm các chủ đề Cloud Firestore nâng cao. Nếu bạn chỉ mới bắt đầu sử dụng Cloud Firestore, hãy xem hướng dẫn bắt đầu nhanh.
Cloud Firestore là một cơ sở dữ liệu linh hoạt, có thể mở rộng để phát triển thiết bị di động, web và máy chủ từ Firebase và Google Cloud. Bạn có thể dễ dàng bắt đầu sử dụng Cloud Firestore và viết các ứng dụng phong phú và mạnh mẽ.
Để đảm bảo các ứng dụng của bạn tiếp tục hoạt động hiệu quả khi kích thước cơ sở dữ liệu và lưu lượng truy cập tăng lên, bạn nên hiểu rõ cơ chế đọc và ghi trong phần phụ trợ Cloud Firestore. Bạn cũng phải hiểu được tương tác giữa các thao tác đọc và ghi với lớp lưu trữ cũng như các ràng buộc cơ bản có thể ảnh hưởng đến hiệu suất.
Hãy xem các phần sau để biết các phương pháp hay nhất trước khi thiết kế ứng dụng của bạn.
Tìm hiểu các thành phần cấp cao
Sơ đồ sau đây cho thấy các thành phần cấp cao liên quan đến một yêu cầu API Cloud Firestore.
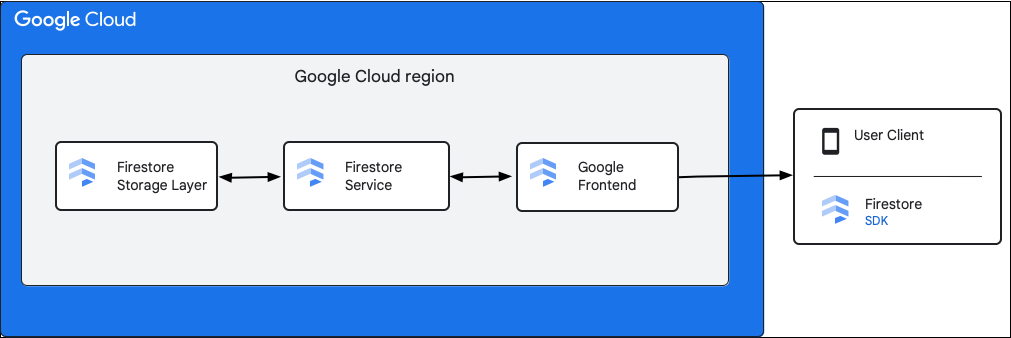
Cloud Firestore SDK và thư viện ứng dụng
Cloud Firestore hỗ trợ SDK và thư viện ứng dụng cho nhiều nền tảng. Mặc dù ứng dụng có thể thực hiện các lệnh gọi HTTP và RPC trực tiếp đến API Cloud Firestore, nhưng các thư viện ứng dụng cung cấp một lớp trừu tượng để đơn giản hoá việc sử dụng API và triển khai các phương pháp hay nhất. Các ứng dụng này cũng có thể cung cấp các tính năng bổ sung như truy cập ngoại tuyến, bộ nhớ đệm, v.v.
Google Front End (GFE)
Đây là một dịch vụ cơ sở hạ tầng phổ biến cho tất cả các dịch vụ đám mây của Google. GFE chấp nhận các yêu cầu đến và chuyển tiếp các yêu cầu đó đến dịch vụ Google có liên quan (dịch vụ Cloud Firestore trong trường hợp này). CDN của chúng tôi cũng cung cấp các chức năng quan trọng khác, bao gồm cả biện pháp bảo vệ chống lại các cuộc tấn công Từ chối dịch vụ.
Cloud Firestore dịch vụ
Dịch vụ Cloud Firestore thực hiện các bước kiểm tra đối với yêu cầu API, bao gồm cả xác thực, uỷ quyền, kiểm tra hạn mức và quy tắc bảo mật, đồng thời quản lý các giao dịch. Dịch vụ Cloud Firestore này bao gồm một ứng dụng lưu trữ tương tác với lớp lưu trữ để đọc và ghi dữ liệu.
Lớp lưu trữ Cloud Firestore
Lớp lưu trữ Cloud Firestore chịu trách nhiệm lưu trữ cả dữ liệu và siêu dữ liệu, cũng như các tính năng cơ sở dữ liệu liên kết do Cloud Firestore cung cấp. Các phần sau đây mô tả cách dữ liệu được sắp xếp trong lớp lưu trữ Cloud Firestore và cách hệ thống mở rộng quy mô. Việc tìm hiểu cách sắp xếp dữ liệu có thể giúp bạn thiết kế một mô hình dữ liệu có khả năng mở rộng và hiểu rõ hơn về các phương pháp hay nhất trong Cloud Firestore.
Dải khoá và phân chia
Cloud Firestore là một cơ sở dữ liệu NoSQL, hướng đến tài liệu. Bạn lưu trữ dữ liệu trong tài liệu, được sắp xếp theo hệ thống phân cấp của các bộ sưu tập. Hệ thống sẽ dịch hệ thống phân cấp bộ sưu tập và mã nhận dạng tài liệu thành một khoá duy nhất cho mỗi tài liệu. Các tài liệu được lưu trữ một cách hợp lý và sắp xếp theo thứ tự từ điển bằng khoá duy nhất này. Chúng tôi sử dụng thuật ngữ dải khoá để chỉ một dải khoá liền kề theo thứ tự từ điển.
Một cơ sở dữ liệu Cloud Firestore thông thường có kích thước quá lớn để có thể nằm trên một máy vật lý duy nhất. Ngoài ra, cũng có những trường hợp mà khối lượng công việc trên dữ liệu quá lớn để một máy có thể xử lý. Để xử lý khối lượng công việc lớn, Cloud Firestore phân vùng dữ liệu thành các phần riêng biệt có thể được lưu trữ và phân phát từ nhiều máy hoặc máy chủ lưu trữ. Các phân vùng này được tạo trên các bảng cơ sở dữ liệu theo các khối dải khoá được gọi là phân tách.
Sao chép đồng bộ
Điều quan trọng cần lưu ý là cơ sở dữ liệu luôn được sao chép tự động và đồng bộ. Các phân vùng dữ liệu có bản sao ở nhiều vùng để luôn có sẵn ngay cả khi một vùng không truy cập được. Việc sao chép nhất quán vào các bản sao khác nhau của phân vùng được quản lý bằng thuật toán Paxos để đạt được sự đồng thuận. Một bản sao của mỗi phân vùng được chọn làm Paxos leader, chịu trách nhiệm xử lý các thao tác ghi vào phân vùng đó. Tính năng sao chép đồng bộ cho phép bạn luôn có thể đọc phiên bản mới nhất của dữ liệu từ Cloud Firestore.
Kết quả tổng thể là một hệ thống có khả năng mở rộng và tính sẵn sàng cao, cung cấp độ trễ thấp cho cả hoạt động đọc và ghi, bất kể khối lượng công việc lớn và ở quy mô rất lớn.
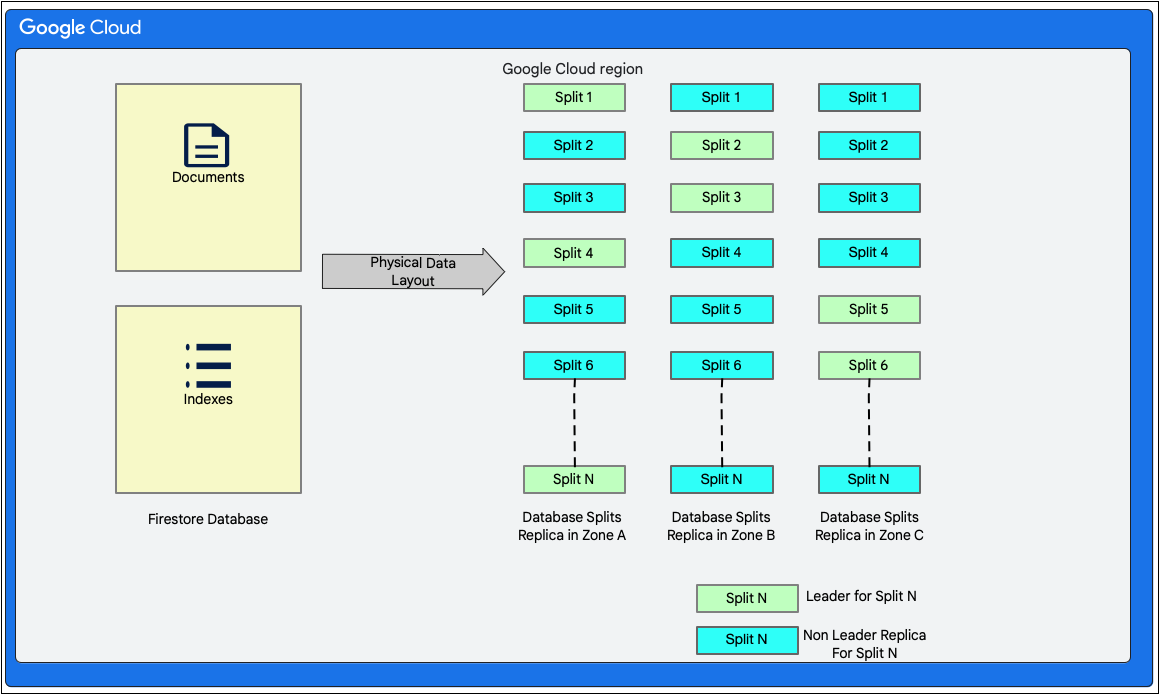
Bố cục dữ liệu
Cloud Firestore là một cơ sở dữ liệu tài liệu không có lược đồ. Tuy nhiên, về nội bộ, nó chủ yếu bố trí dữ liệu trong 2 bảng theo kiểu cơ sở dữ liệu quan hệ trong lớp lưu trữ như sau:
- Bảng Tài liệu: Tài liệu được lưu trữ trong bảng này.
- Bảng Chỉ mục: Các mục chỉ mục giúp bạn có thể nhận được kết quả một cách hiệu quả và được sắp xếp theo giá trị chỉ mục sẽ được lưu trữ trong bảng này.
Sơ đồ sau đây cho thấy các bảng của cơ sở dữ liệu Cloud Firestore có thể trông như thế nào khi có các phần tách. Các phân vùng được sao chép ở 3 khu vực khác nhau và mỗi phân vùng có một Paxos leader được chỉ định.
Một khu vực so với nhiều khu vực
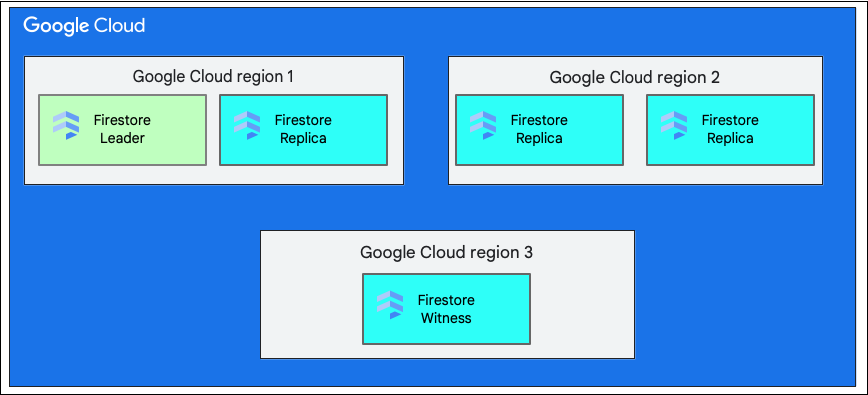
Khi tạo cơ sở dữ liệu, bạn phải chọn một khu vực hoặc nhiều khu vực.
Một vị trí theo khu vực là một vị trí địa lý cụ thể, chẳng hạn như us-west1. Các phân vùng dữ liệu của cơ sở dữ liệu Cloud Firestore có các bản sao ở nhiều vùng trong khu vực đã chọn, như đã giải thích trước đó.
Vị trí đa khu vực bao gồm một nhóm khu vực được xác định, nơi lưu trữ các bản sao của cơ sở dữ liệu. Trong quá trình triển khai Cloud Firestore ở nhiều khu vực, hai trong số các khu vực có bản sao đầy đủ của toàn bộ dữ liệu trong cơ sở dữ liệu. Vùng thứ ba có một bản sao chứng kiến không duy trì một tập hợp dữ liệu đầy đủ, nhưng tham gia vào quá trình sao chép. Bằng cách nhân bản dữ liệu giữa nhiều khu vực, dữ liệu có thể được ghi và đọc ngay cả khi mất toàn bộ một khu vực.
Để biết thêm thông tin về các vị trí của một khu vực, hãy xem các vị trí Cloud Firestore.
Tìm hiểu vòng đời của một thao tác ghi trong Cloud Firestore
Ứng dụng Cloud Firestore có thể ghi dữ liệu bằng cách tạo, cập nhật hoặc xoá một tài liệu duy nhất. Thao tác ghi vào một tài liệu duy nhất yêu cầu cập nhật cả tài liệu và các mục nhập chỉ mục được liên kết một cách nguyên tử trong lớp lưu trữ. Cloud Firestore cũng hỗ trợ các thao tác nguyên tử bao gồm nhiều lượt đọc và/hoặc ghi vào một hoặc nhiều tài liệu.
Đối với mọi loại hoạt động ghi, Cloud Firestore cung cấp các thuộc tính ACID (tính nguyên tố, tính nhất quán, tính độc lập và tính bền vững) của cơ sở dữ liệu quan hệ. Cloud Firestore cũng cung cấp khả năng tuần tự hoá, nghĩa là tất cả các giao dịch đều xuất hiện như thể được thực thi theo thứ tự tuần tự.
Các bước cấp cao trong một giao dịch ghi
Khi ứng dụng Cloud Firestore đưa ra một thao tác ghi hoặc xác nhận một giao dịch bằng cách sử dụng bất kỳ phương thức nào đã đề cập trước đó, thì thao tác này sẽ được thực thi nội bộ dưới dạng một giao dịch đọc-ghi cơ sở dữ liệu trong lớp lưu trữ. Giao dịch này cho phép Cloud Firestore cung cấp các thuộc tính ACID đã đề cập trước đó.
Là bước đầu tiên của một giao dịch, Cloud Firestore sẽ đọc tài liệu hiện có và xác định những thay đổi cần thực hiện đối với dữ liệu trong bảng Tài liệu.
Điều này cũng bao gồm việc thực hiện các nội dung cập nhật cần thiết cho bảng Chỉ mục như sau:
- Các trường được thêm vào tài liệu cần có các mục chèn tương ứng trong bảng Chỉ mục.
- Các trường bị xoá khỏi tài liệu cần có các thao tác xoá tương ứng trong bảng Chỉ mục.
- Các trường đang được sửa đổi trong tài liệu cần cả thao tác xoá (đối với giá trị cũ) và thao tác chèn (đối với giá trị mới) trong bảng Chỉ mục.
Để tính toán các đột biến đã đề cập trước đó, Cloud Firestore sẽ đọc cấu hình lập chỉ mục cho dự án. Cấu hình lập chỉ mục lưu trữ thông tin về các chỉ mục cho một dự án. Cloud Firestore sử dụng hai loại chỉ mục: chỉ mục một trường và chỉ mục kết hợp. Để hiểu rõ về các chỉ mục được tạo trong Cloud Firestore, hãy xem phần Các loại chỉ mục trong Cloud Firestore.
Sau khi tính toán các đột biến, Cloud Firestore sẽ thu thập các đột biến đó trong một giao dịch rồi xác nhận giao dịch.
Tìm hiểu về giao dịch ghi trong lớp lưu trữ
Như đã thảo luận trước đó, thao tác ghi trong Cloud Firestore liên quan đến một giao dịch đọc-ghi trong lớp lưu trữ. Tuỳ thuộc vào bố cục dữ liệu, một thao tác ghi có thể liên quan đến một hoặc nhiều lần phân chia như trong bố cục dữ liệu.
Trong sơ đồ sau, cơ sở dữ liệu Cloud Firestore có 8 phân vùng (được đánh dấu từ 1 đến 8) được lưu trữ trên 3 máy chủ lưu trữ khác nhau trong một vùng duy nhất và mỗi phân vùng được sao chép ở 3(hoặc nhiều) vùng khác nhau. Mỗi phân vùng có một Paxos leader, có thể nằm ở một vùng khác cho các phân vùng khác nhau.
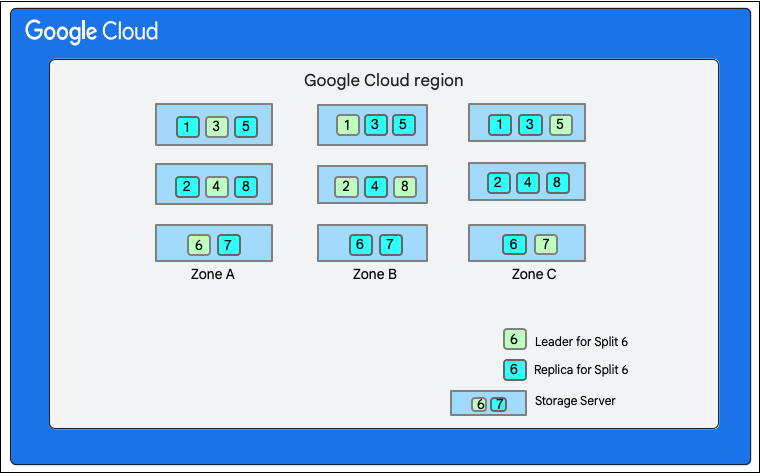 Phân chia cơ sở dữ liệu Cloud Firestore">
Phân chia cơ sở dữ liệu Cloud Firestore">
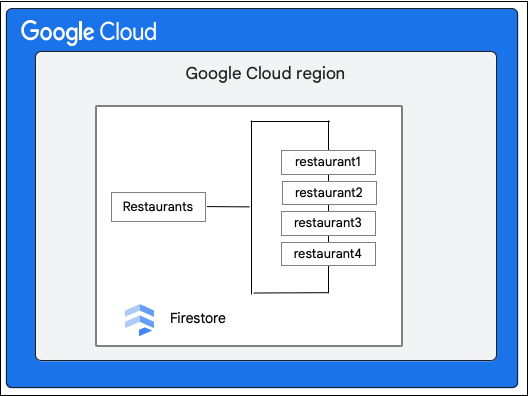
Hãy xem xét một cơ sở dữ liệu Cloud Firestore có tập hợp Restaurants như sau:
Ứng dụng Cloud Firestore yêu cầu thay đổi sau đây đối với một tài liệu trong tập hợp Restaurant bằng cách cập nhật giá trị của trường priceCategory.
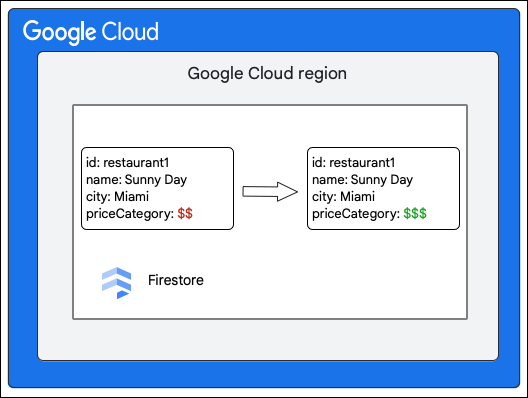
Sau đây là các bước cấp cao mô tả những gì xảy ra trong quá trình ghi:
- Tạo một giao dịch đọc-ghi.
- Đọc tài liệu
restaurant1trong tập hợpRestaurantstừ bảng Documents trong lớp lưu trữ. - Đọc các chỉ mục cho tài liệu trong bảng Chỉ mục.
- Tính toán các thay đổi cần thực hiện đối với dữ liệu. Trong trường hợp này, có 5 đột biến:
- M1: Cập nhật hàng cho
restaurant1trong bảng Tài liệu để phản ánh sự thay đổi về giá trị của trườngpriceCategory. - M2 và M3: Xoá các hàng cho giá trị cũ của
priceCategorytrong bảng Indexes (Chỉ mục) cho chỉ mục giảm dần và tăng dần. - M4 và M5: Chèn các hàng cho giá trị mới của
priceCategorytrong bảng Chỉ mục cho chỉ mục giảm dần và tăng dần.
- M1: Cập nhật hàng cho
- Xác nhận những thay đổi này.
Ứng dụng lưu trữ trong dịch vụ Cloud Firestore sẽ tra cứu các phân vùng sở hữu khoá của những hàng cần thay đổi. Hãy xem xét trường hợp mà Nhóm 3 phân phát M1 và Nhóm 6 phân phát M2 – M5. Có một giao dịch phân tán, liên quan đến tất cả các phần chia tách này với tư cách là người tham gia. Các phân vùng của người tham gia cũng có thể bao gồm mọi phân vùng khác mà dữ liệu đã được đọc trước đó trong giao dịch đọc-ghi.
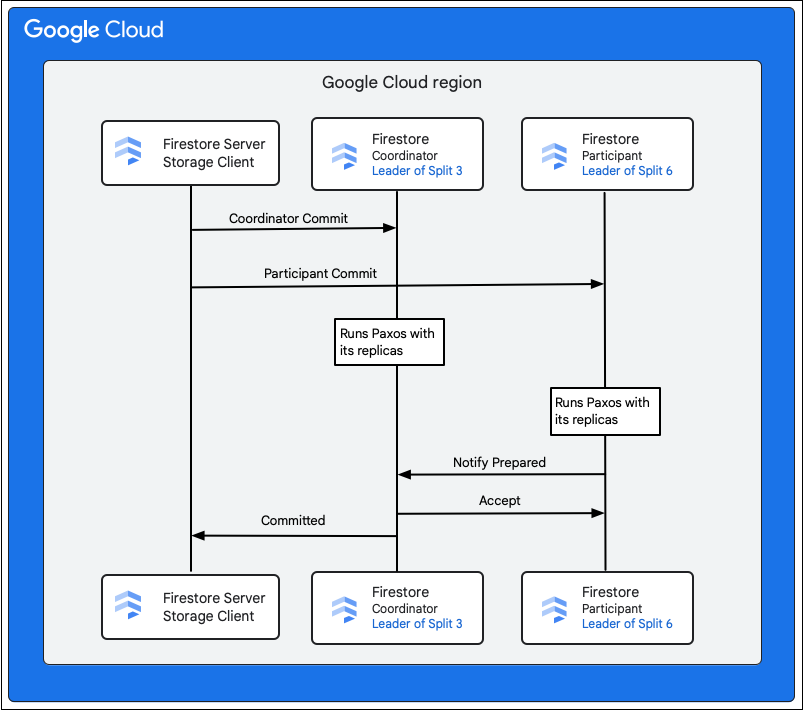
Các bước sau đây mô tả những gì xảy ra trong quá trình xác nhận:
- Ứng dụng lưu trữ sẽ đưa ra một lệnh cam kết. Cam kết này chứa các đột biến M1-M5.
- Người tham gia giao dịch này là người dùng 3 và 6. Một trong những người tham gia được chọn làm người điều phối, chẳng hạn như Split 3. Nhiệm vụ của trình điều phối là đảm bảo giao dịch được xác nhận hoặc huỷ bỏ một cách nguyên tử trên tất cả các bên tham gia.
- Các bản sao chính của những phân vùng này chịu trách nhiệm về công việc do người tham gia và người điều phối thực hiện.
- Mỗi người tham gia và điều phối viên chạy một thuật toán Paxos với các bản sao tương ứng của họ.
- Trưởng nhóm chạy thuật toán Paxos với các bản sao. Đạt được số lượng tối thiểu nếu hầu hết các bản sao đều trả lời bằng phản hồi
ok to commitcho bản sao chính. - Sau đó, mỗi người tham gia sẽ thông báo cho điều phối viên khi họ chuẩn bị (giai đoạn đầu của quy trình xác nhận hai giai đoạn). Nếu bất kỳ người tham gia nào không thể thực hiện giao dịch, toàn bộ giao dịch sẽ
aborts.
- Trưởng nhóm chạy thuật toán Paxos với các bản sao. Đạt được số lượng tối thiểu nếu hầu hết các bản sao đều trả lời bằng phản hồi
- Sau khi biết tất cả người tham gia (bao gồm cả chính nó) đã chuẩn bị xong, trình điều phối sẽ thông báo kết quả giao dịch
acceptcho tất cả người tham gia (giai đoạn thứ hai của quy trình xác nhận hai giai đoạn). Trong giai đoạn này, mỗi người tham gia sẽ ghi lại quyết định xác nhận vào bộ nhớ ổn định và giao dịch được xác nhận. - Trình điều phối phản hồi cho ứng dụng lưu trữ trong Cloud Firestore rằng giao dịch đã được xác nhận. Đồng thời, điều phối viên và tất cả những người tham gia sẽ áp dụng các đột biến cho dữ liệu.
Khi cơ sở dữ liệu Cloud Firestore có kích thước nhỏ, có thể xảy ra trường hợp một phân vùng duy nhất sở hữu tất cả các khoá trong các đột biến M1-M5. Trong trường hợp này, chỉ có một người tham gia giao dịch và không cần đến quy trình xác nhận hai giai đoạn đã đề cập trước đó, do đó, các thao tác ghi sẽ diễn ra nhanh hơn.
Ghi ở nhiều khu vực
Trong quá trình triển khai nhiều khu vực, việc phân tán các bản sao trên nhiều khu vực sẽ làm tăng khả năng hoạt động, nhưng sẽ làm giảm hiệu suất. Việc giao tiếp giữa các bản sao ở các khu vực khác nhau sẽ mất nhiều thời gian khứ hồi hơn. Do đó, độ trễ cơ sở cho các thao tác Cloud Firestore cao hơn một chút so với các hoạt động triển khai ở một khu vực.
Chúng tôi định cấu hình các bản sao theo cách mà quyền lãnh đạo cho các phân vùng luôn nằm ở khu vực chính. Khu vực chính là khu vực mà lưu lượng truy cập đến máy chủ Cloud Firestore. Quyết định này của nhóm lãnh đạo giúp giảm độ trễ khứ hồi trong quá trình giao tiếp giữa ứng dụng lưu trữ trong Cloud Firestore và bản sao chính (hoặc trình điều phối cho các giao dịch chia tách nhiều phần).
Mỗi thao tác ghi trong Cloud Firestore cũng liên quan đến một số hoạt động tương tác với công cụ theo thời gian thực trong Cloud Firestore. Để biết thêm thông tin về truy vấn theo thời gian thực, hãy xem bài viết Tìm hiểu về truy vấn theo thời gian thực ở quy mô lớn.
Tìm hiểu về thời gian đọc trong Cloud Firestore
Phần này đi sâu vào các lượt đọc độc lập, không theo thời gian thực trong Cloud Firestore. Về nội bộ, máy chủ Cloud Firestore xử lý hầu hết các truy vấn này trong hai giai đoạn chính:
- Một lần quét dải ô trên bảng Indexes
- Tra cứu điểm trong bảng Tài liệu dựa trên kết quả của lần quét trước
Dữ liệu đọc từ lớp lưu trữ được thực hiện nội bộ bằng cách sử dụng giao dịch cơ sở dữ liệu để đảm bảo việc đọc nhất quán. Tuy nhiên, không giống như các giao dịch dùng để ghi, những giao dịch này không lấy khoá. Thay vào đó, chúng hoạt động bằng cách chọn một dấu thời gian, sau đó thực hiện tất cả các thao tác đọc tại dấu thời gian đó. Vì không có được khoá nên các giao dịch đọc-ghi đồng thời sẽ không bị chặn. Để thực thi giao dịch này, ứng dụng lưu trữ trong Cloud Firestore chỉ định một giới hạn dấu thời gian, cho biết lớp lưu trữ cách chọn dấu thời gian đọc. Loại dấu thời gian ràng buộc mà ứng dụng lưu trữ chọn trong Cloud Firestore được xác định bằng các lựa chọn đọc cho yêu cầu Đọc.
Tìm hiểu về giao dịch đọc trong lớp lưu trữ
Phần này mô tả các loại thao tác đọc và cách chúng được xử lý trong lớp lưu trữ trong Cloud Firestore.
Đọc nhiều
Theo mặc định, các thao tác đọc Cloud Firestore có tính nhất quán cao. Tính nhất quán mạnh mẽ này có nghĩa là thao tác đọc Cloud Firestore sẽ trả về phiên bản mới nhất của dữ liệu, phản ánh tất cả các thao tác ghi đã được thực hiện cho đến khi bắt đầu thao tác đọc.
Đọc một lần
Ứng dụng lưu trữ trong Cloud Firestore sẽ tìm các phân vùng sở hữu khoá của những hàng cần đọc. Giả sử rằng nó cần đọc từ Phân vùng 3 trong phần trước đó. Ứng dụng gửi yêu cầu đọc đến bản sao gần nhất để giảm độ trễ khứ hồi.
Lúc này, các trường hợp sau có thể xảy ra tuỳ thuộc vào bản sao đã chọn:
- Yêu cầu đọc sẽ chuyển đến bản sao chính (Vùng A).
- Vì bản sao chính luôn được cập nhật, nên quá trình đọc có thể diễn ra trực tiếp.
- Yêu cầu đọc sẽ chuyển đến một bản sao không phải bản sao chính (chẳng hạn như Vùng B)
- Phân đoạn 3 có thể biết theo trạng thái nội bộ rằng phân đoạn này có đủ thông tin để phân phát hoạt động đọc và phân đoạn này sẽ thực hiện việc đó.
- Split 3 không chắc chắn liệu đã thấy dữ liệu mới nhất hay chưa. Nó gửi một thông báo đến nhóm trưởng để yêu cầu dấu thời gian của giao dịch cuối cùng mà nhóm cần áp dụng để phục vụ hoạt động đọc. Sau khi giao dịch đó được áp dụng, quá trình đọc có thể tiếp tục.
Cloud Firestore sau đó trả về phản hồi cho ứng dụng khách của nó.
Đọc nhiều phần
Trong trường hợp cần đọc từ nhiều phân vùng, cơ chế tương tự sẽ xảy ra trên tất cả các phân vùng. Sau khi dữ liệu được trả về từ tất cả các phần chia tách, ứng dụng lưu trữ trong Cloud Firestore sẽ kết hợp các kết quả. Cloud Firestore sau đó sẽ phản hồi cho máy khách bằng dữ liệu này.
Đọc dữ liệu cũ
Chế độ đọc mạnh là chế độ mặc định trong Cloud Firestore. Tuy nhiên, điều này có thể dẫn đến độ trễ cao hơn do cần giao tiếp với nhóm trưởng. Thường thì ứng dụng Cloud Firestore không cần đọc phiên bản mới nhất của dữ liệu và chức năng này hoạt động tốt với dữ liệu có thể đã cũ vài giây.
Trong trường hợp đó, ứng dụng có thể chọn nhận dữ liệu đọc cũ bằng cách sử dụng các lựa chọn đọc read_time. Trong trường hợp này, các thao tác đọc được thực hiện khi dữ liệu ở read_time và bản sao gần nhất có nhiều khả năng đã xác minh rằng bản sao đó có dữ liệu tại read_time được chỉ định.
Để có hiệu suất tốt hơn đáng kể, 15 giây là một giá trị độ trễ hợp lý. Ngay cả đối với các lượt đọc cũ, các hàng được tạo ra vẫn nhất quán với nhau.
Tránh điểm phát sóng
Các phân vùng trong Cloud Firestore sẽ tự động được chia thành các phần nhỏ hơn để phân phối lưu lượng truy cập đến nhiều máy chủ lưu trữ hơn khi cần hoặc khi không gian khoá mở rộng. Các nhóm được tạo để xử lý lưu lượng truy cập dư thừa sẽ được giữ lại trong khoảng 24 giờ ngay cả khi lưu lượng truy cập biến mất. Vì vậy, nếu có các đợt tăng đột biến lưu lượng truy cập lặp lại, thì các phân đoạn sẽ được duy trì và nhiều phân đoạn hơn sẽ được giới thiệu bất cứ khi nào cần thiết. Các cơ chế này giúp cơ sở dữ liệu Cloud Firestore tự động mở rộng quy mô khi lưu lượng truy cập hoặc kích thước cơ sở dữ liệu tăng lên. Tuy nhiên, bạn cần lưu ý một số hạn chế như được giải thích bên dưới.
Việc phân chia bộ nhớ và tải mất thời gian, đồng thời việc tăng lưu lượng truy cập quá nhanh có thể gây ra độ trễ cao hoặc lỗi vượt quá thời hạn, thường được gọi là điểm nóng, trong khi dịch vụ điều chỉnh. Phương pháp hay nhất là phân phối các thao tác trên phạm vi khoá, đồng thời tăng lưu lượng truy cập trên một tập hợp trong cơ sở dữ liệu với 500 thao tác mỗi giây. Sau khi tăng dần, hãy tăng lưu lượng truy cập lên đến 50% sau mỗi 5 phút. Quá trình này được gọi là quy tắc 500/50/5 và định vị cơ sở dữ liệu để mở rộng quy mô một cách tối ưu nhằm đáp ứng khối lượng công việc của bạn.
Mặc dù các phân vùng được tạo tự động khi tải tăng lên, nhưng Cloud Firestore chỉ có thể phân chia một dải khoá cho đến khi phân vùng đó phân phát một tài liệu duy nhất bằng cách sử dụng một nhóm máy chủ lưu trữ sao chép chuyên dụng. Do đó, số lượng lớn và liên tục các thao tác đồng thời trên một tài liệu có thể dẫn đến điểm truy cập trên tài liệu đó. Nếu gặp phải độ trễ cao liên tục trên một tài liệu, bạn nên cân nhắc việc sửa đổi mô hình dữ liệu để phân chia hoặc sao chép dữ liệu trên nhiều tài liệu.
Lỗi tranh chấp xảy ra khi nhiều thao tác cố gắng đọc và/hoặc ghi cùng một tài liệu cùng một lúc.
Một trường hợp đặc biệt khác của hiện tượng xung đột xảy ra khi một khoá tăng/giảm tuần tự được dùng làm mã nhận dạng tài liệu trong Cloud Firestore và có số lượng thao tác đáng kể mỗi giây. Việc tạo thêm các phân khúc không giúp ích gì trong trường hợp này vì lưu lượng truy cập tăng đột biến sẽ chuyển sang phân khúc mới tạo. Vì Cloud Firestore tự động lập chỉ mục tất cả các trường trong tài liệu theo mặc định, nên các điểm truy cập di chuyển như vậy cũng có thể được tạo trên không gian chỉ mục cho một trường tài liệu chứa giá trị tăng/giảm tuần tự như dấu thời gian.
Xin lưu ý rằng bằng cách làm theo các phương pháp nêu trên, Cloud Firestore có thể mở rộng quy mô để phân phát khối lượng công việc lớn tuỳ ý mà bạn không cần phải điều chỉnh bất kỳ cấu hình nào.
Khắc phục sự cố
Cloud Firestore cung cấp Key Visualizer dưới dạng một công cụ chẩn đoán được thiết kế để phân tích các quy luật sử dụng và khắc phục các vấn đề về điểm tương tác.
Tiếp theo là gì?
- Đọc thêm về các phương pháp hay nhất
- Tìm hiểu về truy vấn theo thời gian thực ở quy mô lớn