
Swift 4 में पेश किया गया Swift का Codable API, कंपाइलर की सुविधाओं का फ़ायदा उठाने में हमारी मदद करता है. इससे, सीरियलाइज़ किए गए फ़ॉर्मैट से Swift टाइप में डेटा को मैप करना आसान हो जाता है.
ऐसा हो सकता है कि आपने Codable का इस्तेमाल, वेब एपीआई से मिले डेटा को अपने ऐप्लिकेशन के डेटा मॉडल में मैप करने के लिए किया हो. हालांकि, यह इससे कहीं ज़्यादा फ़ायदेमंद है.
इस गाइड में, हम देखेंगे कि Codable का इस्तेमाल करके, Cloud Firestore से Swift टाइप और इसके उलट डेटा को कैसे मैप किया जा सकता है.
Cloud Firestore से कोई दस्तावेज़ फ़ेच करने पर, आपके ऐप्लिकेशन को कुंजी/वैल्यू पेयर की डिक्शनरी मिलेगी. अगर आपने एक से ज़्यादा दस्तावेज़ दिखाने वाली किसी कार्रवाई का इस्तेमाल किया है, तो आपको डिक्शनरी की एक सरणी मिलेगी.
अब Swift में सीधे तौर पर डिक्शनरी का इस्तेमाल किया जा सकता है. साथ ही, ये डिक्शनरी कुछ बेहतरीन सुविधाएं देती हैं. ऐसा हो सकता है कि ये सुविधाएं आपके इस्तेमाल के हिसाब से बिलकुल सही हों. हालांकि, यह तरीका टाइप सेफ़ नहीं है. साथ ही, एट्रिब्यूट के नाम की स्पेलिंग गलत लिखने या नए एट्रिब्यूट को मैप करना भूल जाने से, ऐसे बग आसानी से आ सकते हैं जिन्हें ठीक करना मुश्किल होता है. ऐसा तब होता है, जब आपकी टीम ने पिछले हफ़्ते कोई नई सुविधा लॉन्च की हो.
पहले, कई डेवलपर ने इन कमियों को दूर करने के लिए, एक आसान मैपिंग लेयर लागू की थी. इससे वे डिक्शनरी को Swift टाइप में मैप कर पाते थे. हालांकि, इनमें से ज़्यादातर लागू करने के तरीके, Cloud Firestore दस्तावेज़ों और आपके ऐप्लिकेशन के डेटा मॉडल के संबंधित टाइप के बीच मैपिंग को मैन्युअल तरीके से तय करने पर आधारित होते हैं.
Cloud Firestore में Swift के Codable API के लिए सहायता उपलब्ध है. इससे यह काम काफ़ी आसान हो जाता है:
- अब आपको मैन्युअल तरीके से कोई मैपिंग कोड लागू नहीं करना होगा.
- अलग-अलग नामों वाले एट्रिब्यूट को मैप करने का तरीका तय करना आसान है.
- इसमें Swift के कई टाइप के लिए पहले से ही सपोर्ट मौजूद है.
- साथ ही, कस्टम टाइप की मैपिंग के लिए सहायता जोड़ना आसान है.
- सबसे अच्छी बात यह है कि सामान्य डेटा मॉडल के लिए, आपको कोई मैपिंग कोड लिखने की ज़रूरत नहीं होगी.
मैपिंग डेटा
Cloud Firestore, डेटा को ऐसे दस्तावेज़ों में सेव करता है जो कुंजियों को वैल्यू के साथ मैप करते हैं. किसी दस्तावेज़ से डेटा फ़ेच करने के लिए, हम DocumentSnapshot.data() को कॉल कर सकते हैं. यह फ़ील्ड के नामों को Any पर मैप करने वाली डिक्शनरी दिखाता है: func data() -> [String : Any]?.
इसका मतलब है कि हम हर फ़ील्ड को ऐक्सेस करने के लिए, Swift के सबस्क्रिप्ट सिंटैक्स का इस्तेमाल कर सकते हैं.
import FirebaseFirestore
#warning("DO NOT MAP YOUR DOCUMENTS MANUALLY. USE CODABLE INSTEAD.")
func fetchBook(documentId: String) {
let docRef = db.collection("books").document(documentId)
docRef.getDocument { document, error in
if let error = error as NSError? {
self.errorMessage = "Error getting document: \(error.localizedDescription)"
}
else {
if let document = document {
let id = document.documentID
let data = document.data()
let title = data?["title"] as? String ?? ""
let numberOfPages = data?["numberOfPages"] as? Int ?? 0
let author = data?["author"] as? String ?? ""
self.book = Book(id:id, title: title, numberOfPages: numberOfPages, author: author)
}
}
}
}
यह कोड देखने में भले ही आसान लगे और इसे लागू करना भी आसान हो, लेकिन यह कोड बहुत कमज़ोर है. इसे बनाए रखना मुश्किल है और इसमें गड़बड़ियां होने की आशंका भी ज़्यादा होती है.
जैसा कि आप देख सकते हैं, हम दस्तावेज़ के फ़ील्ड के डेटा टाइप के बारे में अनुमान लगा रहे हैं. यह जानकारी सही हो भी सकती है और नहीं भी.
ध्यान दें कि कोई स्कीमा न होने की वजह से, कलेक्शन में नया दस्तावेज़ आसानी से जोड़ा जा सकता है. साथ ही, किसी फ़ील्ड के लिए अलग टाइप चुना जा सकता है. ऐसा हो सकता है कि आपने गलती से numberOfPages फ़ील्ड के लिए स्ट्रिंग चुना हो. इससे मैपिंग की ऐसी समस्या हो सकती है जिसे ढूंढना मुश्किल हो. इसके अलावा, जब भी कोई नया फ़ील्ड जोड़ा जाता है, तब आपको मैपिंग कोड को अपडेट करना होगा. यह एक मुश्किल काम है.
साथ ही, हमें यह नहीं भूलना चाहिए कि हम Swift के मज़बूत टाइप सिस्टम का फ़ायदा नहीं ले रहे हैं. इस सिस्टम को Book की हर प्रॉपर्टी के लिए सही टाइप की जानकारी होती है.
Codable क्या है?
Apple के दस्तावेज़ के मुताबिक, Codable "एक ऐसा टाइप है जो खुद को बाहरी तौर पर दिखा सकता है और बाहरी तौर पर दिखाए गए डेटा को अपने हिसाब से बदल सकता है." दरअसल, Codable, Encodable और Decodable प्रोटोकॉल के लिए एक टाइप एलियास है. Swift टाइप को इस प्रोटोकॉल के मुताबिक बनाने पर, कंपाइलर उस कोड को सिंथेसाइज़ करेगा जो इस टाइप के इंस्टेंस को JSON जैसे सीरियलाइज़ किए गए फ़ॉर्मैट से कोड में बदलने/कोड से वापस बदलने के लिए ज़रूरी है.
किसी किताब के बारे में डेटा सेव करने के लिए, एक सामान्य टाइप ऐसा दिख सकता है:
struct Book: Codable {
var title: String
var numberOfPages: Int
var author: String
}
जैसा कि आप देख सकते हैं, टाइप को Codable के मुताबिक बनाने के लिए, बहुत कम बदलाव करने पड़ते हैं. हमें सिर्फ़ प्रोटोकॉल के मुताबिक काम करने की सुविधा जोड़नी थी. इसके अलावा, कोई और बदलाव करने की ज़रूरत नहीं थी.
इस कोड की मदद से, अब हम किसी किताब को आसानी से JSON ऑब्जेक्ट में बदल सकते हैं:
do {
let book = Book(title: "The Hitchhiker's Guide to the Galaxy",
numberOfPages: 816,
author: "Douglas Adams")
let encoder = JSONEncoder()
let data = try encoder.encode(book)
}
catch {
print("Error when trying to encode book: \(error)")
}
किसी JSON ऑब्जेक्ट को Book इंस्टेंस में डिकोड करने का तरीका यहां बताया गया है:
let decoder = JSONDecoder()
let data = /* fetch data from the network */
let decodedBook = try decoder.decode(Book.self, from: data)
Codable का इस्तेमाल करके, Cloud Firestore दस्तावेज़ों में सामान्य टाइप को मैप करना
Cloud Firestore में कई तरह के डेटा टाइप इस्तेमाल किए जा सकते हैं. जैसे, सामान्य स्ट्रिंग से लेकर नेस्ट किए गए मैप तक. इनमें से ज़्यादातर, Swift के बिल्ट-इन टाइप से सीधे तौर पर जुड़े होते हैं. आइए, सबसे पहले कुछ आसान डेटा टाइप की मैपिंग के बारे में जानते हैं. इसके बाद, हम ज़्यादा मुश्किल डेटा टाइप के बारे में जानेंगे.
Cloud Firestore दस्तावेज़ों को Swift टाइप से मैप करने के लिए, यह तरीका अपनाएं:
- पक्का करें कि आपने अपने प्रोजेक्ट में
FirebaseFirestoreफ़्रेमवर्क जोड़ा हो. इसके लिए, Swift Package Manager या CocoaPods में से किसी एक का इस्तेमाल किया जा सकता है. - अपनी Swift फ़ाइल में
FirebaseFirestoreइंपोर्ट करें. - अपने टाइप को
Codableके मुताबिक बनाएं. - (अगर आपको टाइप का इस्तेमाल
Listव्यू में करना है, तो यह ज़रूरी नहीं है) अपने टाइप मेंidप्रॉपर्टी जोड़ें. साथ ही,@DocumentIDका इस्तेमाल करके Cloud Firestore को बताएं कि इसे दस्तावेज़ के आईडी पर मैप करना है. हम इस बारे में यहां ज़्यादा जानकारी देंगे. - किसी दस्तावेज़ के रेफ़रंस को Swift टाइप से मैप करने के लिए,
documentReference.data(as: )का इस्तेमाल करें. - Swift टाइप से डेटा को Cloud Firestore दस्तावेज़ में मैप करने के लिए,
documentReference.setData(from: )का इस्तेमाल करें. - (ज़रूरी नहीं, लेकिन हमारा सुझाव है कि आप इसे इस्तेमाल करें) गड़बड़ी को ठीक करने के लिए सही तरीके से कोड लिखें.
आइए, हम अपने Book टाइप को इसके हिसाब से अपडेट करें:
struct Book: Codable {
@DocumentID var id: String?
var title: String
var numberOfPages: Int
var author: String
}
इस टाइप को पहले से ही कोड किया जा सकता था. इसलिए, हमें सिर्फ़ id प्रॉपर्टी जोड़नी पड़ी और इसे @DocumentID प्रॉपर्टी रैपर के साथ एनोटेट करना पड़ा.
किसी दस्तावेज़ को फ़ेच और मैप करने के लिए, पिछले कोड स्निपेट का इस्तेमाल करके, हम मैन्युअल मैपिंग के पूरे कोड को एक लाइन से बदल सकते हैं:
func fetchBook(documentId: String) {
let docRef = db.collection("books").document(documentId)
docRef.getDocument { document, error in
if let error = error as NSError? {
self.errorMessage = "Error getting document: \(error.localizedDescription)"
}
else {
if let document = document {
do {
self.book = try document.data(as: Book.self)
}
catch {
print(error)
}
}
}
}
}
getDocument(as:) को कॉल करते समय, दस्तावेज़ का टाइप तय करके इसे और भी छोटा किया जा सकता है. इससे आपके लिए मैपिंग की जाएगी. साथ ही, यह Result टाइप का एक ऑब्जेक्ट देगा. इसमें मैप किया गया दस्तावेज़ होगा. अगर डिकोड नहीं किया जा सका, तो गड़बड़ी का मैसेज दिखेगा:
private func fetchBook(documentId: String) {
let docRef = db.collection("books").document(documentId)
docRef.getDocument(as: Book.self) { result in
switch result {
case .success(let book):
// A Book value was successfully initialized from the DocumentSnapshot.
self.book = book
self.errorMessage = nil
case .failure(let error):
// A Book value could not be initialized from the DocumentSnapshot.
self.errorMessage = "Error decoding document: \(error.localizedDescription)"
}
}
}
किसी मौजूदा दस्तावेज़ को अपडेट करना उतना ही आसान है जितना documentReference.setData(from: ) को कॉल करना. गड़बड़ी को मैनेज करने से जुड़ी कुछ बुनियादी बातों के साथ, Book इंस्टेंस को सेव करने का कोड यहां दिया गया है:
func updateBook(book: Book) {
if let id = book.id {
let docRef = db.collection("books").document(id)
do {
try docRef.setData(from: book)
}
catch {
print(error)
}
}
}
नया दस्तावेज़ जोड़ते समय, Cloud Firestore दस्तावेज़ को नया आईडी अपने-आप असाइन कर देगा. यह सुविधा तब भी काम करती है, जब ऐप्लिकेशन ऑफ़लाइन हो.
func addBook(book: Book) {
let collectionRef = db.collection("books")
do {
let newDocReference = try collectionRef.addDocument(from: self.book)
print("Book stored with new document reference: \(newDocReference)")
}
catch {
print(error)
}
}
Cloud Firestore, सामान्य डेटा टाइप को मैप करने के साथ-साथ कई अन्य डेटा टाइप भी इस्तेमाल करता है. इनमें से कुछ स्ट्रक्चर्ड टाइप होते हैं. इनका इस्तेमाल करके, किसी दस्तावेज़ में नेस्ट किए गए ऑब्जेक्ट बनाए जा सकते हैं.
नेस्ट किए गए कस्टम टाइप
हमें अपने दस्तावेज़ों में जिन एट्रिब्यूट को मैप करना है उनमें से ज़्यादातर की वैल्यू सामान्य होती हैं. जैसे, किताब का टाइटल या लेखक का नाम. लेकिन, उन मामलों के बारे में क्या कहें जिनमें हमें ज़्यादा कॉम्प्लेक्स ऑब्जेक्ट सेव करना होता है? उदाहरण के लिए, हम किताब के कवर के यूआरएल को अलग-अलग रिज़ॉल्यूशन में सेव करना चाहते हैं.
Cloud Firestore में ऐसा करने का सबसे आसान तरीका, मैप का इस्तेमाल करना है:

इससे जुड़ा Swift स्ट्रक्चर लिखते समय, हम इस बात का फ़ायदा उठा सकते हैं कि Cloud Firestore यूआरएल के साथ काम करता है. यूआरएल वाले फ़ील्ड को सेव करते समय, इसे स्ट्रिंग में बदल दिया जाएगा. इसके उलट, स्ट्रिंग को यूआरएल में बदल दिया जाएगा:
struct CoverImages: Codable {
var small: URL
var medium: URL
var large: URL
}
struct BookWithCoverImages: Codable {
@DocumentID var id: String?
var title: String
var numberOfPages: Int
var author: String
var cover: CoverImages?
}
ध्यान दें कि हमने Cloud Firestore दस्तावेज़ में कवर मैप के लिए, CoverImages स्ट्रक्चर को कैसे डिफ़ाइन किया है. BookWithCoverImages पर कवर प्रॉपर्टी को 'ज़रूरी नहीं' के तौर पर मार्क करके, हम इस बात का ध्यान रख पाते हैं कि कुछ दस्तावेज़ों में कवर एट्रिब्यूट शामिल नहीं हो सकता.
अगर आपको यह जानना है कि डेटा को फ़ेच या अपडेट करने के लिए, कोड स्निपेट क्यों नहीं है, तो आपको यह जानकर खुशी होगी कि Cloud Firestore से पढ़ने या लिखने के लिए, कोड में बदलाव करने की ज़रूरत नहीं है. यह सब, शुरुआती सेक्शन में लिखे गए कोड के साथ काम करता है.
ऐरे
कभी-कभी, हमें किसी दस्तावेज़ में वैल्यू का कलेक्शन सेव करना होता है. किसी किताब की शैलियां इसका एक अच्छा उदाहरण हैं: द हिचहाइकर गाइड टु द गैलेक्सी जैसी कोई किताब कई कैटगरी में आ सकती है. इस मामले में, "साइंस फ़िक्शन" और "कॉमेडी":

Cloud Firestore में, वैल्यू की एक अरे का इस्तेमाल करके इसे मॉडल किया जा सकता है. यह सुविधा, कोड किए जा सकने वाले किसी भी टाइप के लिए उपलब्ध है. जैसे, String, Int वगैरह. यहां बताया गया है कि हमारे Book मॉडल में, शैलियों की एक कैटगरी कैसे जोड़ी जाती है:
public struct BookWithGenre: Codable {
@DocumentID var id: String?
var title: String
var numberOfPages: Int
var author: String
var genres: [String]
}
यह किसी भी कोड वाले टाइप के लिए काम करता है. इसलिए, हम कस्टम टाइप का भी इस्तेमाल कर सकते हैं. मान लें कि हमें हर किताब के लिए टैग की सूची सेव करनी है. हम टैग के नाम के साथ-साथ, टैग का रंग भी सेव करना चाहते हैं. जैसे:
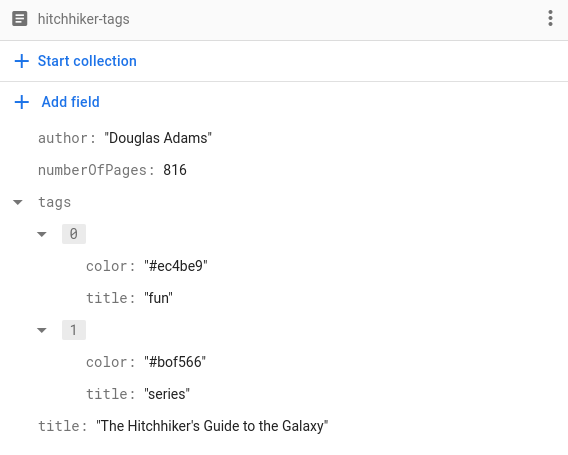
टैग को इस तरह से सेव करने के लिए, हमें सिर्फ़ एक Tag स्ट्रक्चर लागू करना होगा, ताकि टैग को दिखाया जा सके और उसे कोड किया जा सके:
struct Tag: Codable, Hashable {
var title: String
var color: String
}
इस तरह, हम अपने Book दस्तावेज़ों में Tags का ऐरे सेव कर सकते हैं!
struct BookWithTags: Codable {
@DocumentID var id: String?
var title: String
var numberOfPages: Int
var author: String
var tags: [Tag]
}
दस्तावेज़ों के आईडी मैप करने के बारे में कुछ खास बातें
हम अलग-अलग तरह के दस्तावेज़ों को मैप करने के बारे में बात करें, उससे पहले आइए कुछ देर के लिए दस्तावेज़ आईडी को मैप करने के बारे में बात करते हैं.
हमने पिछले कुछ उदाहरणों में @DocumentID प्रॉपर्टी रैपर का इस्तेमाल किया था. इसका मकसद, हमारे Cloud Firestore दस्तावेज़ों के दस्तावेज़ आईडी को हमारे Swift टाइप की id प्रॉपर्टी से मैप करना था. ऐसा कई वजहों से ज़रूरी है:
- इससे हमें यह पता चलता है कि अगर उपयोगकर्ता स्थानीय बदलाव करता है, तो हमें किस दस्तावेज़ को अपडेट करना है.
- SwiftUI के
Listको अपने एलिमेंट के लिएIdentifiableकी ज़रूरत होती है, ताकि एलिमेंट को शामिल करते समय वे अपनी जगह से न हटें.
यह ध्यान देने वाली बात है कि @DocumentID के तौर पर मार्क किए गए एट्रिब्यूट को, दस्तावेज़ वापस लिखते समय Cloud Firestore का एनकोडर एन्कोड नहीं करेगा. ऐसा इसलिए है, क्योंकि दस्तावेज़ आईडी, दस्तावेज़ का एट्रिब्यूट नहीं है. इसलिए, इसे दस्तावेज़ में लिखना एक गलती होगी.
नेस्ट किए गए टाइप (जैसे, इस गाइड के पिछले उदाहरण में Book पर टैग की कैटगरी) के साथ काम करते समय, @DocumentID प्रॉपर्टी जोड़ने की ज़रूरत नहीं होती: नेस्ट की गई प्रॉपर्टी, Cloud Firestore दस्तावेज़ का हिस्सा होती हैं और अलग दस्तावेज़ नहीं होती हैं. इसलिए, उन्हें दस्तावेज़ आईडी की ज़रूरत नहीं होती.
तारीख और समय
Cloud Firestore में तारीखों और समय को मैनेज करने के लिए, पहले से मौजूद डेटा टाइप होता है. साथ ही, Cloud Firestore में Codable के लिए सपोर्ट उपलब्ध होने की वजह से, इनका इस्तेमाल करना आसान होता है.
आइए, इस दस्तावेज़ पर एक नज़र डालें. यह सभी प्रोग्रामिंग भाषाओं की जननी, एडा का प्रतिनिधित्व करता है. इसका आविष्कार 1843 में हुआ था:

इस दस्तावेज़ को मैप करने के लिए, Swift टाइप कुछ ऐसा दिख सकता है:
struct ProgrammingLanguage: Codable {
@DocumentID var id: String?
var name: String
var year: Date
}
हम तारीख और समय के बारे में इस सेक्शन को @ServerTimestamp के बारे में बातचीत किए बिना नहीं छोड़ सकते. यह प्रॉपर्टी रैपर, आपके ऐप्लिकेशन में टाइमस्टैंप को मैनेज करने के लिए बहुत काम का है.
किसी भी डिस्ट्रिब्यूटेड सिस्टम में, ऐसा हो सकता है कि अलग-अलग सिस्टम पर मौजूद घड़ियां हमेशा पूरी तरह से सिंक न हों. आपको लग सकता है कि यह कोई बड़ी बात नहीं है, लेकिन शेयर बाज़ार में कारोबार करने वाले सिस्टम के लिए, घड़ी के थोड़ा भी सिंक न होने के असर के बारे में सोचें: कारोबार करते समय, एक मिलीसेकंड का अंतर भी लाखों डॉलर का अंतर ला सकता है.
Cloud Firestore, @ServerTimestamp के तौर पर मार्क किए गए एट्रिब्यूट को इस तरह से हैंडल करता है: अगर एट्रिब्यूट को सेव करते समय (उदाहरण के लिए, addDocument() का इस्तेमाल करके) nil के तौर पर मार्क किया गया है, तो Cloud Firestore डेटाबेस में लिखते समय, फ़ील्ड में मौजूदा सर्वर का टाइमस्टैंप भर देगा. अगर addDocument() या updateData() को कॉल करते समय फ़ील्ड nil नहीं है, तो Cloud Firestore एट्रिब्यूट की वैल्यू में कोई बदलाव नहीं करेगा. इस तरह, createdAt और lastUpdatedAt जैसे फ़ील्ड को लागू करना आसान हो जाता है.
जियोपॉइंट
हमारे ऐप्लिकेशन में, जगह की जानकारी का इस्तेमाल हर जगह किया जाता है. इन कुकी को सेव करने से, कई शानदार सुविधाओं का इस्तेमाल किया जा सकता है. उदाहरण के लिए, किसी टास्क के लिए जगह की जानकारी सेव करना मददगार हो सकता है, ताकि जब आप किसी जगह पर पहुंचें, तो आपका ऐप्लिकेशन आपको उस टास्क के बारे में याद दिला सके.
Cloud Firestore में एक बिल्ट-इन डेटा टाइप, GeoPoint होता है. यह किसी भी जगह का देशांतर और अक्षांश सेव कर सकता है. Cloud Firestore दस्तावेज़ से/तक की जगहों को मैप करने के लिए, हम GeoPoint टाइप का इस्तेमाल कर सकते हैं:
struct Office: Codable {
@DocumentID var id: String?
var name: String
var location: GeoPoint
}
Swift में इसका टाइप CLLocationCoordinate2D है. हम इन दोनों टाइप को इस ऑपरेशन की मदद से मैप कर सकते हैं:
CLLocationCoordinate2D(latitude: office.location.latitude,
longitude: office.location.longitude)
जगह के हिसाब से दस्तावेज़ों को क्वेरी करने के बारे में ज़्यादा जानने के लिए, यह समाधान गाइड देखें.
एनम्स
Swift में, एनम को शायद सबसे कम आंका गया है. हालांकि, इनमें काफ़ी कुछ होता है. एनम का इस्तेमाल आम तौर पर, किसी चीज़ की अलग-अलग स्थितियों को मॉडल करने के लिए किया जाता है. उदाहरण के लिए, हम लेखों को मैनेज करने के लिए कोई ऐप्लिकेशन बना रहे हैं. किसी लेख की स्थिति को ट्रैक करने के लिए, हम enum Status का इस्तेमाल कर सकते हैं:
enum Status: String, Codable {
case draft
case inReview
case approved
case published
}
Cloud Firestore, मूल रूप से enum के साथ काम नहीं करता. इसका मतलब है कि यह वैल्यू के सेट को लागू नहीं कर सकता. हालांकि, हम अब भी इस तथ्य का इस्तेमाल कर सकते हैं कि enum को टाइप किया जा सकता है. साथ ही, कोड में इस्तेमाल किया जा सकने वाला टाइप चुना जा सकता है. इस उदाहरण में, हमने String चुना है. इसका मतलब है कि String दस्तावेज़ में सेव किए जाने पर, सभी enum वैल्यू को स्ट्रिंग में मैप किया जाएगा.Cloud Firestore
साथ ही, Swift में कस्टम रॉ वैल्यू का इस्तेमाल किया जा सकता है. इसलिए, हम यह भी तय कर सकते हैं कि कौनसी वैल्यू किस enum केस को रेफ़र करती है. उदाहरण के लिए, अगर हमें Status.inReview मामले को "समीक्षा में है" के तौर पर सेव करना है, तो हम ऊपर दिए गए enum को इस तरह अपडेट कर सकते हैं:
enum Status: String, Codable {
case draft
case inReview = "in review"
case approved
case published
}
मैपिंग को पसंद के मुताबिक बनाना
कभी-कभी, जिन Cloud Firestore दस्तावेज़ों को हमें मैप करना होता है उनके एट्रिब्यूट के नाम, Swift में मौजूद हमारे डेटा मॉडल की प्रॉपर्टी के नामों से मेल नहीं खाते. उदाहरण के लिए, हमारे किसी सहकर्मी ने Python डेवलपर के तौर पर काम किया है और उसने अपने सभी एट्रिब्यूट के नामों के लिए snake_case का इस्तेमाल करने का फ़ैसला किया है.
चिंता न करें: Codable ने हमें कवर किया है!
इस तरह के मामलों के लिए, हम CodingKeys का इस्तेमाल कर सकते हैं. यह एक इनम है. इसे कोड में शामिल किए जा सकने वाले स्ट्रक्चर में जोड़ा जा सकता है. इससे यह तय किया जा सकता है कि कुछ एट्रिब्यूट कैसे मैप किए जाएंगे.
इस दस्तावेज़ पर विचार करें:

इस दस्तावेज़ को String टाइप की name प्रॉपर्टी वाले स्ट्रक्चर से मैप करने के लिए, हमें ProgrammingLanguage स्ट्रक्चर में CodingKeys enum जोड़ना होगा. साथ ही, दस्तावेज़ में मौजूद एट्रिब्यूट का नाम बताना होगा:
struct ProgrammingLanguage: Codable {
@DocumentID var id: String?
var name: String
var year: Date
enum CodingKeys: String, CodingKey {
case id
case name = "language_name"
case year
}
}
डिफ़ॉल्ट रूप से, Codable API हमारे Swift टाइप के प्रॉपर्टी नामों का इस्तेमाल करेगा. इससे, Cloud Firestore दस्तावेज़ों पर एट्रिब्यूट के नाम तय किए जा सकेंगे. हम इन दस्तावेज़ों को मैप करने की कोशिश कर रहे हैं. इसलिए, जब तक एट्रिब्यूट के नाम मेल खाते हैं, तब तक हमें कोडिंग किए जा सकने वाले टाइप में CodingKeys जोड़ने की ज़रूरत नहीं है. हालांकि, किसी खास टाइप के लिए CodingKeys का इस्तेमाल करने के बाद, हमें उन सभी प्रॉपर्टी के नाम जोड़ने होंगे जिन्हें मैप करना है.
ऊपर दिए गए कोड स्निपेट में, हमने एक id प्रॉपर्टी तय की है. इसका इस्तेमाल हम SwiftUI List व्यू में आइडेंटिफ़ायर के तौर पर कर सकते हैं. अगर हमने इसे CodingKeys में नहीं बताया है, तो डेटा फ़ेच करते समय इसे मैप नहीं किया जाएगा. इसलिए, यह nil बन जाएगा.
इससे List व्यू में पहला दस्तावेज़ दिखने लगेगा.
मैपिंग की प्रोसेस के दौरान, ऐसी किसी भी प्रॉपर्टी को अनदेखा कर दिया जाएगा जिसे CodingKeys enum में केस के तौर पर शामिल नहीं किया गया है. अगर हमें कुछ प्रॉपर्टी को मैप करने से रोकना है, तो यह तरीका हमारे लिए फ़ायदेमंद हो सकता है.
उदाहरण के लिए, अगर हमें reasonWhyILoveThis प्रॉपर्टी को मैप होने से रोकना है, तो हमें बस इसे CodingKeys enum से हटाना होगा:
struct ProgrammingLanguage: Identifiable, Codable {
@DocumentID var id: String?
var name: String
var year: Date
var reasonWhyILoveThis: String = ""
enum CodingKeys: String, CodingKey {
case id
case name = "language_name"
case year
}
}
कभी-कभी हमें Cloud Firestore दस्तावेज़ में, खाली एट्रिब्यूट लिखना पड़ सकता है. Swift में, किसी वैल्यू के मौजूद न होने की जानकारी देने के लिए, विकल्प मौजूद होते हैं. साथ ही, Cloud Firestore में null वैल्यू भी काम करती हैं.
हालांकि, nil वैल्यू वाले वैकल्पिक फ़ील्ड को एन्कोड करने का डिफ़ॉल्ट तरीका यह है कि उन्हें शामिल न किया जाए. @ExplicitNull से हमें यह कंट्रोल करने में मदद मिलती है कि Swift
optionals को एन्कोड करते समय कैसे हैंडल किया जाए: किसी वैकल्पिक प्रॉपर्टी को @ExplicitNull के तौर पर फ़्लैग करके, हम Cloud Firestore को यह निर्देश दे सकते हैं कि अगर इस प्रॉपर्टी में nil की वैल्यू है, तो इसे दस्तावेज़ में शून्य वैल्यू के साथ लिखा जाए.
रंगों को मैप करने के लिए, कस्टम एन्कोडर और डिकोडर का इस्तेमाल करना
Codable के साथ मैपिंग डेटा के बारे में हमारी कवरेज के आखिरी विषय के तौर पर, आइए कस्टम एनकोडर और डिकोडर के बारे में जानते हैं. इस सेक्शन में, नेटिव Cloud Firestore डेटाटाइप के बारे में नहीं बताया गया है. हालांकि, कस्टम एनकोडर और डिकोडर, आपके Cloud Firestore ऐप्लिकेशन में बहुत काम आते हैं.
"मैं रंगों को कैसे मैप करूं" डेवलपर के सबसे ज़्यादा पूछे जाने वाले सवालों में से एक है. यह सवाल न सिर्फ़ Cloud Firestore के लिए, बल्कि Swift और JSON के बीच मैपिंग के लिए भी पूछा जाता है. इसके लिए कई समाधान उपलब्ध हैं, लेकिन उनमें से ज़्यादातर JSON पर फ़ोकस करते हैं. साथ ही, उनमें से लगभग सभी, रंगों को नेस्ट की गई डिक्शनरी के तौर पर मैप करते हैं, जिसमें उसके RGB कॉम्पोनेंट शामिल होते हैं.
ऐसा लगता है कि इस समस्या को हल करने का कोई बेहतर और आसान तरीका होना चाहिए. हम वेब कलर (या ज़्यादा सटीक तौर पर कहें, तो सीएसएस हेक्स कलर नोटेशन) का इस्तेमाल क्यों नहीं करते — इनका इस्तेमाल करना आसान है (असल में, यह सिर्फ़ एक स्ट्रिंग है). साथ ही, ये पारदर्शिता को भी सपोर्ट करते हैं!
Swift Color को उसकी हेक्स वैल्यू से मैप करने के लिए, हमें एक Swift एक्सटेंशन बनाना होगा, जो Color में Codable जोड़ता है.
extension Color {
init(hex: String) {
let rgba = hex.toRGBA()
self.init(.sRGB,
red: Double(rgba.r),
green: Double(rgba.g),
blue: Double(rgba.b),
opacity: Double(rgba.alpha))
}
//... (code for translating between hex and RGBA omitted for brevity)
}
extension Color: Codable {
public init(from decoder: Decoder) throws {
let container = try decoder.singleValueContainer()
let hex = try container.decode(String.self)
self.init(hex: hex)
}
public func encode(to encoder: Encoder) throws {
var container = encoder.singleValueContainer()
try container.encode(toHex)
}
}
decoder.singleValueContainer() का इस्तेमाल करके, हम RGBA कॉम्पोनेंट को नेस्ट किए बिना, String को उसके Color के बराबर डीकोड कर सकते हैं. इसके अलावा, इन वैल्यू का इस्तेमाल अपने ऐप्लिकेशन के वेब यूज़र इंटरफ़ेस (यूआई) में किया जा सकता है. इसके लिए, आपको पहले इन्हें बदलने की ज़रूरत नहीं है!
इससे, हम मैपिंग टैग के लिए कोड को अपडेट कर सकते हैं. इससे, टैग के रंगों को सीधे तौर पर मैनेज करना आसान हो जाता है. इसके लिए, हमें अपने ऐप्लिकेशन के यूज़र इंटरफ़ेस (यूआई) कोड में उन्हें मैन्युअल तरीके से मैप करने की ज़रूरत नहीं होती:
struct Tag: Codable, Hashable {
var title: String
var color: Color
}
struct BookWithTags: Codable {
@DocumentID var id: String?
var title: String
var numberOfPages: Int
var author: String
var tags: [Tag]
}
गड़बड़ियों को ठीक करना
ऊपर दिए गए कोड स्निपेट में, हमने जान-बूझकर गड़बड़ी को कम से कम रखा है. हालांकि, प्रोडक्शन ऐप्लिकेशन में आपको यह पक्का करना होगा कि किसी भी गड़बड़ी को ठीक तरीके से हैंडल किया जाए.
यहां एक कोड स्निपेट दिया गया है. इसमें बताया गया है कि गड़बड़ी की किसी भी ऐसी स्थिति को कैसे ठीक किया जाए जो आपको दिख सकती है:
class MappingSimpleTypesViewModel: ObservableObject {
@Published var book: Book = .empty
@Published var errorMessage: String?
private var db = Firestore.firestore()
func fetchAndMap() {
fetchBook(documentId: "hitchhiker")
}
func fetchAndMapNonExisting() {
fetchBook(documentId: "does-not-exist")
}
func fetchAndTryMappingInvalidData() {
fetchBook(documentId: "invalid-data")
}
private func fetchBook(documentId: String) {
let docRef = db.collection("books").document(documentId)
docRef.getDocument(as: Book.self) { result in
switch result {
case .success(let book):
// A Book value was successfully initialized from the DocumentSnapshot.
self.book = book
self.errorMessage = nil
case .failure(let error):
// A Book value could not be initialized from the DocumentSnapshot.
switch error {
case DecodingError.typeMismatch(_, let context):
self.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.valueNotFound(_, let context):
self.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.keyNotFound(_, let context):
self.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.dataCorrupted(let key):
self.errorMessage = "\(error.localizedDescription): \(key)"
default:
self.errorMessage = "Error decoding document: \(error.localizedDescription)"
}
}
}
}
}
लाइव अपडेट में होने वाली गड़बड़ियों को ठीक करना
पिछले कोड स्निपेट में, किसी एक दस्तावेज़ को फ़ेच करते समय गड़बड़ियों को ठीक करने का तरीका दिखाया गया है. Cloud Firestore, डेटा को सिर्फ़ एक बार फ़ेच करने के अलावा, आपके ऐप्लिकेशन को अपडेट भी भेजता है. इसके लिए, स्नैपशॉट लिसनर का इस्तेमाल किया जाता है: हम किसी कलेक्शन (या क्वेरी) पर स्नैपशॉट लिसनर रजिस्टर कर सकते हैं. इसके बाद, जब भी कोई अपडेट होगा, Cloud Firestore हमारे लिसनर को कॉल करेगा.
यहां एक कोड स्निपेट दिया गया है. इसमें बताया गया है कि स्नैपशॉट लिसनर को कैसे रजिस्टर करें, Codable का इस्तेमाल करके डेटा को कैसे मैप करें, और होने वाली किसी भी गड़बड़ी को कैसे ठीक करें. इसमें यह भी बताया गया है कि कलेक्शन में नया दस्तावेज़ कैसे जोड़ा जाता है. जैसा कि आपको दिखेगा, मैप किए गए दस्तावेज़ों को सेव करने वाले लोकल ऐरे को हमें खुद अपडेट करने की ज़रूरत नहीं है. ऐसा इसलिए, क्योंकि स्नैपशॉट लिसनर में मौजूद कोड इसका ध्यान रखता है.
class MappingColorsViewModel: ObservableObject {
@Published var colorEntries = [ColorEntry]()
@Published var newColor = ColorEntry.empty
@Published var errorMessage: String?
private var db = Firestore.firestore()
private var listenerRegistration: ListenerRegistration?
public func unsubscribe() {
if listenerRegistration != nil {
listenerRegistration?.remove()
listenerRegistration = nil
}
}
func subscribe() {
if listenerRegistration == nil {
listenerRegistration = db.collection("colors")
.addSnapshotListener { [weak self] (querySnapshot, error) in
guard let documents = querySnapshot?.documents else {
self?.errorMessage = "No documents in 'colors' collection"
return
}
self?.colorEntries = documents.compactMap { queryDocumentSnapshot in
let result = Result { try queryDocumentSnapshot.data(as: ColorEntry.self) }
switch result {
case .success(let colorEntry):
if let colorEntry = colorEntry {
// A ColorEntry value was successfully initialized from the DocumentSnapshot.
self?.errorMessage = nil
return colorEntry
}
else {
// A nil value was successfully initialized from the DocumentSnapshot,
// or the DocumentSnapshot was nil.
self?.errorMessage = "Document doesn't exist."
return nil
}
case .failure(let error):
// A ColorEntry value could not be initialized from the DocumentSnapshot.
switch error {
case DecodingError.typeMismatch(_, let context):
self?.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.valueNotFound(_, let context):
self?.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.keyNotFound(_, let context):
self?.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.dataCorrupted(let key):
self?.errorMessage = "\(error.localizedDescription): \(key)"
default:
self?.errorMessage = "Error decoding document: \(error.localizedDescription)"
}
return nil
}
}
}
}
}
func addColorEntry() {
let collectionRef = db.collection("colors")
do {
let newDocReference = try collectionRef.addDocument(from: newColor)
print("ColorEntry stored with new document reference: \(newDocReference)")
}
catch {
print(error)
}
}
}
इस पोस्ट में इस्तेमाल किए गए सभी कोड स्निपेट, एक सैंपल ऐप्लिकेशन का हिस्सा हैं. इसे इस GitHub रिपॉज़िटरी से डाउनलोड किया जा सकता है.
आगे बढ़ें और Codable का इस्तेमाल करें!
Swift का Codable API, डेटा को सीरियलाइज़ किए गए फ़ॉर्मैट से आपके ऐप्लिकेशन के डेटा मॉडल में और उससे वापस मैप करने का एक बेहतर और सुविधाजनक तरीका उपलब्ध कराता है. इस गाइड में, आपने देखा कि Cloud Firestore को डेटास्टोर के तौर पर इस्तेमाल करने वाले ऐप्लिकेशन में इसका इस्तेमाल करना कितना आसान है.
हमने सामान्य डेटा टाइप के साथ एक बुनियादी उदाहरण से शुरुआत की. इसके बाद, हमने डेटा मॉडल की जटिलता को धीरे-धीरे बढ़ाया. इस दौरान, हम Codable और Firebase के लागू करने के तरीके पर भरोसा कर पाए, ताकि वे हमारे लिए मैपिंग कर सकें.
Codable के बारे में ज़्यादा जानने के लिए, हमारा सुझाव है कि आप ये संसाधन देखें:
- जॉन संडल ने Codable की बुनियादी बातों के बारे में एक अच्छा लेख लिखा है.
- अगर आपको किताबें पढ़ना पसंद है, तो Mattt की Flight School Guide to Swift Codable पढ़ें.
- आखिर में, Donny Wals ने Codable के बारे में पूरी सीरीज़ बनाई है.
हमने Cloud Firestore दस्तावेज़ों को मैप करने के लिए, पूरी जानकारी वाली गाइड तैयार करने की पूरी कोशिश की है. हालांकि, इसमें पूरी जानकारी नहीं है. ऐसा हो सकता है कि टाइप मैप करने के लिए, कोई दूसरी रणनीति इस्तेमाल की जा रही हो. नीचे दिए गए सुझाव/राय दें या शिकायत करें बटन का इस्तेमाल करके, हमें बताएं कि आपने अन्य तरह के Cloud Firestore डेटा को मैप करने या Swift में डेटा दिखाने के लिए, किन रणनीतियों का इस्तेमाल किया.
Cloud Firestore के Codable सपोर्ट का इस्तेमाल न करने की कोई वजह नहीं है.