
L'API Codable di Swift, introdotta in Swift 4, ci consente di sfruttare la potenza del compilatore per semplificare la mappatura dei dati dai formati serializzati ai tipi Swift.
Potresti aver utilizzato Codable per mappare i dati di un'API web al modello di dati della tua app (e viceversa), ma è molto più flessibile.
In questa guida vedremo come utilizzare Codable per mappare i dati da Cloud Firestore ai tipi Swift e viceversa.
Quando recupera un documento da Cloud Firestore, la tua app riceve un dizionario di coppie chiave/valore (o un array di dizionari, se utilizzi una delle operazioni che restituiscono più documenti).
Ora puoi continuare a utilizzare direttamente i dizionari in Swift, che offrono una grande flessibilità, ideale per il tuo caso d'uso. Tuttavia, questo approccio non è sicuro per i tipi ed è facile introdurre bug difficili da rintracciare a causa di errori ortografici nei nomi degli attributi o della mancata mappatura del nuovo attributo aggiunto dal tuo team quando ha rilasciato l'entusiasmante nuova funzionalità la settimana scorsa.
In passato, molti sviluppatori hanno aggirato queste carenze implementando un semplice livello di mapping che consentiva di mappare i dizionari ai tipi Swift. Ma ancora una volta, la maggior parte di queste implementazioni si basa sulla specifica manuale del mapping tra i documenti Cloud Firestore e i tipi corrispondenti del modello di dati della tua app.
Con il supporto di Cloud Firestore per l'API Codable di Swift, questa operazione diventa molto più semplice:
- Non dovrai più implementare manualmente alcun codice di mappatura.
- È facile definire come mappare gli attributi con nomi diversi.
- Ha un supporto integrato per molti tipi di Swift.
- Inoltre, è facile aggiungere il supporto per la mappatura dei tipi personalizzati.
- La cosa migliore è che per i modelli di dati semplici non dovrai scrivere alcun codice di mappatura.
Dati di mappatura
Cloud Firestore archivia i dati in documenti che mappano le chiavi ai valori. Per recuperare
i dati da un singolo documento, possiamo chiamare DocumentSnapshot.data(), che
restituisce un dizionario che mappa i nomi dei campi a un Any:
func data() -> [String : Any]?.
Ciò significa che possiamo utilizzare la sintassi di indice di Swift per accedere a ogni singolo campo.
import FirebaseFirestore
#warning("DO NOT MAP YOUR DOCUMENTS MANUALLY. USE CODABLE INSTEAD.")
func fetchBook(documentId: String) {
let docRef = db.collection("books").document(documentId)
docRef.getDocument { document, error in
if let error = error as NSError? {
self.errorMessage = "Error getting document: \(error.localizedDescription)"
}
else {
if let document = document {
let id = document.documentID
let data = document.data()
let title = data?["title"] as? String ?? ""
let numberOfPages = data?["numberOfPages"] as? Int ?? 0
let author = data?["author"] as? String ?? ""
self.book = Book(id:id, title: title, numberOfPages: numberOfPages, author: author)
}
}
}
}
Anche se può sembrare semplice e facile da implementare, questo codice è fragile, difficile da gestire e soggetto a errori.
Come puoi vedere, stiamo facendo delle ipotesi sui tipi di dati dei campi del documento. Questi potrebbero essere corretti o meno.
Ricorda che, non essendoci uno schema, puoi aggiungere facilmente un nuovo documento
alla raccolta e scegliere un tipo diverso per un campo. Potresti
scegliere accidentalmente la stringa per il campo numberOfPages, il che comporterebbe
un problema di mappatura difficile da trovare. Inoltre, dovrai aggiornare il codice di mapping ogni volta che viene aggiunto un nuovo campo, il che è piuttosto macchinoso.
E non dimentichiamo che non stiamo sfruttando il sistema di tipi
di Swift, che conosce esattamente il tipo corretto per ciascuna delle proprietà di
Book.
Che cos'è Codable?
Secondo la documentazione di Apple, Codable è "un tipo che può convertirsi in una rappresentazione esterna e viceversa". Infatti, Codable è un alias di tipo per i protocolli Encodable e Decodable. Se un tipo Swift è conforme a questo protocollo, il compilatore sintetizzerà il codice necessario per codificare/decodificare un'istanza di questo tipo da un formato serializzato, ad esempio JSON.
Un tipo semplice per memorizzare i dati di un libro potrebbe avere il seguente aspetto:
struct Book: Codable {
var title: String
var numberOfPages: Int
var author: String
}
Come puoi vedere, la conformità del tipo a Codable è minimamente invasiva. Abbiamo dovuto solo aggiungere la conformità al protocollo, senza apportare altre modifiche.
A questo punto, possiamo codificare facilmente un libro in un oggetto JSON:
do {
let book = Book(title: "The Hitchhiker's Guide to the Galaxy",
numberOfPages: 816,
author: "Douglas Adams")
let encoder = JSONEncoder()
let data = try encoder.encode(book)
}
catch {
print("Error when trying to encode book: \(error)")
}
La decodifica di un oggetto JSON in un'istanza Book funziona nel seguente modo:
let decoder = JSONDecoder()
let data = /* fetch data from the network */
let decodedBook = try decoder.decode(Book.self, from: data)
Mapping da e verso tipi semplici nei documenti Cloud Firestore utilizzando Codable
Cloud Firestore supporta un'ampia gamma di tipi di dati, dalle stringhe semplici alle mappe nidificate. La maggior parte di questi tipi corrisponde direttamente ai tipi integrati di Swift. Diamo un'occhiata alla mappatura di alcuni tipi di dati semplici prima di passare a quelli più complessi.
Per mappare i documenti Cloud Firestore ai tipi Swift:
- Assicurati di aver aggiunto il framework
FirebaseFirestoreal tuo progetto. Per farlo, puoi utilizzare Swift Package Manager o CocoaPods. - Importa
FirebaseFirestorenel file Swift. - Conferma il tuo tipo su
Codable. - (Facoltativo, se vuoi utilizzare la visualizzazione
List) Aggiungi una proprietàidal tipo e utilizza@DocumentIDper indicare a Cloud Firestore di mappare questa proprietà all'ID documento. Ne parleremo più in dettaglio di seguito. - Utilizza
documentReference.data(as: )per mappare un riferimento a un documento a un tipo Swift. - Utilizza
documentReference.setData(from: )per mappare i dati dai tipi Swift a un documento Cloud Firestore. - (Facoltativo, ma vivamente consigliato) Implementa una gestione degli errori corretta.
Aggiorniamo il tipo di Book di conseguenza:
struct Book: Codable {
@DocumentID var id: String?
var title: String
var numberOfPages: Int
var author: String
}
Poiché questo tipo era già codificabile, abbiamo dovuto aggiungere solo la proprietà id e
annotarla con il wrapper della proprietà @DocumentID.
Prendendo lo snippet di codice precedente per recuperare e mappare un documento, possiamo sostituire tutto il codice di mappatura manuale con una sola riga:
func fetchBook(documentId: String) {
let docRef = db.collection("books").document(documentId)
docRef.getDocument { document, error in
if let error = error as NSError? {
self.errorMessage = "Error getting document: \(error.localizedDescription)"
}
else {
if let document = document {
do {
self.book = try document.data(as: Book.self)
}
catch {
print(error)
}
}
}
}
}
Puoi scrivere questo in modo ancora più conciso specificando il tipo di documento
quando chiami getDocument(as:). In questo modo verrà eseguita la mappatura e verrà restituito un tipo Result contenente il documento mappato o un errore in caso di errore di decodifica:
private func fetchBook(documentId: String) {
let docRef = db.collection("books").document(documentId)
docRef.getDocument(as: Book.self) { result in
switch result {
case .success(let book):
// A Book value was successfully initialized from the DocumentSnapshot.
self.book = book
self.errorMessage = nil
case .failure(let error):
// A Book value could not be initialized from the DocumentSnapshot.
self.errorMessage = "Error decoding document: \(error.localizedDescription)"
}
}
}
L'aggiornamento di un documento esistente è semplice come chiamare
documentReference.setData(from: ). Includendo una gestione di base degli errori, ecco
il codice per salvare un'istanza Book:
func updateBook(book: Book) {
if let id = book.id {
let docRef = db.collection("books").document(id)
do {
try docRef.setData(from: book)
}
catch {
print(error)
}
}
}
Quando aggiungi un nuovo documento, Cloud Firestore si occuperà automaticamente di assegnare un nuovo ID al documento. Funziona anche quando l'app è offline.
func addBook(book: Book) {
let collectionRef = db.collection("books")
do {
let newDocReference = try collectionRef.addDocument(from: self.book)
print("Book stored with new document reference: \(newDocReference)")
}
catch {
print(error)
}
}
Oltre a mappare i tipi di dati semplici, Cloud Firestore supporta una serie di altri tipi di dati, alcuni dei quali sono tipi strutturati che puoi utilizzare per creare oggetti nidificati all'interno di un documento.
Tipi personalizzati nidificati
La maggior parte degli attributi che vogliamo mappare nei nostri documenti sono valori semplici, come il titolo del libro o il nome dell'autore. Ma cosa succede quando dobbiamo memorizzare un oggetto più complesso? Ad esempio, potremmo voler memorizzare gli URL della copertina del libro in risoluzioni diverse.
Il modo più semplice per farlo in Cloud Firestore è utilizzare una mappa:

Quando scriviamo la struct Swift corrispondente, possiamo sfruttare il fatto che Cloud Firestore supporta gli URL. Quando memorizziamo un campo che contiene un URL, questo viene convertito in una stringa e viceversa:
struct CoverImages: Codable {
var small: URL
var medium: URL
var large: URL
}
struct BookWithCoverImages: Codable {
@DocumentID var id: String?
var title: String
var numberOfPages: Int
var author: String
var cover: CoverImages?
}
Nota come abbiamo definito una struttura, CoverImages, per la mappa di copertura nel
documento Cloud Firestore. Se contrassegniamo la proprietà copertina su
BookWithCoverImages come facoltativa, possiamo gestire il fatto che alcuni
documenti potrebbero non contenere un attributo copertina.
Se ti stai chiedendo perché non esiste uno snippet di codice per recuperare o aggiornare i dati, sarai felice di sapere che non è necessario modificare il codice per leggere o scrivere da/su Cloud Firestore: tutto questo funziona con il codice che abbiamo scritto nella sezione iniziale.
Array
A volte vogliamo archiviare una raccolta di valori in un documento. I generi di un libro sono un buon esempio: un libro come Guida galattica per autostoppisti potrebbe rientrare in diverse categorie, in questo caso "Fantascienza" e "Commedia":

In Cloud Firestore, possiamo modellare questo aspetto utilizzando un array di valori. Questa operazione è
supportata per qualsiasi tipo codificabile (ad esempio String, Int e così via). Il seguente
mostra come aggiungere un array di generi al nostro modello Book:
public struct BookWithGenre: Codable {
@DocumentID var id: String?
var title: String
var numberOfPages: Int
var author: String
var genres: [String]
}
Poiché funziona per qualsiasi tipo codificabile, possiamo utilizzare anche tipi personalizzati. Supponiamo di voler memorizzare un elenco di tag per ogni libro. Oltre al nome del tag, vorremmo memorizzare anche il colore del tag, in questo modo:
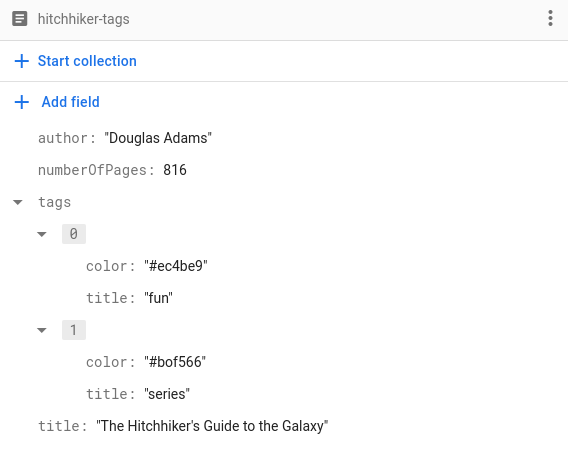
Per memorizzare i tag in questo modo, è sufficiente implementare una struttura Tag per
rappresentare un tag e renderlo codificabile:
struct Tag: Codable, Hashable {
var title: String
var color: String
}
E così possiamo memorizzare un array di Tags nei nostri documenti Book.
struct BookWithTags: Codable {
@DocumentID var id: String?
var title: String
var numberOfPages: Int
var author: String
var tags: [Tag]
}
Breve accenno alla mappatura degli ID documento
Prima di passare a mappare altri tipi, parliamo un attimo della mappatura degli ID documento.
In alcuni degli esempi precedenti abbiamo utilizzato il wrapper della proprietà @DocumentID
per mappare l'ID documento dei nostri documenti Cloud Firestore alla proprietà id
dei nostri tipi Swift. Questo è importante per diversi motivi:
- Ci aiuta a sapere quale documento aggiornare nel caso in cui l'utente apporti modifiche locali.
Listdi SwiftUI richiede che i suoi elementi sianoIdentifiableper evitare che gli elementi saltino quando vengono inseriti.
È importante sottolineare che un attributo contrassegnato come @DocumentID non verrà
codificato dal codificatore di Cloud Firestore durante la riscrittura del documento. Questo perché l'ID documento non è un attributo del documento stesso, quindi scriverlo nel documento sarebbe un errore.
Quando lavori con tipi nidificati (come l'array di tag in Book in un
esempio precedente di questa guida), non è necessario aggiungere una proprietà @DocumentID: le proprietà nidificate fanno parte del documento Cloud Firestore e
non costituiscono un documento separato. Pertanto, non hanno bisogno di un ID documento.
Date e ore
Cloud Firestore ha un tipo di dati integrato per la gestione di date e ore e, grazie al supporto di Codable di Cloud Firestore, è semplice utilizzarli.
Diamo un'occhiata a questo documento che rappresenta la madre di tutti i linguaggi di programmazione, Ada, inventato nel 1843:

Un tipo Swift per mappare questo documento potrebbe avere il seguente aspetto:
struct ProgrammingLanguage: Codable {
@DocumentID var id: String?
var name: String
var year: Date
}
Non possiamo lasciare questa sezione su date e orari senza parlare di @ServerTimestamp. Questo wrapper di proprietà è un vero e proprio strumento per
gestire i timestamp nella tua app.
In qualsiasi sistema distribuito, è probabile che gli orologi dei singoli sistemi non siano sempre completamente sincronizzati. Potresti pensare che non sia un problema grave, ma immagina le implicazioni di un orologio leggermente fuori sincronizzazione per un sistema di compravendita di azioni: anche una deviazione di un millisecondo potrebbe comportare una differenza di milioni di dollari durante l'esecuzione di una transazione.
Cloud Firestore gestisce gli attributi contrassegnati con @ServerTimestamp come
segue: se l'attributo è nil quando lo memorizzi (utilizzando addDocument(), ad
esempio), Cloud Firestore compilerà il campo con il timestamp del server corrente
al momento della scrittura nel database. Se il campo non è nil
quando chiami addDocument() o updateData(), Cloud Firestore lascerà
il valore dell'attributo invariato. In questo modo, è facile implementare campi come
createdAt e lastUpdatedAt.
Geopoints
Le geolocalizzazioni sono onnipresenti nelle nostre app. La memorizzazione consente di utilizzare molte funzionalità entusiasmanti. Ad esempio, potrebbe essere utile memorizzare una posizione per un'attività in modo che l'app possa ricordarti un'attività quando raggiungi una destinazione.
Cloud Firestore ha un tipo di dati integrato, GeoPoint, che può memorizzare la
longitudine e la latitudine di qualsiasi posizione. Per mappare le posizioni da/a un documento Cloud Firestore, possiamo utilizzare il tipo GeoPoint:
struct Office: Codable {
@DocumentID var id: String?
var name: String
var location: GeoPoint
}
Il tipo corrispondente in Swift è CLLocationCoordinate2D e possiamo eseguire il mapping
tra questi due tipi con la seguente operazione:
CLLocationCoordinate2D(latitude: office.location.latitude,
longitude: office.location.longitude)
Per saperne di più sull'interrogazione dei documenti in base alla posizione fisica, consulta questa guida alla soluzione.
Enum
Gli enum sono probabilmente una delle funzionalità del linguaggio Swift più sottovalutate;
sono molto più di quello che sembra. Un caso d'uso comune per gli enum è quello di
modellare gli stati discreti di qualcosa. Ad esempio, potremmo scrivere un'app
per la gestione degli articoli. Per monitorare lo stato di un articolo, potremmo voler utilizzare
un enum Status:
enum Status: String, Codable {
case draft
case inReview
case approved
case published
}
Cloud Firestore non supporta le enumerazioni in modo nativo (ovvero non può applicare l'insieme di valori), ma possiamo comunque sfruttare il fatto che le enumerazioni possono essere digitate e scegliere un tipo codificabile. In questo esempio abbiamo scelto String, il che significa che
tutti i valori enum verranno mappati da/a stringa quando vengono memorizzati in un
documento Cloud Firestore.
Inoltre, poiché Swift supporta i valori non elaborati personalizzati, possiamo persino personalizzare i valori
che si riferiscono a quale caso di enumerazione. Ad esempio, se decidessimo di memorizzare lo stato
Status.inReview come "in revisione", potremmo semplicemente aggiornare l'enumerazione precedente come
segue:
enum Status: String, Codable {
case draft
case inReview = "in review"
case approved
case published
}
Personalizzare il mapping
A volte, i nomi degli attributi dei documenti Cloud Firestore che vogliamo mappare non corrispondono ai nomi delle proprietà nel nostro modello di dati in Swift. Ad esempio, uno dei nostri colleghi potrebbe essere uno sviluppatore Python e ha deciso di scegliere snake_case per tutti i nomi degli attributi.
Non preoccuparti: Codable ci aiuta.
Per casi come questi, possiamo utilizzare CodingKeys. Si tratta di un'enumerazione che possiamo
aggiungere a una struttura codificabile per specificare come verranno mappati determinati attributi.
Considera questo documento:

Per mappare questo documento a una struttura con una proprietà name di tipo String, dobbiamo
aggiungere un'enumerazione CodingKeys alla struttura ProgrammingLanguage e specificare
il nome dell'attributo nel documento:
struct ProgrammingLanguage: Codable {
@DocumentID var id: String?
var name: String
var year: Date
enum CodingKeys: String, CodingKey {
case id
case name = "language_name"
case year
}
}
Per impostazione predefinita, l'API Codable utilizza i nomi delle proprietà dei nostri tipi Swift per determinare i nomi degli attributi nei documenti Cloud Firestore che stiamo cercando di mappare. Pertanto, se i nomi degli attributi corrispondono, non è necessario aggiungere
CodingKeys ai nostri tipi codificabili. Tuttavia, una volta utilizzato CodingKeys per un tipo specifico, dobbiamo aggiungere tutti i nomi delle proprietà che vogliamo mappare.
Nello snippet di codice riportato sopra, abbiamo definito una proprietà id che potremmo voler
utilizzare come identificatore in una visualizzazione List SwiftUI. Se non lo avessimo specificato in
CodingKeys, non sarebbe stato mappato durante il recupero dei dati e quindi sarebbe diventato nil.
Di conseguenza, la visualizzazione List verrà riempita con il primo documento.
Qualsiasi proprietà non elencata come caso nell'enumerazione CodingKeys
verrà ignorata durante la procedura di mappatura. Ciò può essere utile se
vogliamo escludere alcune proprietà dalla mappatura.
Ad esempio, se vogliamo escludere la proprietà reasonWhyILoveThis dalla mappatura, è sufficiente rimuoverla dall'enumerazione CodingKeys:
struct ProgrammingLanguage: Identifiable, Codable {
@DocumentID var id: String?
var name: String
var year: Date
var reasonWhyILoveThis: String = ""
enum CodingKeys: String, CodingKey {
case id
case name = "language_name"
case year
}
}
A volte potremmo voler scrivere un attributo vuoto nel documento
Cloud Firestore. Swift ha la nozione di opzionali per indicare l'assenza di un valore e Cloud Firestore supporta anche i valori null.
Tuttavia, il comportamento predefinito per la codifica dei parametri opzionali con un valore nil è
di ometterli. @ExplicitNull ci consente di controllare in che modo vengono gestiti gli optional Swift durante la codifica: contrassegnando una proprietà facoltativa come @ExplicitNull, possiamo indicare a Cloud Firestore di scrivere questa proprietà nel documento con un valore nullo se contiene un valore nil.
Utilizzo di un codificatore e un decodificatore personalizzati per mappare i colori
Come ultimo argomento della nostra copertura della mappatura dei dati con Codable, introduciamo codificatori e decodificatori personalizzati. Questa sezione non riguarda un tipo di dati Cloud Firestore nativo, ma i codificatori e decodificatori personalizzati sono molto utili nelle tue app Cloud Firestore.
"Come posso mappare i colori?" è una delle domande più frequenti degli sviluppatori, non solo per Cloud Firestore, ma anche per la mappatura tra Swift e JSON. Esistono molte soluzioni, ma la maggior parte si concentra su JSON e quasi tutte mappano i colori come un dizionario nidificato composto dai relativi componenti RGB.
Sembra che dovrebbe esserci una soluzione migliore e più semplice. Perché non utilizziamo i colori web (o, per essere più precisi, la notazione esadecimale dei colori CSS)? Sono facili da usare (essenzialmente una stringa) e supportano anche la trasparenza.
Per poter mappare uno Swift Color al suo valore esadecimale, dobbiamo creare un'estensione Swift
che aggiunga Codable a Color.
extension Color {
init(hex: String) {
let rgba = hex.toRGBA()
self.init(.sRGB,
red: Double(rgba.r),
green: Double(rgba.g),
blue: Double(rgba.b),
opacity: Double(rgba.alpha))
}
//... (code for translating between hex and RGBA omitted for brevity)
}
extension Color: Codable {
public init(from decoder: Decoder) throws {
let container = try decoder.singleValueContainer()
let hex = try container.decode(String.self)
self.init(hex: hex)
}
public func encode(to encoder: Encoder) throws {
var container = encoder.singleValueContainer()
try container.encode(toHex)
}
}
Utilizzando decoder.singleValueContainer(), possiamo decodificare un String nel suo
equivalente Color, senza dover nidificare i componenti RGBA. Inoltre, puoi
utilizzare questi valori nell'interfaccia utente web della tua app, senza doverli convertire
prima.
In questo modo, possiamo aggiornare il codice per mappare i tag, semplificando la gestione dei colori dei tag direttamente anziché doverli mappare manualmente nel codice della UI della nostra app:
struct Tag: Codable, Hashable {
var title: String
var color: Color
}
struct BookWithTags: Codable {
@DocumentID var id: String?
var title: String
var numberOfPages: Int
var author: String
var tags: [Tag]
}
Gestione degli errori
Negli snippet di codice riportati sopra abbiamo intenzionalmente ridotto al minimo la gestione degli errori, ma in un'app di produzione, dovrai assicurarti di gestire correttamente eventuali errori.
Ecco uno snippet di codice che mostra come gestire eventuali situazioni di errore in cui potresti incorrere:
class MappingSimpleTypesViewModel: ObservableObject {
@Published var book: Book = .empty
@Published var errorMessage: String?
private var db = Firestore.firestore()
func fetchAndMap() {
fetchBook(documentId: "hitchhiker")
}
func fetchAndMapNonExisting() {
fetchBook(documentId: "does-not-exist")
}
func fetchAndTryMappingInvalidData() {
fetchBook(documentId: "invalid-data")
}
private func fetchBook(documentId: String) {
let docRef = db.collection("books").document(documentId)
docRef.getDocument(as: Book.self) { result in
switch result {
case .success(let book):
// A Book value was successfully initialized from the DocumentSnapshot.
self.book = book
self.errorMessage = nil
case .failure(let error):
// A Book value could not be initialized from the DocumentSnapshot.
switch error {
case DecodingError.typeMismatch(_, let context):
self.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.valueNotFound(_, let context):
self.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.keyNotFound(_, let context):
self.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.dataCorrupted(let key):
self.errorMessage = "\(error.localizedDescription): \(key)"
default:
self.errorMessage = "Error decoding document: \(error.localizedDescription)"
}
}
}
}
}
Gestione degli errori negli aggiornamenti in tempo reale
Lo snippet di codice precedente mostra come gestire gli errori durante il recupero di un singolo documento. Oltre a recuperare i dati una sola volta, Cloud Firestore supporta anche la distribuzione degli aggiornamenti alla tua app man mano che si verificano, utilizzando i cosiddetti listener di snapshot: possiamo registrare un listener di snapshot su una raccolta (o query) e Cloud Firestore chiamerà il nostro listener ogni volta che si verifica un aggiornamento.
Ecco uno snippet di codice che mostra come registrare un listener di snapshot, mappare i dati utilizzando Codable e gestire eventuali errori che potrebbero verificarsi. Mostra anche come aggiungere un nuovo documento alla raccolta. Come vedrai, non è necessario aggiornare l'array locale contenente i documenti mappati, poiché questa operazione viene eseguita dal codice nel listener dello snapshot.
class MappingColorsViewModel: ObservableObject {
@Published var colorEntries = [ColorEntry]()
@Published var newColor = ColorEntry.empty
@Published var errorMessage: String?
private var db = Firestore.firestore()
private var listenerRegistration: ListenerRegistration?
public func unsubscribe() {
if listenerRegistration != nil {
listenerRegistration?.remove()
listenerRegistration = nil
}
}
func subscribe() {
if listenerRegistration == nil {
listenerRegistration = db.collection("colors")
.addSnapshotListener { [weak self] (querySnapshot, error) in
guard let documents = querySnapshot?.documents else {
self?.errorMessage = "No documents in 'colors' collection"
return
}
self?.colorEntries = documents.compactMap { queryDocumentSnapshot in
let result = Result { try queryDocumentSnapshot.data(as: ColorEntry.self) }
switch result {
case .success(let colorEntry):
if let colorEntry = colorEntry {
// A ColorEntry value was successfully initialized from the DocumentSnapshot.
self?.errorMessage = nil
return colorEntry
}
else {
// A nil value was successfully initialized from the DocumentSnapshot,
// or the DocumentSnapshot was nil.
self?.errorMessage = "Document doesn't exist."
return nil
}
case .failure(let error):
// A ColorEntry value could not be initialized from the DocumentSnapshot.
switch error {
case DecodingError.typeMismatch(_, let context):
self?.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.valueNotFound(_, let context):
self?.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.keyNotFound(_, let context):
self?.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.dataCorrupted(let key):
self?.errorMessage = "\(error.localizedDescription): \(key)"
default:
self?.errorMessage = "Error decoding document: \(error.localizedDescription)"
}
return nil
}
}
}
}
}
func addColorEntry() {
let collectionRef = db.collection("colors")
do {
let newDocReference = try collectionRef.addDocument(from: newColor)
print("ColorEntry stored with new document reference: \(newDocReference)")
}
catch {
print(error)
}
}
}
Tutti gli snippet di codice utilizzati in questo post fanno parte di un'applicazione di esempio che puoi scaricare da questo repository GitHub.
Inizia subito a utilizzare Codable.
L'API Codable di Swift fornisce un modo potente e flessibile per mappare i dati da formati serializzati al modello di dati delle applicazioni e viceversa. In questa guida, hai visto quanto è facile da usare nelle app che utilizzano Cloud Firestore come datastore.
Partendo da un esempio di base con tipi di dati semplici, abbiamo aumentato progressivamente la complessità del modello di dati, potendo sempre fare affidamento su Codable e sull'implementazione di Firebase per eseguire la mappatura.
Per maggiori dettagli su Codable, ti consiglio le seguenti risorse:
- John Sundell ha scritto un bell'articolo sulle basi di Codable.
- Se preferisci i libri, dai un'occhiata alla guida di Flight School a Swift Codable di Mattt.
- Infine, Donny Wals ha un'intera serie su Codable.
Sebbene abbiamo fatto del nostro meglio per compilare una guida completa per la mappatura dei documenti Cloud Firestore, questa non è esaustiva e potresti utilizzare altre strategie per mappare i tuoi tipi. Utilizzando il pulsante Invia feedback qui sotto, comunica le strategie che utilizzi per mappare altri tipi di dati Cloud Firestore o per rappresentare i dati in Swift.
Non c'è davvero motivo per non utilizzare il supporto Codable di Cloud Firestore.