
উচ্চ কর্মক্ষমতা এবং নির্ভরযোগ্যতার জন্য আপনার অ্যাপ্লিকেশনগুলি তৈরি করার বিষয়ে সুনির্দিষ্ট সিদ্ধান্ত নিতে এই নথিটি পড়ুন। এই নথিতে উন্নত Cloud Firestore বিষয়গুলি অন্তর্ভুক্ত রয়েছে। আপনি যদি Cloud Firestore দিয়ে শুরু করেন, তাহলে দ্রুত শুরু করার নির্দেশিকাটি দেখুন।
Cloud Firestore হল ফায়ারবেস এবং Google Cloud থেকে মোবাইল ডিভাইস, ওয়েব এবং সার্ভার ডেভেলপমেন্টের জন্য একটি নমনীয়, স্কেলেবল ডাটাবেস। Cloud Firestore দিয়ে শুরু করা এবং সমৃদ্ধ এবং শক্তিশালী অ্যাপ্লিকেশন লেখা খুব সহজ।
আপনার ডাটাবেসের আকার এবং ট্র্যাফিক বৃদ্ধির সাথে সাথে আপনার অ্যাপ্লিকেশনগুলি যাতে ভালোভাবে কাজ করে তা নিশ্চিত করার জন্য, Cloud Firestore ব্যাকএন্ডে রিড এবং রাইটসের মেকানিক্স বুঝতে সাহায্য করে। স্টোরেজ লেয়ারের সাথে আপনার রিড এবং রাইটসের মিথস্ক্রিয়া এবং কর্মক্ষমতাকে প্রভাবিত করতে পারে এমন অন্তর্নিহিত সীমাবদ্ধতাগুলিও আপনাকে বুঝতে হবে।
আপনার আবেদন তৈরির আগে সর্বোত্তম অনুশীলনের জন্য নিম্নলিখিত বিভাগগুলি দেখুন।
উচ্চ স্তরের উপাদানগুলি বুঝুন
নিম্নলিখিত চিত্রটি Cloud Firestore API অনুরোধে জড়িত উচ্চ স্তরের উপাদানগুলি দেখায়।
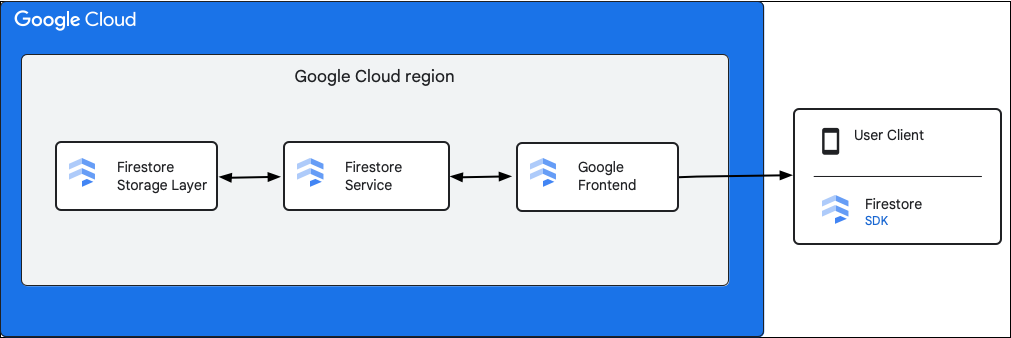
Cloud Firestore SDK এবং ক্লায়েন্ট লাইব্রেরি
Cloud Firestore বিভিন্ন প্ল্যাটফর্মের জন্য SDK এবং ক্লায়েন্ট লাইব্রেরি সমর্থন করে। যদিও একটি অ্যাপ Cloud Firestore API-তে সরাসরি HTTP এবং RPC কল করতে পারে, ক্লায়েন্ট লাইব্রেরিগুলি API ব্যবহার সহজ করার জন্য এবং সর্বোত্তম অনুশীলনগুলি বাস্তবায়নের জন্য একটি বিমূর্ত স্তর প্রদান করে। তারা অফলাইন অ্যাক্সেস, ক্যাশে ইত্যাদির মতো অতিরিক্ত বৈশিষ্ট্যও প্রদান করতে পারে।
গুগল ফ্রন্ট এন্ড (GFE)
এটি একটি অবকাঠামো পরিষেবা যা সমস্ত Google ক্লাউড পরিষেবার জন্য সাধারণ। GFE আগত অনুরোধগুলি গ্রহণ করে এবং সেগুলি প্রাসঙ্গিক Google পরিষেবাতে (এই প্রসঙ্গে Cloud Firestore পরিষেবা) ফরোয়ার্ড করে। এটি পরিষেবা অস্বীকার আক্রমণের বিরুদ্ধে সুরক্ষা সহ অন্যান্য গুরুত্বপূর্ণ কার্যকারিতাও প্রদান করে।
Cloud Firestore পরিষেবা
Cloud Firestore পরিষেবা API অনুরোধের উপর পরীক্ষা করে, যার মধ্যে রয়েছে প্রমাণীকরণ, অনুমোদন, কোটা পরীক্ষা এবং সুরক্ষা নিয়ম, এবং লেনদেন পরিচালনা করে। এই Cloud Firestore পরিষেবাটিতে একটি স্টোরেজ ক্লায়েন্ট রয়েছে যা ডেটা পড়ার এবং লেখার জন্য স্টোরেজ স্তরের সাথে ইন্টারঅ্যাক্ট করে।
Cloud Firestore স্টোরেজ স্তর
Cloud Firestore স্টোরেজ স্তরটি ডেটা এবং মেটাডেটা এবং Cloud Firestore দ্বারা সরবরাহিত সংশ্লিষ্ট ডাটাবেস বৈশিষ্ট্য উভয়ই সংরক্ষণের জন্য দায়ী। নিম্নলিখিত বিভাগগুলি Cloud Firestore স্টোরেজ স্তরে ডেটা কীভাবে সংগঠিত হয় এবং সিস্টেম কীভাবে স্কেল করে তা বর্ণনা করে। ডেটা কীভাবে সংগঠিত হয় তা শেখা আপনাকে একটি স্কেলেবল ডেটা মডেল ডিজাইন করতে এবং Cloud Firestore সেরা অনুশীলনগুলি আরও ভালভাবে বুঝতে সহায়তা করতে পারে।
মূল পরিসর এবং বিভাজন
Cloud Firestore হল একটি NoSQL, ডকুমেন্ট-ভিত্তিক ডাটাবেস। আপনি ডকুমেন্টে ডেটা সংরক্ষণ করেন, যা সংগ্রহের শ্রেণিবিন্যাসে সংগঠিত হয়। সংগ্রহের শ্রেণিবিন্যাস এবং ডকুমেন্ট আইডি প্রতিটি ডকুমেন্টের জন্য একটি একক কীতে অনুবাদ করা হয়। ডকুমেন্টগুলি যুক্তিসঙ্গতভাবে সংরক্ষণ করা হয় এবং এই একক কী দ্বারা অভিধানিকভাবে সাজানো হয়। আমরা কী রেঞ্জ শব্দটি ব্যবহার করি লেক্সিকোগ্রাফিকভাবে সংলগ্ন কীগুলির পরিসর বোঝাতে।
একটি সাধারণ Cloud Firestore ডাটাবেস একটি একক ফিজিক্যাল মেশিনে ফিট করার জন্য খুব বড়। এমন পরিস্থিতিও রয়েছে যেখানে ডেটার উপর কাজের চাপ একটি মেশিনের পক্ষে খুব বেশি। বড় কাজের চাপ পরিচালনা করার জন্য, Cloud Firestore ডেটাকে পৃথক টুকরোতে ভাগ করে দেয় যা একাধিক মেশিন বা স্টোরেজ সার্ভারে সংরক্ষণ করা এবং পরিবেশন করা যেতে পারে। এই পার্টিশনগুলি স্প্লিট নামক কী রেঞ্জের ব্লকে ডাটাবেস টেবিলে তৈরি করা হয়।
সিঙ্ক্রোনাস রেপ্লিকেশন
এটা মনে রাখা গুরুত্বপূর্ণ যে ডাটাবেসটি সর্বদা স্বয়ংক্রিয়ভাবে এবং সিঙ্ক্রোনাসভাবে প্রতিলিপি করা হচ্ছে। কোনও জোন অ্যাক্সেসযোগ্য না হলেও ডেটা স্প্লিটগুলির বিভিন্ন জোনে প্রতিলিপি থাকে যাতে সেগুলি উপলব্ধ থাকে। স্প্লিটের বিভিন্ন কপির ধারাবাহিক প্রতিলিপি প্যাক্সোস অ্যালগরিদম দ্বারা ঐক্যমত্যের জন্য পরিচালিত হয়। প্রতিটি স্প্লিটের একটি প্রতিলিপি প্যাক্সোস লিডার হিসাবে কাজ করার জন্য নির্বাচিত হয়, যা সেই স্প্লিটে লেখা পরিচালনা করার জন্য দায়ী। সিঙ্ক্রোনাস প্রতিলিপি আপনাকে সর্বদা Cloud Firestore থেকে ডেটার সর্বশেষ সংস্করণ পড়তে সক্ষম হওয়ার ক্ষমতা দেয়।
এর সামগ্রিক ফলাফল হল একটি স্কেলেবল এবং অত্যন্ত সহজলভ্য সিস্টেম যা পড়া এবং লেখা উভয়ের জন্যই কম বিলম্ব প্রদান করে, ভারী কাজের চাপ নির্বিশেষে এবং খুব বড় আকারে।
ডেটা লেআউট
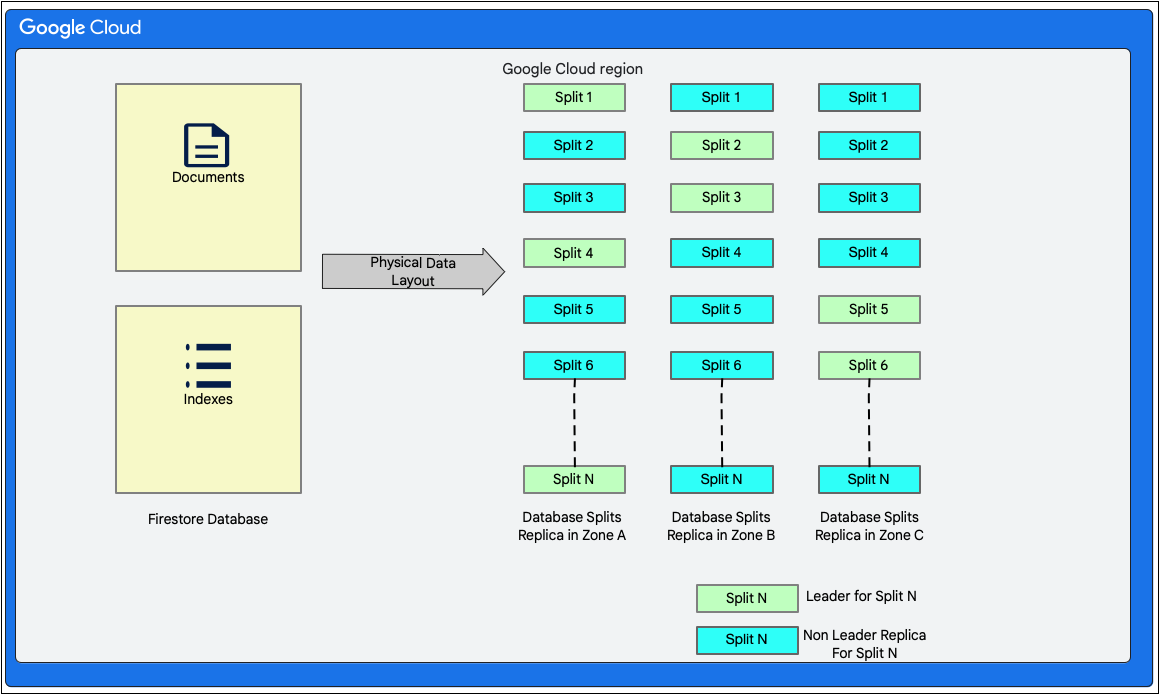
Cloud Firestore একটি স্কিমালেস ডকুমেন্ট ডাটাবেস। তবে, অভ্যন্তরীণভাবে এটি তার স্টোরেজ লেয়ারে দুটি রিলেশনাল ডাটাবেস-স্টাইল টেবিলে ডেটা মূলত নিম্নরূপে রাখে:
- ডকুমেন্টস টেবিল: এই টেবিলে ডকুমেন্টস সংরক্ষণ করা হয়।
- সূচী সারণী: সূচকের মান অনুসারে দক্ষতার সাথে ফলাফল পাওয়া এবং সাজানো সম্ভব করে এমন সূচী এন্ট্রিগুলি এই সারণীতে সংরক্ষণ করা হয়।
নিচের চিত্রটি দেখায় যে Cloud Firestore ডাটাবেসের টেবিলগুলি স্প্লিটগুলির সাথে কেমন দেখাবে। স্প্লিটগুলি তিনটি ভিন্ন জোনে প্রতিলিপি করা হয়েছে এবং প্রতিটি স্প্লিটের জন্য একটি নির্ধারিত প্যাক্সোস লিডার রয়েছে।
একক অঞ্চল বনাম বহু-অঞ্চল
যখন আপনি একটি ডাটাবেস তৈরি করেন, তখন আপনাকে অবশ্যই একটি অঞ্চল বা বহু-অঞ্চল নির্বাচন করতে হবে।
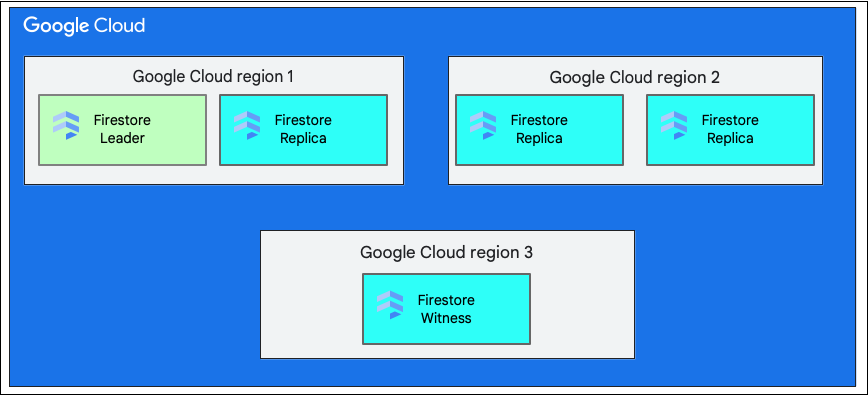
একটি একক আঞ্চলিক অবস্থান হল একটি নির্দিষ্ট ভৌগোলিক অবস্থান, যেমন us-west1 । Cloud Firestore ডাটাবেসের ডেটার বিভাজনের প্রতিলিপি নির্বাচিত অঞ্চলের মধ্যে বিভিন্ন অঞ্চলে থাকে, যেমনটি আগে ব্যাখ্যা করা হয়েছে।
একটি বহু-অঞ্চল অবস্থানে এমন কিছু অঞ্চল থাকে যেখানে ডাটাবেসের প্রতিলিপি সংরক্ষণ করা হয়। Cloud Firestore একটি বহু-অঞ্চল স্থাপনায়, দুটি অঞ্চলে ডাটাবেসের সম্পূর্ণ ডেটার সম্পূর্ণ প্রতিলিপি থাকে। তৃতীয় অঞ্চলে একটি সাক্ষী প্রতিলিপি থাকে যা সম্পূর্ণ ডেটার সেট বজায় রাখে না, তবে প্রতিলিপিতে অংশগ্রহণ করে। একাধিক অঞ্চলের মধ্যে ডেটা প্রতিলিপি করার মাধ্যমে, একটি সম্পূর্ণ অঞ্চল হারিয়ে গেলেও ডেটা লেখা এবং পড়ার জন্য উপলব্ধ থাকে।
কোনও অঞ্চলের অবস্থান সম্পর্কে আরও তথ্যের জন্য, Cloud Firestore অবস্থানগুলি দেখুন।
Cloud Firestore একজন লেখার জীবন সম্পর্কে জানুন
একটি Cloud Firestore ক্লায়েন্ট একটি একক ডকুমেন্ট তৈরি, আপডেট বা মুছে ফেলার মাধ্যমে ডেটা লিখতে পারে। একটি একক ডকুমেন্টে লেখার জন্য স্টোরেজ স্তরে ডকুমেন্ট এবং এর সাথে সম্পর্কিত সূচক এন্ট্রি উভয়ই পরমাণুভাবে আপডেট করতে হয়। Cloud Firestore একাধিক পঠন এবং/অথবা এক বা একাধিক ডকুমেন্টে লেখার সমন্বয়ে পারমাণবিক ক্রিয়াকলাপগুলিকেও সমর্থন করে।
সকল ধরণের লেখার জন্য, Cloud Firestore রিলেশনাল ডাটাবেসের ACID বৈশিষ্ট্য (পারমাণবিকতা, ধারাবাহিকতা, বিচ্ছিন্নতা এবং স্থায়িত্ব) প্রদান করে। Cloud Firestore সিরিয়ালাইজেবিলিটিও প্রদান করে, যার অর্থ হল সমস্ত লেনদেন এমনভাবে প্রদর্শিত হয় যেন একটি সিরিয়াল ক্রমে সম্পাদিত হয়।
একটি লেখার লেনদেনের উচ্চ-স্তরের ধাপ
যখন Cloud Firestore ক্লায়েন্ট পূর্বে উল্লিখিত যেকোনো পদ্ধতি ব্যবহার করে একটি লেখা ইস্যু করে বা একটি লেনদেন করে, তখন অভ্যন্তরীণভাবে এটি স্টোরেজ স্তরে একটি ডাটাবেস রিড-রাইট লেনদেন হিসাবে কার্যকর করা হয়। লেনদেনটি Cloud Firestore পূর্বে উল্লিখিত ACID বৈশিষ্ট্যগুলি সরবরাহ করতে সক্ষম করে।
লেনদেনের প্রথম ধাপ হিসেবে, Cloud Firestore বিদ্যমান ডকুমেন্টটি পড়ে এবং ডকুমেন্টস টেবিলের ডেটাতে কী কী মিউটেশন করতে হবে তা নির্ধারণ করে।
এর মধ্যে নিম্নলিখিতভাবে সূচক সারণীতে প্রয়োজনীয় আপডেট করাও অন্তর্ভুক্ত রয়েছে:
- ডকুমেন্টে যে ক্ষেত্রগুলি যোগ করা হচ্ছে সেগুলির জন্য সূচী সারণীতে সংশ্লিষ্ট সন্নিবেশ প্রয়োজন।
- ডকুমেন্ট থেকে যে ক্ষেত্রগুলি সরানো হচ্ছে সেগুলির সূচী সারণীতে সংশ্লিষ্ট মুছে ফেলা প্রয়োজন।
- ডকুমেন্টে যেসব ক্ষেত্র পরিবর্তন করা হচ্ছে, সেগুলির জন্য ইনডেক্স টেবিলে মুছে ফেলা (পুরানো মানের জন্য) এবং সন্নিবেশ করা (নতুন মানের জন্য) উভয়ই প্রয়োজন।
পূর্বে উল্লিখিত মিউটেশনগুলি গণনা করার জন্য, Cloud Firestore প্রকল্পের জন্য ইনডেক্সিং কনফিগারেশন পড়ে। ইনডেক্সিং কনফিগারেশন একটি প্রকল্পের জন্য ইনডেক্স সম্পর্কে তথ্য সংরক্ষণ করে। Cloud Firestore দুই ধরণের ইনডেক্স ব্যবহার করে: একক-ক্ষেত্র এবং কম্পোজিট। Cloud Firestore তৈরি ইনডেক্সগুলির বিস্তারিত বোঝার জন্য, Cloud Firestore ইনডেক্স প্রকারগুলি দেখুন।
একবার মিউটেশনগুলি গণনা করা হয়ে গেলে, Cloud Firestore সেগুলি একটি লেনদেনের মধ্যে সংগ্রহ করে এবং তারপর এটি কমিট করে।
স্টোরেজ লেয়ারে লেখার লেনদেন বুঝুন
যেমনটি আগে আলোচনা করা হয়েছে, Cloud Firestore একটি লেখার ক্ষেত্রে স্টোরেজ লেয়ারে একটি পঠন-লেখার লেনদেন জড়িত। ডেটা লেআউটের উপর নির্ভর করে, একটি লেখার ক্ষেত্রে এক বা একাধিক বিভাজন থাকতে পারে যেমনটি ডেটা লেআউটে দেখা যায়।
নিচের চিত্রটিতে, Cloud Firestore ডাটাবেসে আটটি স্প্লিট (১-৮ চিহ্নিত) রয়েছে যা একটি একক জোনে তিনটি ভিন্ন স্টোরেজ সার্ভারে হোস্ট করা হয়েছে এবং প্রতিটি স্প্লিট ৩ (বা তার বেশি) ভিন্ন জোনে প্রতিলিপি করা হয়েছে। প্রতিটি স্প্লিটে একটি প্যাক্সোস লিডার রয়েছে, যা বিভিন্ন স্প্লিটের জন্য ভিন্ন জোনে থাকতে পারে।
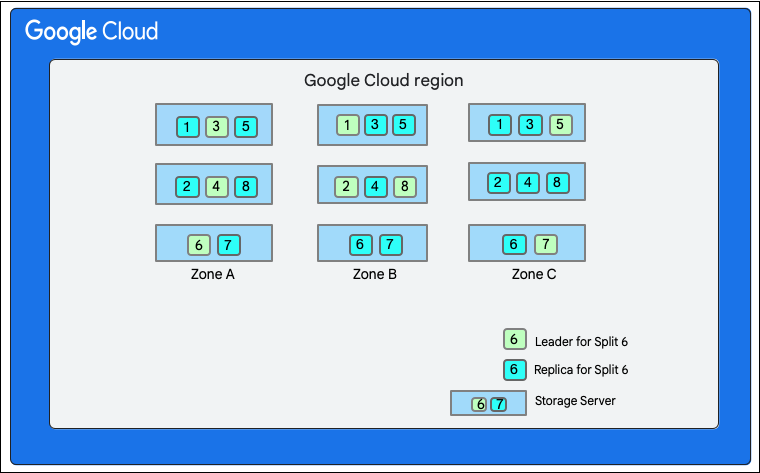 ক্লাউড ফায়ারস্টোর ডাটাবেস বিভক্ত">
ক্লাউড ফায়ারস্টোর ডাটাবেস বিভক্ত">
একটি Cloud Firestore ডাটাবেস বিবেচনা করুন যেখানে Restaurants সংগ্রহ নিম্নরূপ রয়েছে:
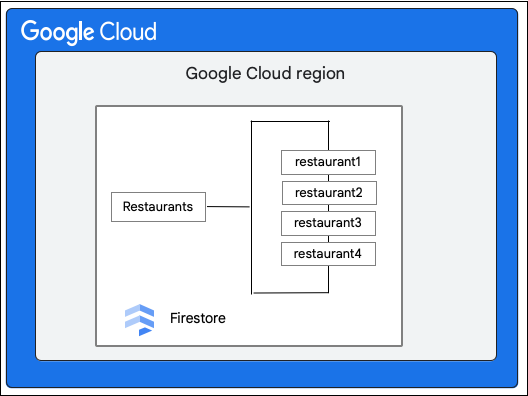
Cloud Firestore ক্লায়েন্ট Restaurant সংগ্রহের একটি নথিতে নিম্নলিখিত পরিবর্তনের অনুরোধ করে priceCategory ক্ষেত্রের মান আপডেট করে।
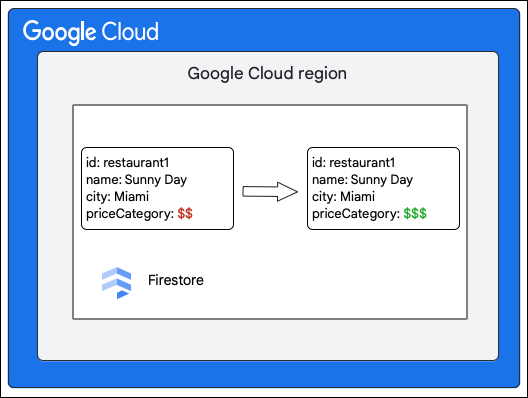
লেখার অংশ হিসেবে কী ঘটে তা নিম্নলিখিত উচ্চ-স্তরের পদক্ষেপগুলি বর্ণনা করে:
- একটি পঠন-লেখা লেনদেন তৈরি করুন।
- স্টোরেজ লেয়ার থেকে ডকুমেন্টস টেবিল থেকে
Restaurantsসংগ্রহেরrestaurant1ডকুমেন্টটি পড়ুন। - ইনডেক্সেস টেবিল থেকে ডকুমেন্টের ইনডেক্সগুলি পড়ুন।
- ডেটাতে করা মিউটেশনগুলি গণনা করুন। এই ক্ষেত্রে, পাঁচটি মিউটেশন রয়েছে:
- M1:
priceCategoryক্ষেত্রের মানের পরিবর্তন প্রতিফলিত করতে ডকুমেন্টস টেবিলেrestaurant1এর জন্য সারিটি আপডেট করুন। - M2 এবং M3: ক্রমহ্রাসমান এবং ঊর্ধ্বমুখী সূচকের জন্য সূচক সারণীতে
priceCategoryপুরানো মানের সারিগুলি মুছুন। - M4 এবং M5: ক্রমহ্রাসমান এবং ঊর্ধ্বমুখী সূচকের জন্য সূচক সারণীতে
priceCategoryনতুন মানের জন্য সারিগুলি সন্নিবেশ করান।
- M1:
- এই মিউটেশনগুলি সম্পাদন করুন।
Cloud Firestore সার্ভিসের স্টোরেজ ক্লায়েন্ট পরিবর্তন করা সারিগুলির কীগুলির মালিকানাধীন স্প্লিটগুলি সন্ধান করে। আসুন এমন একটি কেস বিবেচনা করি যেখানে স্প্লিট 3 M1 পরিবেশন করে এবং স্প্লিট 6 M2-M5 পরিবেশন করে। একটি বিতরণ লেনদেন রয়েছে, যার মধ্যে এই সমস্ত স্প্লিট অংশগ্রহণকারী হিসাবে জড়িত। অংশগ্রহণকারী স্প্লিটগুলিতে অন্য কোনও স্প্লিটও অন্তর্ভুক্ত থাকতে পারে যেখান থেকে ডেটা আগে পঠন-লেখার লেনদেনের অংশ হিসাবে পড়া হয়েছিল।
নিম্নলিখিত ধাপগুলি কমিটের অংশ হিসাবে কী ঘটে তা বর্ণনা করে:
- স্টোরেজ ক্লায়েন্ট একটি কমিট ইস্যু করে। কমিটটিতে M1-M5 মিউটেশন থাকে।
- এই লেনদেনে অংশগ্রহণকারীরা হলেন স্প্লিট ৩ এবং ৬। অংশগ্রহণকারীদের মধ্যে একজনকে সমন্বয়কারী হিসেবে নির্বাচিত করা হয়, যেমন স্প্লিট ৩। সমন্বয়কারীর কাজ হল নিশ্চিত করা যে লেনদেনটি সমস্ত অংশগ্রহণকারীদের মধ্যে পারমাণবিকভাবে সম্পন্ন হয় অথবা বাতিল হয়।
- এই বিভাজনের নেতার প্রতিলিপিগুলি অংশগ্রহণকারী এবং সমন্বয়কারীদের দ্বারা সম্পাদিত কাজের জন্য দায়ী।
- প্রতিটি অংশগ্রহণকারী এবং সমন্বয়কারী তাদের নিজ নিজ প্রতিলিপি সহ একটি প্যাক্সোস অ্যালগরিদম চালান।
- লিডার রেপ্লিকাগুলির সাথে একটি প্যাক্সোস অ্যালগরিদম চালান। বেশিরভাগ রেপ্লিকা যদি লিডারকে
ok to commitবলে সাড়া দেয় তাহলে কোরাম অর্জন করা হয়। - প্রতিটি অংশগ্রহণকারী প্রস্তুত হওয়ার পর সমন্বয়কারীকে অবহিত করে (দ্বি-পর্যায়ের কমিটের প্রথম পর্যায়)। যদি কোনও অংশগ্রহণকারী লেনদেন করতে না পারে, তাহলে পুরো লেনদেন
aborts।
- লিডার রেপ্লিকাগুলির সাথে একটি প্যাক্সোস অ্যালগরিদম চালান। বেশিরভাগ রেপ্লিকা যদি লিডারকে
- একবার সমন্বয়কারী জানতে পারেন যে সমস্ত অংশগ্রহণকারী, এমনকি তিনিও, প্রস্তুত, তিনি সমস্ত অংশগ্রহণকারীদের কাছে
acceptলেনদেনের ফলাফল জানান (দুই-পর্যায়ের প্রতিশ্রুতির দ্বিতীয় পর্যায়)। এই পর্যায়ে, প্রতিটি অংশগ্রহণকারী স্থিতিশীল সঞ্চয়স্থানের জন্য প্রতিশ্রুতিবদ্ধ সিদ্ধান্ত রেকর্ড করে এবং লেনদেনটি প্রতিশ্রুতিবদ্ধ হয়। - সমন্বয়কারী Cloud Firestore স্টোরেজ ক্লায়েন্টকে লেনদেন সম্পন্ন হয়েছে বলে সাড়া দেন। সমান্তরালভাবে, সমন্বয়কারী এবং সমস্ত অংশগ্রহণকারী ডেটাতে মিউটেশন প্রয়োগ করেন।
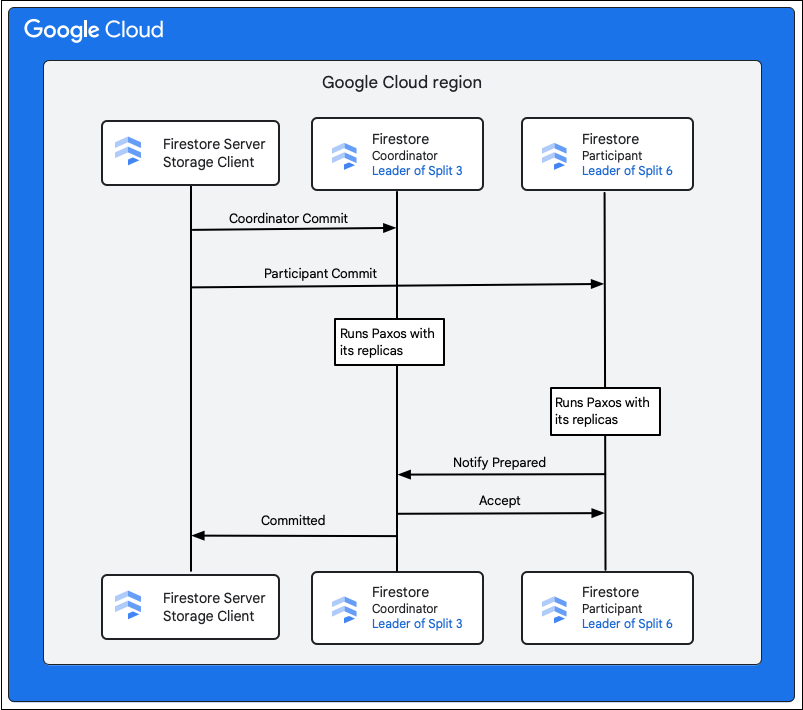
যখন Cloud Firestore ডাটাবেস ছোট হয়, তখন এমন হতে পারে যে একটি একক স্প্লিট M1-M5 মিউটেশনের সমস্ত কীগুলির মালিক। এই ক্ষেত্রে, লেনদেনে শুধুমাত্র একজন অংশগ্রহণকারী থাকে এবং পূর্বে উল্লিখিত দুই-পর্যায়ের কমিটের প্রয়োজন হয় না, ফলে লেখা দ্রুত হয়।
বহু-অঞ্চলে লেখেন
বহু-অঞ্চল স্থাপনার ক্ষেত্রে, বিভিন্ন অঞ্চলে প্রতিলিপির বিস্তার প্রাপ্যতা বৃদ্ধি করে, তবে এর সাথে কর্মক্ষমতা খরচও জড়িত। বিভিন্ন অঞ্চলে প্রতিলিপিগুলির মধ্যে যোগাযোগের জন্য রাউন্ড ট্রিপ সময় বেশি লাগে। অতএব, Cloud Firestore অপারেশনের জন্য বেসলাইন ল্যাটেন্সি একক অঞ্চল স্থাপনের তুলনায় কিছুটা বেশি।
আমরা রেপ্লিকাগুলিকে এমনভাবে কনফিগার করি যাতে স্প্লিটের জন্য লিডারশিপ সর্বদা প্রাথমিক অঞ্চলে থাকে। প্রাথমিক অঞ্চল হল সেই অঞ্চল যেখান থেকে Cloud Firestore সার্ভারে ট্র্যাফিক আসে। লিডারশিপের এই সিদ্ধান্ত Cloud Firestore স্টোরেজ ক্লায়েন্ট এবং রেপ্লিকা লিডার (অথবা মাল্টি-স্প্লিট লেনদেনের জন্য সমন্বয়কারী) এর মধ্যে যোগাযোগের ক্ষেত্রে রাউন্ড-ট্রিপ বিলম্ব হ্রাস করে।
Cloud Firestore প্রতিটি লেখার সাথে Cloud Firestore রিয়েল-টাইম ইঞ্জিনের কিছু মিথস্ক্রিয়া জড়িত। রিয়েল-টাইম কোয়েরি সম্পর্কে আরও তথ্যের জন্য, স্কেলে রিয়েল-টাইম কোয়েরিগুলি বুঝতে দেখুন।
Cloud Firestore একজন পাঠকের জীবন বুঝুন
এই বিভাগটি Cloud Firestore স্বতন্ত্র, নন-রিয়েলটাইম রিডগুলির উপর গভীরভাবে আলোচনা করে। অভ্যন্তরীণভাবে, Cloud Firestore সার্ভার দুটি প্রধান পর্যায়ে এই প্রশ্নের বেশিরভাগই পরিচালনা করে:
- ইনডেক্স টেবিলের উপর একটি একক পরিসর স্ক্যান
- পূর্ববর্তী স্ক্যানের ফলাফলের উপর ভিত্তি করে ডকুমেন্টস টেবিলে পয়েন্ট লুকআপ
স্টোরেজ লেয়ার থেকে ডেটা রিড অভ্যন্তরীণভাবে একটি ডাটাবেস লেনদেন ব্যবহার করে করা হয় যাতে ধারাবাহিকভাবে রিড নিশ্চিত করা যায়। তবে, লেখার জন্য ব্যবহৃত লেনদেনের বিপরীতে, এই লেনদেনগুলিতে লক লাগে না। পরিবর্তে, তারা একটি টাইমস্ট্যাম্প বেছে নিয়ে কাজ করে, তারপর সেই টাইমস্ট্যাম্পে সমস্ত রিড কার্যকর করে। যেহেতু তারা লক অর্জন করে না, তাই তারা সমকালীন রিড-রাইট লেনদেন ব্লক করে না। এই লেনদেনটি কার্যকর করার জন্য, Cloud Firestore স্টোরেজ ক্লায়েন্ট একটি টাইমস্ট্যাম্প বাউন্ড নির্দিষ্ট করে, যা স্টোরেজ লেয়ারকে বলে যে কীভাবে রিড টাইমস্ট্যাম্প বেছে নিতে হয়। Cloud Firestore স্টোরেজ ক্লায়েন্ট দ্বারা নির্বাচিত টাইমস্ট্যাম্প বাউন্ডের ধরণ রিড অনুরোধের জন্য রিড বিকল্পগুলি দ্বারা নির্ধারিত হয়।
স্টোরেজ লেয়ারে একটি পঠিত লেনদেন বুঝুন
এই বিভাগটি Cloud Firestore স্টোরেজ লেয়ারে রিডের ধরণ এবং কীভাবে সেগুলি প্রক্রিয়াজাত করা হয় তা বর্ণনা করে।
জোরে জোরে পড়া
ডিফল্টরূপে, Cloud Firestore রিডগুলি দৃঢ়ভাবে সামঞ্জস্যপূর্ণ । এই শক্তিশালী সামঞ্জস্যের অর্থ হল একটি Cloud Firestore রিড ডেটার সর্বশেষ সংস্করণ ফেরত দেয় যা পঠন শুরু হওয়ার আগে পর্যন্ত করা সমস্ত লেখা প্রতিফলিত করে।
একক স্প্লিট পঠন
Cloud Firestore স্টোরেজ ক্লায়েন্টটি পঠিত সারিগুলির কীগুলির মালিকানাধীন স্প্লিটগুলি সন্ধান করে। ধরে নেওয়া যাক যে এটিকে পূর্ববর্তী বিভাগ থেকে স্প্লিট 3 থেকে একটি পঠন করতে হবে। ক্লায়েন্ট রাউন্ড ট্রিপ লেটেন্সি কমাতে নিকটতম প্রতিরূপে পঠনের অনুরোধ পাঠায়।
এই মুহুর্তে, নির্বাচিত প্রতিরূপের উপর নির্ভর করে নিম্নলিখিত ঘটনাগুলি ঘটতে পারে:
- পড়ার অনুরোধটি একটি লিডার রেপ্লিকা (জোন এ) তে যায়।
- যেহেতু নেতা সর্বদা হালনাগাদ থাকেন, তাই পাঠ সরাসরি এগিয়ে যেতে পারে।
- পড়ার অনুরোধটি একটি নন-লিডার রেপ্লিকাতে যায় (যেমন, জোন বি)
- স্প্লিট ৩ তার অভ্যন্তরীণ অবস্থা দেখে জানতে পারে যে পঠনযোগ্য পরিবেশনের জন্য এর কাছে যথেষ্ট তথ্য রয়েছে এবং স্প্লিট তা করে।
- স্প্লিট ৩ নিশ্চিত নয় যে এটি সর্বশেষ তথ্য দেখেছে কিনা। এটি লিডারকে একটি বার্তা পাঠায় যাতে রিড পরিবেশনের জন্য প্রয়োগ করা সর্বশেষ লেনদেনের টাইমস্ট্যাম্প জানতে চাওয়া হয়। একবার সেই লেনদেন প্রয়োগ করা হয়ে গেলে, রিড এগিয়ে যেতে পারে।
এরপর Cloud Firestore তার ক্লায়েন্টকে প্রতিক্রিয়া ফেরত দেয়।
মাল্টি-স্প্লিট রিড
যে পরিস্থিতিতে একাধিক স্প্লিট থেকে রিডিং করতে হয়, সেখানে সমস্ত স্প্লিট জুড়ে একই প্রক্রিয়া ঘটে। সমস্ত স্প্লিট থেকে ডেটা ফেরত পাঠানোর পরে, Cloud Firestore স্টোরেজ ক্লায়েন্ট ফলাফলগুলি একত্রিত করে। Cloud Firestore তারপর এই ডেটা দিয়ে তার ক্লায়েন্টকে প্রতিক্রিয়া জানায়।
স্টেল রিডস
Cloud Firestore ডিফল্ট মোড হল স্ট্রং রিড। তবে, লিডারের সাথে যোগাযোগের প্রয়োজন হতে পারে বলে এর জন্য সম্ভাব্য উচ্চতর ল্যাটেন্সির মূল্য দিতে হয়। প্রায়শই আপনার Cloud Firestore অ্যাপ্লিকেশনটিকে ডেটার সর্বশেষ সংস্করণটি পড়ার প্রয়োজন হয় না এবং কার্যকারিতা কয়েক সেকেন্ডের পুরানো ডেটার সাথে ভালভাবে কাজ করে।
এই ক্ষেত্রে, ক্লায়েন্ট read_time read বিকল্পগুলি ব্যবহার করে stale reads গ্রহণ করতে পারে। এই ক্ষেত্রে, read_time এ ডেটা যেমন ছিল তেমনভাবে reads সম্পন্ন করা হয়, এবং নিকটতম প্রতিলিপিটি ইতিমধ্যেই নির্দিষ্ট read_time এ ডেটা আছে কিনা তা যাচাই করে নেওয়ার সম্ভাবনা বেশি। লক্ষণীয়ভাবে আরও ভালো পারফরম্যান্সের জন্য, 15 সেকেন্ড একটি যুক্তিসঙ্গত staleness মান। এমনকি stale reads এর জন্যও, প্রাপ্ত সারিগুলি একে অপরের সাথে সামঞ্জস্যপূর্ণ।
হটস্পট এড়িয়ে চলুন
Cloud Firestore স্প্লিটগুলি স্বয়ংক্রিয়ভাবে ছোট ছোট টুকরোতে ভেঙে যায় যাতে প্রয়োজনের সময় বা কী স্পেস প্রসারিত হলে ট্র্যাফিক পরিবেশনের কাজ আরও স্টোরেজ সার্ভারে বিতরণ করা যায়। অতিরিক্ত ট্র্যাফিক পরিচালনা করার জন্য তৈরি স্প্লিটগুলি ট্র্যাফিক চলে গেলেও প্রায় ~24 ঘন্টা ধরে রাখা হয়। তাই যদি বারবার ট্র্যাফিক স্পাইক হয়, তাহলে স্প্লিটগুলি বজায় রাখা হয় এবং যখনই প্রয়োজন হয় তখন আরও স্প্লিট চালু করা হয়। এই প্রক্রিয়াগুলি Cloud Firestore ডাটাবেসগুলিকে ক্রমবর্ধমান ট্র্যাফিক লোড বা ডাটাবেসের আকারের অধীনে স্বয়ংক্রিয়ভাবে স্কেল করতে সহায়তা করে। তবে, নীচে ব্যাখ্যা করা কিছু সীমাবদ্ধতা সম্পর্কে সচেতন থাকতে হবে।
স্টোরেজ এবং লোড বিভক্ত করতে সময় লাগে, এবং ট্র্যাফিক খুব দ্রুত বাড়ানোর ফলে উচ্চ বিলম্ব বা সময়সীমা অতিক্রমকারী ত্রুটি হতে পারে, যা সাধারণত হটস্পট হিসাবে পরিচিত, যখন পরিষেবাটি সামঞ্জস্য করে। সর্বোত্তম অনুশীলন হল মূল পরিসরে ক্রিয়াকলাপ বিতরণ করা, একই সাথে প্রতি সেকেন্ডে 500 ক্রিয়াকলাপ সহ একটি ডাটাবেসের সংগ্রহে ট্র্যাফিক বৃদ্ধি করা। এই ধীরে ধীরে র্যাম্প আপের পরে, প্রতি পাঁচ মিনিটে ট্র্যাফিক 50% পর্যন্ত বৃদ্ধি করুন। এই প্রক্রিয়াটিকে 500/50/5 নিয়ম বলা হয় এবং আপনার কাজের চাপ মেটাতে ডাটাবেসকে সর্বোত্তমভাবে স্কেল করার জন্য অবস্থান করে।
যদিও ক্রমবর্ধমান লোডের সাথে স্প্লিটগুলি স্বয়ংক্রিয়ভাবে তৈরি হয়, Cloud Firestore কেবল তখনই একটি মূল পরিসর বিভক্ত করতে পারে যতক্ষণ না এটি একটি নির্দিষ্ট সেট প্রতিলিপিকৃত স্টোরেজ সার্ভার ব্যবহার করে একটি একক নথি পরিবেশন করে। ফলস্বরূপ, একটি একক নথিতে উচ্চ এবং টেকসই ভলিউম সমসাময়িক ক্রিয়াকলাপের ফলে সেই নথিতে একটি হটস্পট দেখা দিতে পারে। যদি আপনি একটি একক নথিতে দীর্ঘস্থায়ী উচ্চ বিলম্বের সম্মুখীন হন, তাহলে আপনার ডেটা মডেল পরিবর্তন করে একাধিক নথিতে ডেটা বিভক্ত বা প্রতিলিপি করার কথা বিবেচনা করা উচিত।
কন্টেনশন ত্রুটি ঘটে যখন একাধিক অপারেশন একই সাথে একই ডকুমেন্ট পড়ার এবং/অথবা লেখার চেষ্টা করে।
হটস্পটের আরেকটি বিশেষ ঘটনা ঘটে যখন Cloud Firestore ডকুমেন্ট আইডি হিসেবে একটি ক্রমান্বয়ে ক্রমবর্ধমান/হ্রাসমান কী ব্যবহার করা হয় এবং প্রতি সেকেন্ডে যথেষ্ট পরিমাণে অপারেশন হয়। আরও স্প্লিট তৈরি করা এখানে সাহায্য করে না কারণ ট্র্যাফিকের ঢেউ কেবল নতুন তৈরি স্প্লিটে চলে যায়। যেহেতু Cloud Firestore স্বয়ংক্রিয়ভাবে ডকুমেন্টের সমস্ত ক্ষেত্রকে ডিফল্টরূপে সূচীবদ্ধ করে, তাই এই ধরনের চলমান হটস্পটগুলি একটি ডকুমেন্ট ফিল্ডের জন্য সূচক স্থানেও তৈরি করা যেতে পারে যেখানে টাইমস্ট্যাম্পের মতো ক্রমান্বয়ে ক্রমবর্ধমান/হ্রাসমান মান থাকে।
মনে রাখবেন যে উপরে বর্ণিত পদ্ধতিগুলি অনুসরণ করে, Cloud Firestore আপনাকে কোনও কনফিগারেশন সামঞ্জস্য না করেই ইচ্ছামত বড় কাজের চাপ পরিবেশন করতে পারে।
সমস্যা সমাধান
Cloud Firestore কী ভিজ্যুয়ালাইজারকে একটি ডায়াগনস্টিক টুল হিসেবে সরবরাহ করে যা ব্যবহারের ধরণ বিশ্লেষণ এবং হটস্পট সমস্যা সমাধানের জন্য ডিজাইন করা হয়েছে।
এরপর কি?
- আরও সেরা অনুশীলন সম্পর্কে পড়ুন
- স্কেলে রিয়েল-টাইম কোয়েরি সম্পর্কে জানুন