
Codable API של Swift, שהושק ב-Swift 4, מאפשר לנו להשתמש ביכולות של הקומפיילר כדי למפות נתונים מפורמטים מסודרים לסוגי Swift בצורה קלה יותר.
יכול להיות שהשתמשתם ב-Codable כדי למפות נתונים מ-API של אינטרנט למודל הנתונים של האפליקציה (ולהפך), אבל הוא הרבה יותר גמיש מזה.
במדריך הזה נסביר איך אפשר להשתמש ב-Codable כדי למפות נתונים מ-Cloud Firestore לסוגי Swift ולהיפך.
כשמאחזרים מסמך מ-Cloud Firestore, האפליקציה מקבלת מילון של צמדי מפתח/ערך (או מערך של מילונים, אם משתמשים באחת מהפעולות שמחזירות כמה מסמכים).
אפשר להמשיך להשתמש ישירות במילונים ב-Swift, והם מציעים גמישות רבה שעשויה להתאים בדיוק לתרחיש השימוש שלכם. עם זאת, הגישה הזו לא בטוחה מבחינת סוגי נתונים, וקל להכניס באגים שקשה לאתר אם מאייתים לא נכון את שמות המאפיינים או שוכחים למפות את המאפיין החדש שהצוות הוסיף כשפיתח את התכונה החדשה והמרגשת בשבוע שעבר.
בעבר, מפתחים רבים עקפו את החסרונות האלה באמצעות הטמעה של שכבת מיפוי פשוטה שאיפשרה להם למפות מילונים לסוגי Swift. אבל שוב, רוב ההטמעות האלה מבוססות על הגדרה ידנית של המיפוי בין מסמכי Cloud Firestore לבין הסוגים התואמים של מודל הנתונים של האפליקציה.
התמיכה של Cloud Firestore ב-Codable API של Swift הופכת את התהליך להרבה יותר פשוט:
- לא תצטרכו יותר להטמיע קוד מיפוי באופן ידני.
- קל להגדיר איך למפות מאפיינים עם שמות שונים.
- יש בו תמיכה מובנית בסוגים רבים של Swift.
- בנוסף, קל להוסיף תמיכה במיפוי סוגים מותאמים אישית.
- והכי חשוב: במודלים פשוטים של נתונים, לא תצטרכו לכתוב קוד מיפוי בכלל.
מיפוי נתונים
Cloud Firestore מאחסן נתונים במסמכים שממפים מפתחות לערכים. כדי לאחזר נתונים ממסמך ספציפי, אפשר להפעיל את הפונקציה DocumentSnapshot.data(), שמחזירה מילון עם מיפוי של שמות השדות ל-Any:
func data() -> [String : Any]?.
כלומר, אפשר להשתמש בתחביר של subscript ב-Swift כדי לגשת לכל שדה בנפרד.
import FirebaseFirestore
#warning("DO NOT MAP YOUR DOCUMENTS MANUALLY. USE CODABLE INSTEAD.")
func fetchBook(documentId: String) {
let docRef = db.collection("books").document(documentId)
docRef.getDocument { document, error in
if let error = error as NSError? {
self.errorMessage = "Error getting document: \(error.localizedDescription)"
}
else {
if let document = document {
let id = document.documentID
let data = document.data()
let title = data?["title"] as? String ?? ""
let numberOfPages = data?["numberOfPages"] as? Int ?? 0
let author = data?["author"] as? String ?? ""
self.book = Book(id:id, title: title, numberOfPages: numberOfPages, author: author)
}
}
}
}
למרות שנדמה שמדובר בקוד פשוט וקל להטמעה, הוא שביר, קשה לתחזוקה ונוטה לשגיאות.
כמו שאפשר לראות, אנחנו מניחים הנחות לגבי סוגי הנתונים של השדות במסמך. יכול להיות שהתשובות האלה נכונות ויכול להיות שלא.
חשוב לזכור: מכיוון שאין סכימה, אפשר בקלות להוסיף מסמך חדש לאוסף ולבחור סוג אחר לשדה. יכול להיות שתבחרו בטעות במחרוזת בשדה numberOfPages, וכתוצאה מכך תהיה בעיה במיפוי שקשה למצוא. בנוסף, תצטרכו לעדכן את קוד המיפוי בכל פעם שתוסיפו שדה חדש, וזה די מסורבל.
בנוסף, אנחנו לא מנצלים את מערכת הטיפוס החזקה של Swift, שמזהה בדיוק את הסוג הנכון של כל אחת מהמאפיינים של Book.
מה זה Codable?
לפי התיעוד של Apple, Codable הוא "סוג שיכול להמיר את עצמו לייצוג חיצוני וממנו". למעשה, Codable הוא שם בדוי לסוג של הפרוטוקולים Encodable ו-Decodable. אם סוג Swift תואם לפרוטוקול הזה, הקומפיילר יבצע סינתזה של הקוד שנדרש כדי לקודד/לפענח מופע של הסוג הזה מפורמט סריאלי, כמו JSON.
סוג פשוט לאחסון נתונים על ספר יכול להיראות כך:
struct Book: Codable {
var title: String
var numberOfPages: Int
var author: String
}
כמו שאפשר לראות, התאמת הסוג ל-Codable היא פולשנית באופן מינימלי. היינו צריכים רק להוסיף את התאימות לפרוטוקול, ולא נדרשו שינויים נוספים.
אחרי שקבענו את זה, אנחנו יכולים לקודד בקלות ספר לאובייקט JSON:
do {
let book = Book(title: "The Hitchhiker's Guide to the Galaxy",
numberOfPages: 816,
author: "Douglas Adams")
let encoder = JSONEncoder()
let data = try encoder.encode(book)
}
catch {
print("Error when trying to encode book: \(error)")
}
פענוח של אובייקט JSON למופע Book מתבצע באופן הבא:
let decoder = JSONDecoder()
let data = /* fetch data from the network */
let decodedBook = try decoder.decode(Book.self, from: data)
מיפוי מסוגים פשוטים במסמכי Cloud Firestore באמצעות Codable
Cloud Firestore תומך במגוון רחב של סוגי נתונים, החל ממחרוזות פשוטות ועד למפות מקוננות. רובם תואמים ישירות לסוגים המובנים של Swift. לפני שנעבור לסוגי נתונים מורכבים יותר, נתחיל עם מיפוי של כמה סוגי נתונים פשוטים.
כדי למפות מסמכי Cloud Firestore לסוגי Swift, פועלים לפי השלבים הבאים:
- מוודאים שהוספתם את
FirebaseFirestoreframework לפרויקט. אפשר להשתמש ב-Swift Package Manager או ב-CocoaPods. - מייבאים את
FirebaseFirestoreלקובץ Swift. - התאמת הסוג ל-
Codable. - (אופציונלי, אם רוצים להשתמש בסוג בתצוגה
List) מוסיפים מאפייןidלסוג, ומשתמשים ב-@DocumentIDכדי להנחות את Cloud Firestore למפות את המאפיין הזה למזהה המסמך. בהמשך נסביר על כך בפירוט. - אפשר להשתמש ב-
documentReference.data(as: )כדי למפות הפניה למסמך לסוג Swift. - משתמשים ב-
documentReference.setData(from: )כדי למפות נתונים מסוגי Swift למסמך Cloud Firestore. - (אופציונלי, אבל מומלץ מאוד) הטמעת טיפול בשגיאות.
אנחנו יכולים לעדכן את סוג Book בהתאם:
struct Book: Codable {
@DocumentID var id: String?
var title: String
var numberOfPages: Int
var author: String
}
מכיוון שהסוג הזה כבר היה ניתן לקידוד, נדרשנו רק להוסיף את המאפיין id ולציין אותו באמצעות עטיפת המאפיין @DocumentID.
אם ניקח את קטע הקוד הקודם לאחזור ולמיפוי של מסמך, נוכל להחליף את כל קוד המיפוי הידני בשורה אחת:
func fetchBook(documentId: String) {
let docRef = db.collection("books").document(documentId)
docRef.getDocument { document, error in
if let error = error as NSError? {
self.errorMessage = "Error getting document: \(error.localizedDescription)"
}
else {
if let document = document {
do {
self.book = try document.data(as: Book.self)
}
catch {
print(error)
}
}
}
}
}
אפשר לכתוב את זה בצורה תמציתית יותר על ידי ציון סוג המסמך כשקוראים ל-getDocument(as:). הפעולה הזו תבצע את המיפוי ותחזיר סוג Result שמכיל את המסמך הממופה, או שגיאה אם פענוח הקידוד נכשל:
private func fetchBook(documentId: String) {
let docRef = db.collection("books").document(documentId)
docRef.getDocument(as: Book.self) { result in
switch result {
case .success(let book):
// A Book value was successfully initialized from the DocumentSnapshot.
self.book = book
self.errorMessage = nil
case .failure(let error):
// A Book value could not be initialized from the DocumentSnapshot.
self.errorMessage = "Error decoding document: \(error.localizedDescription)"
}
}
}
כדי לעדכן מסמך קיים, פשוט קוראים ל-documentReference.setData(from: ). הנה קוד לשמירת מופע של Book, כולל טיפול בסיסי בשגיאות:
func updateBook(book: Book) {
if let id = book.id {
let docRef = db.collection("books").document(id)
do {
try docRef.setData(from: book)
}
catch {
print(error)
}
}
}
כשמוסיפים מסמך חדש, Cloud Firestore דואג באופן אוטומטי להקצאת מזהה מסמך חדש למסמך. הפעולה הזו אפשרית גם כשהאפליקציה במצב אופליין.
func addBook(book: Book) {
let collectionRef = db.collection("books")
do {
let newDocReference = try collectionRef.addDocument(from: self.book)
print("Book stored with new document reference: \(newDocReference)")
}
catch {
print(error)
}
}
בנוסף למיפוי של סוגי נתונים פשוטים, Cloud Firestore תומך במספר סוגים אחרים של נתונים, חלקם סוגים מובנים שבהם אפשר להשתמש כדי ליצור אובייקטים מקוננים בתוך מסמך.
סוגים מותאמים אישית מוטמעים
רוב המאפיינים שאנחנו רוצים למפות במסמכים שלנו הם ערכים פשוטים, כמו שם הספר או שם המחבר. אבל מה קורה במקרים שבהם צריך לאחסן אובייקט מורכב יותר? לדוגמה, יכול להיות שנרצה לאחסן את כתובות ה-URL של כריכת הספר ברזולוציות שונות.
הדרך הכי קלה לעשות את זה ב-Cloud Firestore היא באמצעות מפה:

כשכותבים את מבנה ה-Swift המתאים, אפשר להשתמש בעובדה ש-Cloud Firestore תומך בכתובות URL – כשמאחסנים שדה שמכיל כתובת URL, הוא יומר למחרוזת ולהפך:
struct CoverImages: Codable {
var small: URL
var medium: URL
var large: URL
}
struct BookWithCoverImages: Codable {
@DocumentID var id: String?
var title: String
var numberOfPages: Int
var author: String
var cover: CoverImages?
}
שימו לב לאופן שבו הגדרנו מבנה, CoverImages, למפת הכיסוי במסמך Cloud Firestore. סימנו את מאפיין הכריכה ב-BookWithCoverImages כמאפיין אופציונלי, כדי שנוכל לטפל במצב שבו חלק מהמסמכים לא מכילים מאפיין כריכה.
אם אתם רוצים לדעת למה אין קטע קוד לאחזור או לעדכון נתונים, תשמחו לשמוע שאין צורך להתאים את הקוד לקריאה או לכתיבה מ-Cloud Firestore או אל Cloud Firestore: הכול עובד עם הקוד שכתבנו בקטע הראשון.
מערכים
לפעמים אנחנו רוצים לאחסן אוסף של ערכים במסמך. ז'אנרים של ספר הם דוגמה טובה: ספר כמו מדריך הטרמפיסט לגלקסיה יכול להשתייך לכמה קטגוריות – במקרה הזה, 'מדע בדיוני' ו'קומדיה':

ב-Cloud Firestore, אפשר ליצור מודל של זה באמצעות מערך של ערכים. התכונה הזו נתמכת בכל סוג שניתן לקידוד (כמו String, Int וכו'). בדוגמה הבאה אפשר לראות איך מוסיפים מערך של ז'אנרים למודל Book:
public struct BookWithGenre: Codable {
@DocumentID var id: String?
var title: String
var numberOfPages: Int
var author: String
var genres: [String]
}
מכיוון שהפעולה הזו מתאימה לכל סוג שניתן לקידוד, אפשר להשתמש גם בסוגים מותאמים אישית. נניח שאנחנו רוצים לאחסן רשימה של תגים לכל ספר. בנוסף לשם התג, אנחנו רוצים לאחסן גם את הצבע של התג, כך:
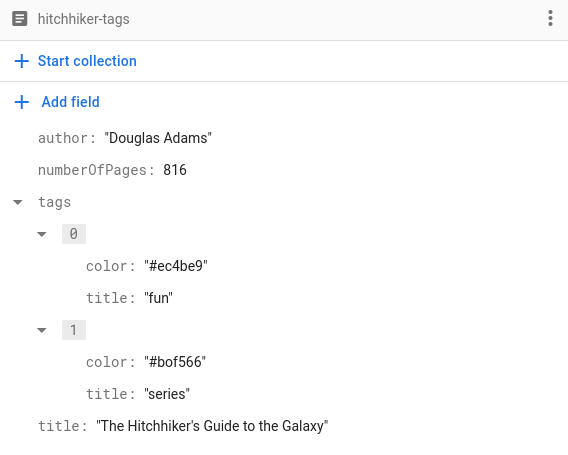
כדי לאחסן תגים בצורה הזו, צריך להטמיע מבנה Tag כדי לייצג תג ולהפוך אותו לניתן לקידוד:
struct Tag: Codable, Hashable {
var title: String
var color: String
}
וכך אפשר לאחסן מערך של Tags במסמכי Book!
struct BookWithTags: Codable {
@DocumentID var id: String?
var title: String
var numberOfPages: Int
var author: String
var tags: [Tag]
}
הסבר קצר על מיפוי מזהי מסמכים
לפני שנעבור למיפוי של סוגים נוספים, נדבר רגע על מיפוי של מזהי מסמכים.
השתמשנו ב-wrapper של המאפיין @DocumentID בחלק מהדוגמאות הקודמות כדי למפות את מזהה המסמך של מסמכי Cloud Firestore למאפיין id של סוגי Swift. הדבר חשוב מכמה סיבות:
- המידע הזה עוזר לנו לדעת איזה מסמך לעדכן במקרה שהמשתמש מבצע שינויים מקומיים.
- התכונה
Listב-SwiftUI מחייבת שהרכיבים שלה יהיוIdentifiableכדי למנוע מצב שבו הרכיבים קופצים כשמוסיפים אותם.
חשוב לציין שמאפיין שמסומן כ-@DocumentID לא יקודד על ידי המקודד של Cloud Firestore כשכותבים את המסמך בחזרה. הסיבה לכך היא שמזהה המסמך הוא לא מאפיין של המסמך עצמו, ולכן יהיה טעות לכתוב אותו במסמך.
כשעובדים עם סוגים מקוננים (כמו מערך התגים ב-Book בדוגמה מוקדמת יותר במדריך הזה), לא צריך להוסיף מאפיין @DocumentID: מאפיינים מקוננים הם חלק ממסמך Cloud Firestore, והם לא מהווים מסמך נפרד. לכן לא צריך להזין מזהה מסמך.
תאריכים ושעות
ל-Cloud Firestore יש סוג נתונים מובנה לטיפול בתאריכים ובשעות, ובזכות התמיכה של Cloud Firestore ב-Codable, קל להשתמש בהם.
בואו נסתכל על המסמך הזה שמייצג את שפת התכנות הראשונה, Ada, שהומצאה בשנת 1843:

סוג Swift למיפוי המסמך הזה יכול להיראות כך:
struct ProgrammingLanguage: Codable {
@DocumentID var id: String?
var name: String
var year: Date
}
אי אפשר לסיים את החלק הזה על תאריכים ושעות בלי לדבר על @ServerTimestamp. עטיפת המאפיין הזו היא כלי רב עוצמה כשמדובר בטיפול בחותמות זמן באפליקציה.
בכל מערכת מבוזרת, סביר להניח שהשעונים במערכות הנפרדות לא מסונכרנים לחלוטין כל הזמן. יכול להיות שזה לא נראה לכם עניין גדול, אבל תחשבו על ההשלכות של שעון שלא מסונכרן באופן מדויק במערכת למסחר במניות: אפילו סטייה של אלפית השנייה יכולה לגרום להבדל של מיליוני דולרים כשמבצעים מסחר.
Cloud Firestore מטפל במאפיינים שמסומנים ב-@ServerTimestamp באופן הבא: אם המאפיין הוא nil כשמאחסנים אותו (באמצעות addDocument(), לדוגמה), Cloud Firestore יאכלס את השדה עם חותמת הזמן הנוכחית של השרת בזמן הכתיבה למסד הנתונים. אם השדה לא nil כשמבצעים קריאה ל-addDocument() או ל-updateData(), הפונקציה Cloud Firestore לא תשנה את ערך המאפיין. כך קל להטמיע שדות כמו
createdAt ו-lastUpdatedAt.
נקודות גיאוגרפיות
מיקומים גיאוגרפיים נמצאים בכל האפליקציות שלנו. אחסון הנתונים מאפשר להשתמש בהרבה תכונות מעניינות. לדוגמה, יכול להיות שיהיה שימושי לשמור מיקום למשימה כדי שהאפליקציה תוכל להזכיר לכם לגבי משימה כשתגיעו ליעד.
ל-Cloud Firestore יש סוג נתונים מובנה, GeoPoint, שיכול לאחסן את קו האורך וקו הרוחב של כל מיקום. כדי למפות מיקומים ממסמך Cloud Firestore או אליו, אפשר להשתמש בסוג GeoPoint:
struct Office: Codable {
@DocumentID var id: String?
var name: String
var location: GeoPoint
}
הסוג המתאים ב-Swift הוא CLLocationCoordinate2D, ואפשר למפות בין שני הסוגים האלה באמצעות הפעולה הבאה:
CLLocationCoordinate2D(latitude: office.location.latitude,
longitude: office.location.longitude)
במדריך הפתרונות הזה מוסבר איך לשלוח שאילתות לגבי מסמכים לפי מיקום פיזי.
טיפוסים בני מנייה (enum)
סוגי ה-enum הם כנראה אחת התכונות הכי לא מוערכות בשפת Swift. יש בהם הרבה יותר ממה שנראה במבט ראשון. תרחיש נפוץ לשימוש בסוגי enum הוא
הצגה של מצבים נפרדים של משהו. לדוגמה, יכול להיות שאנחנו כותבים אפליקציה לניהול מאמרים. כדי לעקוב אחרי הסטטוס של מאמר, אפשר להשתמש ב-enum Status:
enum Status: String, Codable {
case draft
case inReview
case approved
case published
}
Cloud Firestore לא תומך ב-enums באופן מקורי (כלומר, הוא לא יכול לאכוף את קבוצת הערכים), אבל עדיין אפשר להשתמש בעובדה שאפשר להקליד enums ולבחור סוג ניתן לקידוד. בדוגמה הזו בחרנו באפשרות String, כלומר כל ערכי ה-enum ימופו למחרוזת או ממחרוזת כשהם מאוחסנים במסמך Cloud Firestore.
בנוסף, מכיוון ש-Swift תומכת בערכים גולמיים מותאמים אישית, אנחנו יכולים אפילו להתאים אישית את הערכים שמתייחסים לכל מקרה של enum. לדוגמה, אם החלטנו לאחסן את המקרה Status.inReview כ'בבדיקה', נוכל לעדכן את סוג הנתונים שצוין למעלה באופן הבא:
enum Status: String, Codable {
case draft
case inReview = "in review"
case approved
case published
}
התאמה אישית של המיפוי
לפעמים, שמות המאפיינים של מסמכי Cloud Firestore שאנחנו רוצים למפות לא תואמים לשמות המאפיינים במודל הנתונים שלנו ב-Swift. לדוגמה, אחד מהעובדים שלנו הוא מפתח Python, והוא החליט להשתמש בפורמט snake_case לכל שמות המאפיינים.
אל דאגה: Codable כאן בשבילנו!
במקרים כאלה, אפשר להשתמש בCodingKeys. זוהי ספירה שאפשר להוסיף למבנה ניתן לקידוד כדי לציין איך מאפיינים מסוימים ימופו.
קראתי את המסמך הזה:

כדי למפות את המסמך הזה למבנה (struct) שיש לו מאפיין שם מסוג String, צריך להוסיף ספירה (enum) CodingKeys למבנה ProgrammingLanguage ולציין את שם המאפיין במסמך:
struct ProgrammingLanguage: Codable {
@DocumentID var id: String?
var name: String
var year: Date
enum CodingKeys: String, CodingKey {
case id
case name = "language_name"
case year
}
}
כברירת מחדל, Codable API ישתמש בשמות המאפיינים של סוגי Swift כדי לקבוע את שמות המאפיינים במסמכי Cloud Firestore שאנחנו מנסים למפות. לכן, כל עוד שמות המאפיינים זהים, אין צורך להוסיף את CodingKeys לסוגים הניתנים לקידוד. עם זאת, אחרי שמשתמשים ב-CodingKeys לסוג מסוים, צריך להוסיף את כל שמות המאפיינים שרוצים למפות.
בקטע הקוד שלמעלה, הגדרנו מאפיין id שאולי נרצה להשתמש בו כמזהה בתצוגה List של SwiftUI. אם לא ציינו אותו ב-CodingKeys, הוא לא ימופה בזמן אחזור הנתונים, ולכן יהפוך ל-nil.
המסמך הראשון ימלא את התצוגה List.
כל נכס שלא מופיע כ-case ב-CodingKeys enum
המתאים יקבל התעלמות במהלך תהליך המיפוי. האפשרות הזו יכולה להיות נוחה אם רוצים להחריג מלונות מסוימים מהמיפוי.
לדוגמה, אם רוצים להחריג את הנכס reasonWhyILoveThis ממיפוי, כל מה שצריך לעשות הוא להסיר אותו מה-enum CodingKeys:
struct ProgrammingLanguage: Identifiable, Codable {
@DocumentID var id: String?
var name: String
var year: Date
var reasonWhyILoveThis: String = ""
enum CodingKeys: String, CodingKey {
case id
case name = "language_name"
case year
}
}
לפעמים נרצה לכתוב מאפיין ריק בחזרה למסמך Cloud Firestore. ב-Swift יש את המושג optionals שמציין היעדר ערך, ו-Cloud Firestore תומך גם בערכים null.
עם זאת, התנהגות ברירת המחדל של קידוד פרמטרים אופציונליים עם ערך nil היא פשוט להשמיט אותם. המאפיין @ExplicitNull מאפשר לנו לשלוט באופן הטיפול בערכים אופציונליים ב-Swift בזמן הקידוד שלהם: אם נסמן מאפיין אופציונלי כ-@ExplicitNull, נוכל להנחות את Cloud Firestore לכתוב את המאפיין הזה במסמך עם ערך null אם הוא מכיל ערך של nil.
שימוש במקודד ובמפענח מותאמים אישית למיפוי צבעים
כנושא אחרון בסקירה שלנו על מיפוי נתונים באמצעות Codable, נציג מקודדים ומפענחים מותאמים אישית. בקטע הזה לא מוסבר על סוג נתונים מקורי של Cloud Firestore, אבל מקודדים ומפענחים בהתאמה אישית יכולים להיות שימושיים מאוד באפליקציות Cloud Firestore.
"איך אפשר למפות צבעים" היא אחת השאלות הנפוצות ביותר בקרב מפתחים, לא רק לגבי Cloud Firestore, אלא גם לגבי מיפוי בין Swift ל-JSON. יש הרבה פתרונות, אבל רובם מתמקדים ב-JSON, וכמעט כולם ממפים צבעים כמילון מקונן שמורכב מרכיבי ה-RGB שלו.
נראה שיש פתרון טוב ופשוט יותר. למה אנחנו לא משתמשים בצבעי אינטרנט (או ליתר דיוק, בסימון צבעים הקסדצימליים של CSS)? קל להשתמש בהם (בעצם מדובר רק במחרוזת), והם אפילו תומכים בשקיפות!
כדי למפות מחרוזת Swift Color לערך ההקסדצימלי שלה, צריך ליצור תוסף Swift שמוסיף Codable ל-Color.
extension Color {
init(hex: String) {
let rgba = hex.toRGBA()
self.init(.sRGB,
red: Double(rgba.r),
green: Double(rgba.g),
blue: Double(rgba.b),
opacity: Double(rgba.alpha))
}
//... (code for translating between hex and RGBA omitted for brevity)
}
extension Color: Codable {
public init(from decoder: Decoder) throws {
let container = try decoder.singleValueContainer()
let hex = try container.decode(String.self)
self.init(hex: hex)
}
public func encode(to encoder: Encoder) throws {
var container = encoder.singleValueContainer()
try container.encode(toHex)
}
}
באמצעות decoder.singleValueContainer(), אפשר לפענח String למקבילה של Color, בלי להטמיע את רכיבי ה-RGBA. בנוסף, אפשר להשתמש בערכים האלה בממשק המשתמש האינטרנטי של האפליקציה בלי להמיר אותם קודם.
כך אנחנו יכולים לעדכן את הקוד למיפוי תגים, ולטפל בצבעי התגים ישירות במקום למפות אותם ידנית בקוד של ממשק המשתמש באפליקציה שלנו:
struct Tag: Codable, Hashable {
var title: String
var color: Color
}
struct BookWithTags: Codable {
@DocumentID var id: String?
var title: String
var numberOfPages: Int
var author: String
var tags: [Tag]
}
טיפול בשגיאות
בקטעי הקוד שלמעלה השארנו בכוונה את הטיפול בשגיאות ברמה מינימלית, אבל באפליקציה בסביבת ייצור, כדאי לטפל בשגיאות בצורה חלקה.
בקטע הקוד הבא אפשר לראות איך לטפל במצבי שגיאה שונים:
class MappingSimpleTypesViewModel: ObservableObject {
@Published var book: Book = .empty
@Published var errorMessage: String?
private var db = Firestore.firestore()
func fetchAndMap() {
fetchBook(documentId: "hitchhiker")
}
func fetchAndMapNonExisting() {
fetchBook(documentId: "does-not-exist")
}
func fetchAndTryMappingInvalidData() {
fetchBook(documentId: "invalid-data")
}
private func fetchBook(documentId: String) {
let docRef = db.collection("books").document(documentId)
docRef.getDocument(as: Book.self) { result in
switch result {
case .success(let book):
// A Book value was successfully initialized from the DocumentSnapshot.
self.book = book
self.errorMessage = nil
case .failure(let error):
// A Book value could not be initialized from the DocumentSnapshot.
switch error {
case DecodingError.typeMismatch(_, let context):
self.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.valueNotFound(_, let context):
self.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.keyNotFound(_, let context):
self.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.dataCorrupted(let key):
self.errorMessage = "\(error.localizedDescription): \(key)"
default:
self.errorMessage = "Error decoding document: \(error.localizedDescription)"
}
}
}
}
}
טיפול בשגיאות בעדכונים בזמן אמת
בקטע הקוד הקודם אפשר לראות איך לטפל בשגיאות כשמאחזרים מסמך יחיד. בנוסף לאחזור נתונים חד-פעמי, Cloud Firestore תומך גם באספקת עדכונים לאפליקציה בזמן שהם מתרחשים, באמצעות מה שנקרא מאזיני תמונת מצב: אנחנו יכולים לרשום מאזין תמונת מצב באוסף (או בשאילתה), ו-Cloud Firestore יפעיל את המאזין שלנו בכל פעם שיש עדכון.
קטע הקוד הבא מראה איך לרשום פונקציית event listener של תמונת מצב, למפות נתונים באמצעות Codable ולטפל בשגיאות שעשויות להתרחש. בנוסף, מוסבר איך להוסיף מסמך חדש לאוסף. כפי שניתן לראות, אין צורך לעדכן את המערך המקומי שמכיל את המסמכים הממופים בעצמנו, כי הקוד במאזין של התמונה המיידית מטפל בזה.
class MappingColorsViewModel: ObservableObject {
@Published var colorEntries = [ColorEntry]()
@Published var newColor = ColorEntry.empty
@Published var errorMessage: String?
private var db = Firestore.firestore()
private var listenerRegistration: ListenerRegistration?
public func unsubscribe() {
if listenerRegistration != nil {
listenerRegistration?.remove()
listenerRegistration = nil
}
}
func subscribe() {
if listenerRegistration == nil {
listenerRegistration = db.collection("colors")
.addSnapshotListener { [weak self] (querySnapshot, error) in
guard let documents = querySnapshot?.documents else {
self?.errorMessage = "No documents in 'colors' collection"
return
}
self?.colorEntries = documents.compactMap { queryDocumentSnapshot in
let result = Result { try queryDocumentSnapshot.data(as: ColorEntry.self) }
switch result {
case .success(let colorEntry):
if let colorEntry = colorEntry {
// A ColorEntry value was successfully initialized from the DocumentSnapshot.
self?.errorMessage = nil
return colorEntry
}
else {
// A nil value was successfully initialized from the DocumentSnapshot,
// or the DocumentSnapshot was nil.
self?.errorMessage = "Document doesn't exist."
return nil
}
case .failure(let error):
// A ColorEntry value could not be initialized from the DocumentSnapshot.
switch error {
case DecodingError.typeMismatch(_, let context):
self?.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.valueNotFound(_, let context):
self?.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.keyNotFound(_, let context):
self?.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.dataCorrupted(let key):
self?.errorMessage = "\(error.localizedDescription): \(key)"
default:
self?.errorMessage = "Error decoding document: \(error.localizedDescription)"
}
return nil
}
}
}
}
}
func addColorEntry() {
let collectionRef = db.collection("colors")
do {
let newDocReference = try collectionRef.addDocument(from: newColor)
print("ColorEntry stored with new document reference: \(newDocReference)")
}
catch {
print(error)
}
}
}
כל קטעי הקוד שמופיעים בפוסט הזה הם חלק מאפליקציה לדוגמה שאפשר להוריד ממאגר GitHub הזה.
קדימה, אפשר להשתמש ב-Codable!
Codable API של Swift מספק דרך עוצמתית וגמישה למפות נתונים מפורמטים מסודרים למודל הנתונים של האפליקציות שלכם וממנו. במדריך הזה ראיתם כמה קל להשתמש ב-Cloud Firestore באפליקציות שמשתמשות בו כמאגר נתונים.
התחלנו עם דוגמה בסיסית עם סוגי נתונים פשוטים, והגדלנו בהדרגה את המורכבות של מודל הנתונים, תוך הסתמכות על Codable וההטמעה של Firebase כדי לבצע את המיפוי בשבילנו.
לפרטים נוספים על Codable, מומלץ לעיין במקורות המידע הבאים:
- במאמר של ג'ון סאנדל מוסבר על היסודות של Codable.
- אם אתם מעדיפים ספרים, כדאי לעיין במדריך של Mattt ל-Swift Codable.
- ולבסוף, ל-Donny Wals יש סדרה שלמה על Codable.
עשינו כמיטב יכולתנו כדי ליצור מדריך מקיף למיפוי מסמכי Cloud Firestore, אבל הוא לא ממצה, ויכול להיות שאתם משתמשים באסטרטגיות אחרות למיפוי הסוגים. נשמח לקבל מכם משוב. אפשר ללחוץ על הכפתור שליחת משוב שבהמשך ולספר לנו באילו שיטות אתם משתמשים כדי למפות סוגים אחרים של נתוני Cloud Firestore או כדי לייצג נתונים ב-Swift.
אין סיבה לא להשתמש בתמיכה של Cloud Firestore ב-Codable.