
اطّلِع على هذا المستند لاتّخاذ قرارات مدروسة بشأن تصميم تطبيقاتك لتحقيق أداء عالٍ وموثوقية. يتضمّن هذا المستند مواضيع متقدّمة حول Cloud Firestore. إذا كنت في مرحلة بدء استخدام Cloud Firestore، يُرجى الاطّلاع على دليل البدء السريع بدلاً من ذلك.
Cloud Firestore هي قاعدة بيانات مرنة وقابلة للتوسّع لتطوير تطبيقات الأجهزة الجوّالة والويب والخوادم من Firebase وGoogle Cloud. من السهل جدًا البدء باستخدام Cloud Firestore وكتابة تطبيقات غنية وقوية.
لضمان استمرار أداء تطبيقاتك بشكلٍ جيد مع زيادة حجم قاعدة البيانات وعدد الزيارات، من المفيد فهم آليات عمليات القراءة والكتابة في الخلفية Cloud Firestore. يجب أيضًا فهم كيفية تفاعل عمليات القراءة والكتابة مع طبقة التخزين والقيود الأساسية التي قد تؤثر في الأداء.
راجِع الأقسام التالية للتعرّف على أفضل الممارسات قبل تصميم تطبيقك.
فهم المكوّنات عالية المستوى
يوضّح المخطّط البياني التالي المكوّنات الرئيسية المتضمّنة في طلب بيانات من واجهة برمجة التطبيقات Cloud Firestore.
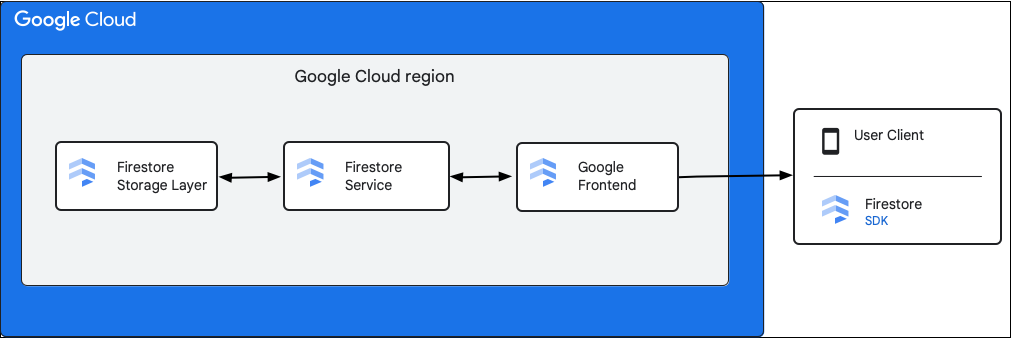
Cloud Firestore حزمة تطوير البرامج (SDK) ومكتبات العملاء
تتوافق Cloud Firestore مع حِزم SDK ومكتبات العملاء لمختلف الأنظمة الأساسية. على الرغم من أنّ التطبيق يمكنه إجراء طلبات HTTP وRPC مباشرةً إلى واجهة برمجة التطبيقات Cloud Firestore، فإنّ مكتبات البرامج توفّر طبقة تجريد لتبسيط استخدام واجهة برمجة التطبيقات وتنفيذ أفضل الممارسات. وقد توفّر أيضًا ميزات إضافية، مثل إمكانية الوصول بلا إنترنت وذاكرات التخزين المؤقت وما إلى ذلك.
Google Front End (GFE)
هذه خدمة بنية أساسية شائعة في جميع خدمات Google Cloud. يقبل GFE الطلبات الواردة ويعيد توجيهها إلى خدمة Google ذات الصلة (خدمة Cloud Firestore في هذا السياق). وتوفّر أيضًا وظائف مهمة أخرى، بما في ذلك الحماية من هجمات رفض الخدمة.
خدمة Cloud Firestore
تُجري خدمة Cloud Firestore عمليات تحقّق من طلب واجهة برمجة التطبيقات، بما في ذلك المصادقة والتفويض وعمليات التحقّق من الحصة وقواعد الأمان، كما تدير المعاملات. تتضمّن خدمة Cloud Firestore هذه برنامجًا للوصول إلى مساحة التخزين يتفاعل مع طبقة التخزين لقراءة البيانات وكتابتها.
طبقة التخزين Cloud Firestore
طبقة التخزين Cloud Firestore مسؤولة عن تخزين البيانات والبيانات الوصفية، وميزات قاعدة البيانات المرتبطة التي توفّرها Cloud Firestore. توضّح الأقسام التالية كيفية تنظيم البيانات في Cloud Firestore طبقة التخزين وكيفية توسيع نطاق النظام. يمكن أن تساعدك معرفة كيفية تنظيم البيانات في تصميم نموذج بيانات قابل للتوسّع وفهم أفضل الممارسات في Cloud Firestore.
نطاقات المفاتيح وعمليات التقسيم
Cloud Firestore هي قاعدة بيانات NoSQL تعتمد على المستندات. يمكنك تخزين البيانات في مستندات يتم تنظيمها في تسلسلات هرمية من مجموعات. تتم ترجمة التسلسل الهرمي للمجموعة ومعرّف المستند إلى مفتاح واحد لكل مستند. يتم تخزين المستندات بشكل منطقي وترتيبها معجميًا حسب هذا المفتاح الفردي. نستخدم مصطلح "نطاق المفاتيح" للإشارة إلى نطاق متجاور من المفاتيح حسب الترتيب المعجمي.
تكون قاعدة بيانات Cloud Firestore النموذجية كبيرة جدًا بحيث لا يمكن استيعابها على جهاز مادي واحد. هناك أيضًا سيناريوهات يكون فيها حجم العمل على البيانات كبيرًا جدًا بحيث لا يمكن لجهاز واحد التعامل معه. للتعامل مع أحجام العمل الكبيرة، يقسّم Cloud Firestore البيانات إلى أجزاء منفصلة يمكن تخزينها وتقديمها من أجهزة متعددة أو خوادم تخزين. يتم إنشاء هذه الأقسام في جداول قاعدة البيانات على شكل مجموعات من نطاقات المفاتيح تُعرف باسم عمليات التقسيم.
النسخ المتماثل المتزامن
من المهم ملاحظة أنّه يتم دائمًا تكرار قاعدة البيانات تلقائيًا وبشكل متزامن. تحتوي تقسيمات البيانات على نُسخ طبق الأصل في مناطق مختلفة لإبقائها متاحة حتى عندما يتعذّر الوصول إلى إحدى المناطق. تتم إدارة النسخ المتطابقة المتسقة مع النسخ المختلفة من الانقسام بواسطة خوارزمية Paxos لتحقيق توافق الآراء. يتم اختيار نسخة طبق الأصل واحدة من كل تقسيم لتعمل كقائد Paxos، وهي المسؤولة عن معالجة عمليات الكتابة في هذا التقسيم. تتيح لك عملية النسخ المتماثل المتزامنة إمكانية قراءة أحدث إصدار من البيانات من Cloud Firestore في أي وقت.
والنتيجة الإجمالية لذلك هي نظام قابل للتوسّع ومتاح بدرجة كبيرة يوفّر زمن استجابة منخفضًا لكلّ من عمليات القراءة والكتابة، بغض النظر عن أعباء العمل الكبيرة وعلى نطاق واسع جدًا.
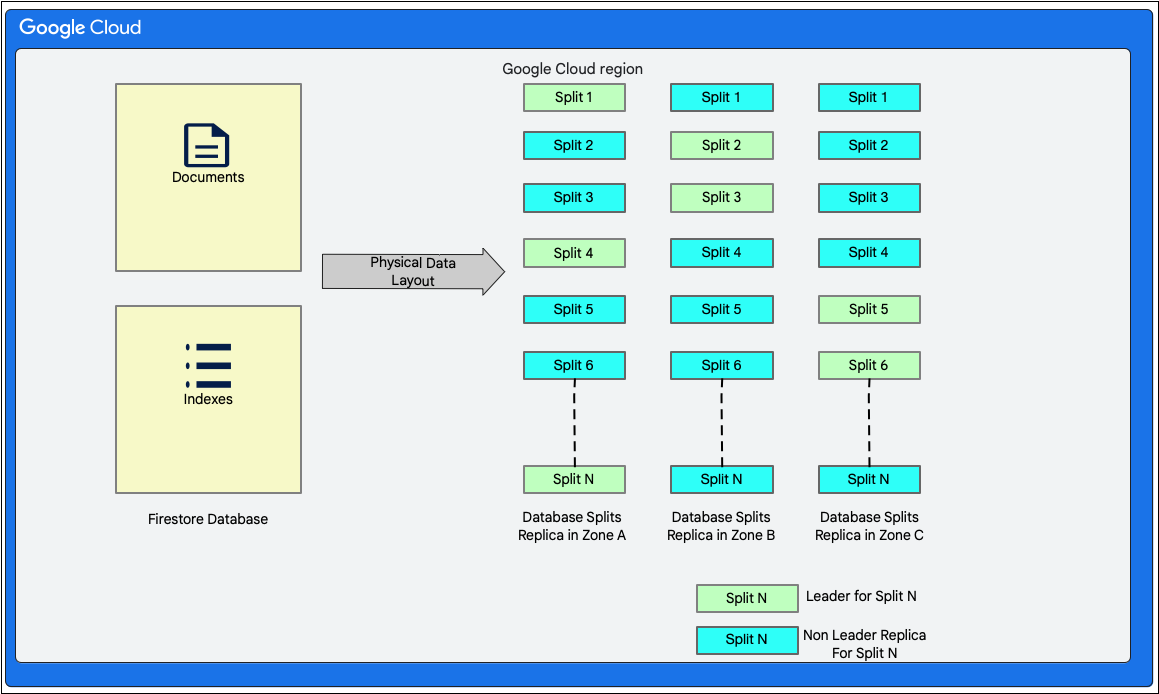
تنسيق البيانات
Cloud Firestore هي قاعدة بيانات مستندات بدون مخطط. ومع ذلك، يتم تنظيم البيانات داخليًا بشكل أساسي في جدولَين بنمط قاعدة البيانات الارتباطية في طبقة التخزين على النحو التالي:
- جدول المستندات: يتم تخزين المستندات في هذا الجدول.
- جدول الفهارس: يتم تخزين إدخالات الفهرس التي تتيح الحصول على النتائج بكفاءة وترتيبها حسب قيمة الفهرس في هذا الجدول.
يوضّح المخطّط البياني التالي الشكل الذي قد تبدو عليه جداول قاعدة بيانات Cloud Firestore مع عمليات التقسيم. يتم تكرار عمليات التقسيم في ثلاث مناطق مختلفة، ويتم تعيين قائد Paxos لكل عملية تقسيم.
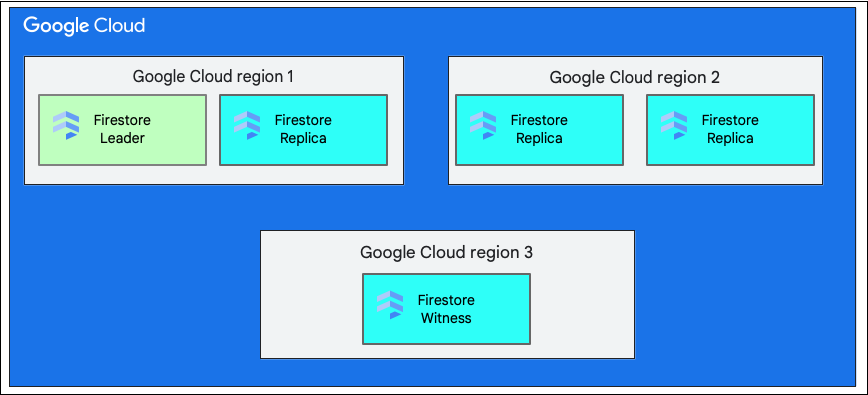
منطقة واحدة مقابل مناطق متعدّدة
عند إنشاء قاعدة بيانات، يجب اختيار منطقة أو منطقة متعدّدة.
الموقع الجغرافي الإقليمي الفردي هو موقع جغرافي محدّد، مثل us-west1. تحتوي تقسيمات بيانات قاعدة بيانات Cloud Firestore على نُسخ طبق الأصل في مناطق مختلفة ضمن المنطقة المحدّدة، كما هو موضّح سابقًا.
يتألف الموقع الجغرافي المتعدّد المناطق من مجموعة محدّدة من المناطق التي يتم فيها تخزين نُسخ طبق الأصل من قاعدة البيانات. في عملية نشر Cloud Firestore في مناطق متعدّدة، يتضمّن اثنان من المناطق نسخًا طبق الأصل كاملة من البيانات بأكملها في قاعدة البيانات. تتضمّن منطقة ثالثة نسخة طبق الأصل من شاهد لا تحتفظ بمجموعة كاملة من البيانات، ولكنها تشارك في عملية النسخ المتماثل. من خلال تكرار البيانات بين مناطق متعددة، يمكن كتابة البيانات وقراءتها حتى في حال فقدان منطقة بأكملها.
لمزيد من المعلومات عن المواقع الجغرافية في منطقة معيّنة، اطّلِع على مواقع Cloud Firestore.
فهم مدة صلاحية عملية الكتابة في Cloud Firestore
يمكن Cloud Firestore للعميل كتابة البيانات عن طريق إنشاء مستند واحد أو تعديله أو حذفه. تتطلّب الكتابة إلى مستند واحد تعديل كلّ من المستند وإدخالات الفهرس المرتبطة به بشكل ذري في طبقة التخزين. تتيح Cloud Firestore أيضًا العمليات الذرية التي تتألف من عمليات قراءة و/أو كتابة متعددة لمستند واحد أو أكثر.
بالنسبة إلى جميع أنواع عمليات الكتابة، توفّر Cloud Firestore خصائص ACID (التجزئة والاتساق والعزل والمتانة) لقواعد البيانات العلائقية. توفّر Cloud Firestore أيضًا التسلسلية، ما يعني أنّ جميع المعاملات تظهر كما لو تم تنفيذها بترتيب تسلسلي.
الخطوات العامة في عملية كتابة البيانات
عندما يرسل عميل Cloud Firestore عملية كتابة أو يُجري معاملة باستخدام أي من الطرق المذكورة سابقًا، يتم تنفيذ ذلك داخليًا كـ معاملة قراءة وكتابة في قاعدة البيانات في طبقة التخزين. تتيح المعاملة Cloud Firestore توفير خصائص ACID المذكورة سابقًا.
في الخطوة الأولى من المعاملة، تقرأ Cloud Firestore المستند الحالي، وتحدّد التغييرات التي سيتم إجراؤها على البيانات في جدول المستندات.
ويشمل ذلك أيضًا إجراء التعديلات اللازمة على جدول الفهارس على النحو التالي:
- يجب أن تتضمّن الحقول التي تتم إضافتها إلى المستندات عمليات إدراج مقابلة في جدول الفهارس.
- يجب أن تتضمّن عمليات الحذف في جدول الفهارس عمليات حذف مقابلة للحقول التي تتم إزالتها من المستندات.
- يجب أن تتضمّن الحقول التي يتم تعديلها في المستندات عمليات حذف (للقيم القديمة) وعمليات إدراج (للقيم الجديدة) في جدول الفهارس.
لحساب عمليات التغيير المذكورة سابقًا، تقرأ Cloud Firestore إعدادات الفهرسة للمشروع. يخزّن إعداد الفهرسة معلومات حول الفهارس لمشروع ما. تستخدم Cloud Firestore نوعَين من الفهارس: الفهارس ذات الحقل الواحد والفهارس المركّبة. للحصول على فهم تفصيلي للفهارس التي تم إنشاؤها في Cloud Firestore، راجِع أنواع الفهارس في Cloud Firestore.
بعد احتساب التغييرات، يجمعها Cloud Firestore داخل معاملة ثم ينفّذها.
فهم عملية الكتابة في طبقة التخزين
كما ذكرنا سابقًا، تتضمّن عملية الكتابة في Cloud Firestore عملية قراءة وكتابة في طبقة التخزين. استنادًا إلى تخطيط البيانات، قد تتضمّن عملية الكتابة تقسيمًا واحدًا أو أكثر كما هو موضّح في تخطيط البيانات.
في الرسم البياني التالي، تحتوي قاعدة بيانات Cloud Firestore على ثمانية أقسام (مميّزة بالأرقام من 1 إلى 8) مستضافة على ثلاثة خوادم تخزين مختلفة في منطقة واحدة، ويتم تكرار كل قسم في 3 مناطق مختلفة(أو أكثر). لكل عملية تقسيم قائد Paxos، وقد يكون القائد في منطقة مختلفة لكل عملية تقسيم.
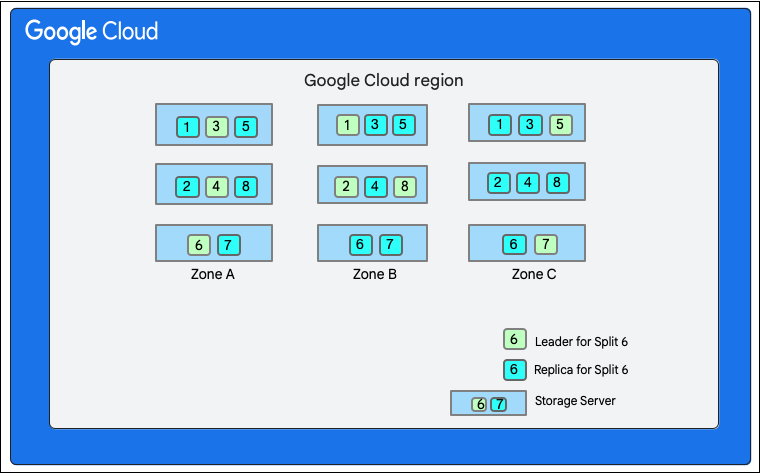 تقسيم قاعدة بيانات Cloud Firestore">
تقسيم قاعدة بيانات Cloud Firestore">
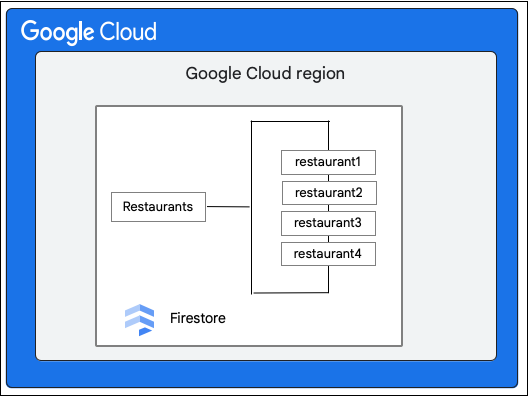
لنفترض أنّ لديك قاعدة بيانات Cloud Firestore تتضمّن مجموعة Restaurants على النحو التالي:
يطلب العميل Cloud Firestore إجراء التغيير التالي على مستند في المجموعة Restaurant من خلال تعديل قيمة الحقل priceCategory.
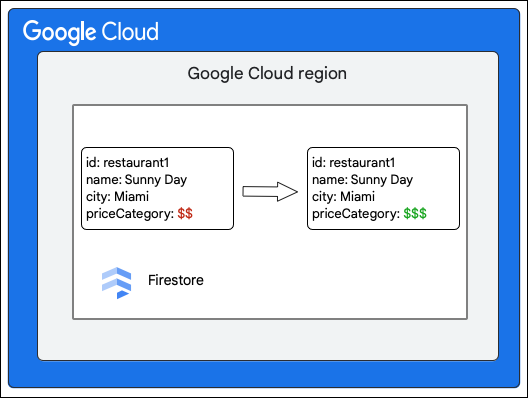
توضّح الخطوات العالية المستوى التالية ما يحدث كجزء من عملية الكتابة:
- إنشاء معاملة قراءة وكتابة
- قراءة المستند
restaurant1في المجموعةRestaurantsمن جدول المستندات من طبقة التخزين - اقرأ الفهارس الخاصة بالمستند من جدول الفهارس.
- احتساب التغييرات التي سيتم إجراؤها على البيانات في هذه الحالة، هناك خمس عمليات تحويل:
- M1: تعديل الصف الخاص بـ
restaurant1في جدول المستندات ليعكس التغيير في قيمة الحقلpriceCategory - M2 وM3: احذف الصفوف الخاصة بالقيمة القديمة لـ
priceCategoryفي جدول الفهارس للفهارس التنازلية والتصاعدية. - M4 وM5: أدرِج صفوفًا للقيمة الجديدة
priceCategoryفي جدول الفهارس للفهارس التنازلية والتصاعدية.
- M1: تعديل الصف الخاص بـ
- إجراء هذه التغييرات
يبحث عميل التخزين في خدمة Cloud Firestore عن عمليات التقسيم التي تملك مفاتيح الصفوف المطلوب تغييرها. لنفترض أنّ "التقسيم 3" يعرض الإعلان M1، و"التقسيم 6" يعرض الإعلانات من M2 إلى M5. هناك معاملة موزّعة تشمل كل عمليات التقسيم هذه باعتبارها مشاركين. قد تتضمّن تقسيمات المشاركين أيضًا أي تقسيم آخر تمت قراءة البيانات منه سابقًا كجزء من عملية القراءة والكتابة.
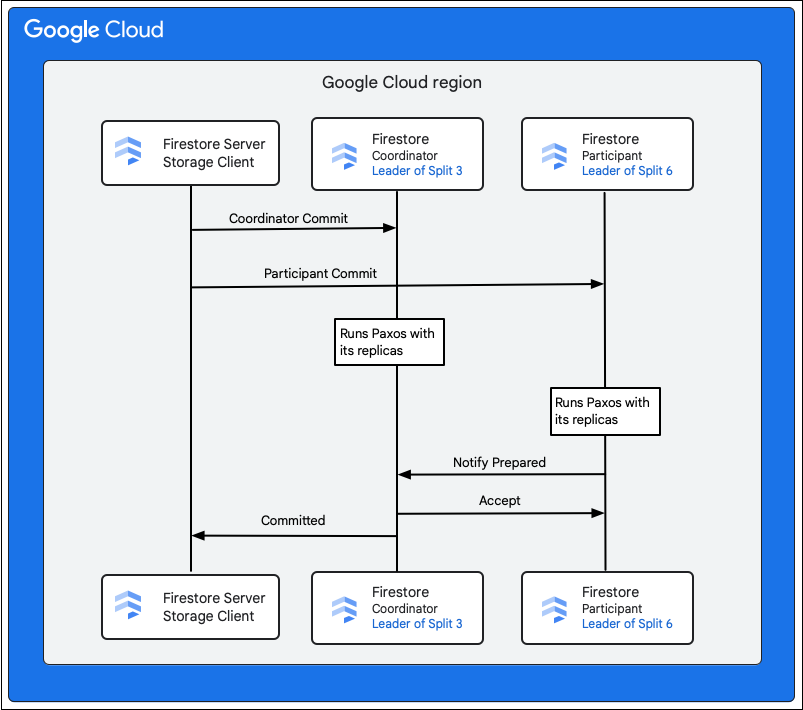
توضّح الخطوات التالية ما يحدث كجزء من عملية الالتزام:
- يرسل عميل التخزين عملية تأكيد. يتضمّن التعديل عمليات التغيير M1-M5.
- التقسيمان 3 و6 هما المشاركان في هذه المعاملة. يتم اختيار أحد المشاركين كمنسّق، مثل Split 3. تتمثّل مهمة المنسّق في التأكّد من إتمام المعاملة أو إلغائها بشكل متكامل لدى جميع المشاركين.
- تكون النسخ المتماثلة الرئيسية لهذه الانقسامات مسؤولة عن العمل الذي ينجزه المشاركون والمنسّقون.
- يُشغّل كل مشارك ومنسّق خوارزمية Paxos مع النسخ المتماثلة الخاصة به.
- يدير القائد خوارزمية Paxos مع النسخ المتماثلة. يتم تحقيق النصاب إذا ردّت معظم النسخ المتماثلة برسالة
ok to commitإلى العقدة الرئيسية. - بعد ذلك، يرسل كل مشارك إشعارًا إلى المنسّق عندما يكون مستعدًا (المرحلة الأولى من عملية التنفيذ على مرحلتين). إذا لم يتمكّن أي مشارك من إتمام المعاملة، سيتم
abortsالمعاملة بأكملها.
- يدير القائد خوارزمية Paxos مع النسخ المتماثلة. يتم تحقيق النصاب إذا ردّت معظم النسخ المتماثلة برسالة
- بعد أن يتأكّد المنسّق من أنّ جميع المشاركين، بما في ذلك نفسه، مستعدون، يرسل نتيجة المعاملة
acceptإلى جميع المشاركين (المرحلة الثانية من عملية الالتزام على مرحلتين). في هذه المرحلة، يسجّل كل مشارك قرار التنفيذ في وحدة تخزين ثابتة ويتم تنفيذ المعاملة. - يردّ المنسّق على عميل التخزين في Cloud Firestore بأنّ المعاملة قد تمّ تنفيذها. في الوقت نفسه، يطبّق المنسّق وجميع المشاركين التغييرات على البيانات.
عندما تكون قاعدة بيانات Cloud Firestore صغيرة، قد يحدث أن يمتلك تقسيم واحد جميع المفاتيح في عمليات التغيير M1-M5. في هذه الحالة، لا يوجد سوى مشارك واحد في المعاملة، ولا يلزم تنفيذ عملية الإكمال على مرحلتين المذكورة سابقًا، ما يؤدي إلى تسريع عمليات الكتابة.
عمليات الكتابة في مناطق متعدّدة
في عملية نشر على مستوى مناطق متعدّدة، يؤدي توزيع النسخ المتماثلة على المناطق إلى زيادة مدى التوفّر، ولكن بتكلفة أداء. يستغرق التواصل بين النسخ المتماثلة في مناطق مختلفة وقتًا أطول للوصول إلى الوجهة والعودة منها. وبالتالي، يكون الحد الأدنى لوقت الاستجابة لعمليات Cloud Firestore أطول قليلاً مقارنةً بعمليات النشر في منطقة واحدة.
نضبط النسخ المتماثلة بطريقة تضمن بقاء القيادة في عمليات التقسيم دائمًا في المنطقة الأساسية. المنطقة الأساسية هي المنطقة التي يتم منها استقبال عدد الزيارات إلى خادم Cloud Firestore. يؤدي قرار القيادة هذا إلى تقليل تأخير رحلة الذهاب والعودة في الاتصال بين عميل التخزين في Cloud Firestore وقائد النسخة المتماثلة (أو المنسّق للمعاملات المتعددة الأجزاء).
تتضمّن كل عملية كتابة في Cloud Firestore أيضًا بعض التفاعل مع المحرّك في الوقت الفعلي في Cloud Firestore. لمزيد من المعلومات عن طلبات البحث في الوقت الفعلي، اطّلِع على فهم طلبات البحث في الوقت الفعلي على نطاق واسع.
فهم دورة حياة قراءة في Cloud Firestore
يتناول هذا القسم عمليات القراءة المستقلة وغير الآنية في Cloud Firestore. داخليًا، يعالج خادم Cloud Firestore معظم هذه الطلبات في مرحلتَين رئيسيتَين:
- عملية فحص لنطاق واحد في جدول الفهارس
- عمليات البحث المستندة إلى النقاط في جدول المستندات استنادًا إلى نتيجة المسح الضوئي السابق
تتم قراءة البيانات من طبقة التخزين داخليًا باستخدام معاملة قاعدة بيانات لضمان عمليات قراءة متسقة. ومع ذلك، على عكس المعاملات المستخدَمة في عمليات الكتابة، لا تستخدم هذه المعاملات عمليات قفل. بدلاً من ذلك، تعمل من خلال اختيار طابع زمني، ثم تنفيذ جميع عمليات القراءة في هذا الطابع الزمني. وبما أنّها لا تحصل على أقفال، فهي لا تحظر معاملات القراءة والكتابة المتزامنة. لتنفيذ هذه المعاملة، يحدّد برنامج التخزين في Cloud Firestore حدًا زمنيًا، ما يوضّح لطبقة التخزين كيفية اختيار طابع زمني للقراءة. يتم تحديد نوع الطابع الزمني المرتبط الذي يختاره عميل التخزين في Cloud Firestore من خلال خيارات القراءة لطلب القراءة.
فهم معاملة القراءة في طبقة التخزين
يوضّح هذا القسم أنواع عمليات القراءة وكيفية معالجتها في طبقة التخزين في Cloud Firestore.
كتب رائعة
تكون عمليات القراءة Cloud Firestore متسقة بشدة تلقائيًا. يعني هذا الاتساق القوي أنّ عملية القراءة Cloud Firestore تعرض أحدث إصدار من البيانات يعكس جميع عمليات الكتابة التي تم تنفيذها حتى بداية عملية القراءة.
قراءة عملية تقسيم واحدة
يبحث برنامج تخزين البيانات في Cloud Firestore عن عمليات التقسيم التي تملك مفاتيح الصفوف المطلوب قراءتها. لنفترض أنّها تحتاج إلى قراءة من Split 3 من القسم السابق. يرسل العميل طلب القراءة إلى النسخة المتماثلة الأقرب لتقليل وقت الاستجابة.
في هذه المرحلة، قد تحدث الحالات التالية استنادًا إلى النسخة المتماثلة المحدّدة:
- يتم إرسال طلب القراءة إلى نسخة طبق الأصل رئيسية (المنطقة أ).
- بما أنّ القائد يكون على علم دائمًا بآخر المعلومات، يمكنه المتابعة مباشرةً.
- يتم توجيه طلب القراءة إلى نسخة طبق الأصل غير رئيسية (مثل المنطقة B)
- قد تعرف المجموعة الفرعية 3 من خلال حالتها الداخلية أنّ لديها معلومات كافية لعرض القراءة، وتفعل ذلك.
- لا يمكن لعملية التقسيم 3 تحديد ما إذا كانت قد اطّلعت على أحدث البيانات. يرسل هذا الإجراء رسالة إلى القائد لطلب الطابع الزمني لآخر معاملة يجب تطبيقها لعرض القراءة. بعد تطبيق هذه المعاملة، يمكن مواصلة القراءة.
Cloud Firestore ثم يعرض الردّ على العميل.
القراءة المتعددة المقسّمة
في حال كان يجب إجراء عمليات القراءة من عدة تقسيمات، تحدث الآلية نفسها في جميع التقسيمات. بعد استرداد البيانات من جميع عمليات التقسيم، يجمع برنامج تخزين العميل في Cloud Firestore النتائج. بعد ذلك، تردّ Cloud Firestore على العميل بهذه البيانات.
قراءات قديمة
تكون القراءات القوية هي الوضع التلقائي في Cloud Firestore. ومع ذلك، قد يؤدي ذلك إلى زيادة محتملة في وقت الاستجابة بسبب التواصل الذي قد يكون مطلوبًا مع العقدة الرئيسية. في كثير من الأحيان، لا يحتاج تطبيق Cloud Firestore إلى قراءة أحدث إصدار من البيانات، وتعمل الوظيفة بشكل جيد مع البيانات التي قد تكون قديمة لبضع ثوانٍ.
في هذه الحالة، يمكن للعميل اختيار تلقّي عمليات قراءة قديمة باستخدام read_time خيارات القراءة. في هذه الحالة، تتم عمليات القراءة كما كانت البيانات في read_time، ومن المرجّح جدًا أنّ النسخة المتماثلة الأقرب قد تحقّقت بالفعل من توفّر البيانات في read_time المحدّد.
للحصول على أداء أفضل بشكل ملحوظ، تكون قيمة عدم الحداثة المعقولة هي 15 ثانية. حتى بالنسبة إلى عمليات القراءة القديمة، تكون الصفوف التي يتم عرضها متسقة مع بعضها البعض.
تجنُّب نقاط الاتصال
يتم تقسيم عمليات التقسيم في Cloud Firestore تلقائيًا إلى أجزاء أصغر لتوزيع عبء عرض المحتوى على المزيد من خوادم التخزين عند الحاجة أو عند توسيع مساحة المفاتيح. يتم الاحتفاظ بعمليات التقسيم التي تم إنشاؤها للتعامل مع الزيارات الزائدة لمدة 24 ساعة تقريبًا حتى إذا توقفت الزيارات. لذلك، إذا كانت هناك زيادات متكرّرة في عدد الزيارات، يتم الحفاظ على عمليات التقسيم وإضافة المزيد منها عند الحاجة. تساعد هذه الآليات قواعد بيانات Cloud Firestore على التوسّع تلقائيًا في حال زيادة حجم قاعدة البيانات أو عدد الزيارات. ومع ذلك، هناك بعض القيود التي يجب الانتباه إليها كما هو موضّح أدناه.
يستغرق تقسيم التخزين والتحميل وقتًا، وقد يؤدي زيادة عدد الزيارات بسرعة كبيرة إلى حدوث أخطاء في المهلة أو وقت الاستجابة، ويُشار إليها عادةً باسم النقاط الساخنة، وذلك أثناء تعديل الخدمة. من أفضل الممارسات توزيع العمليات على نطاق المفاتيح، مع زيادة عدد الزيارات على مجموعة في قاعدة بيانات تتضمّن 500 عملية في الثانية. بعد هذه الزيادة التدريجية، يمكنك زيادة عدد الزيارات بنسبة تصل إلى% 50 كل خمس دقائق. تُعرف هذه العملية باسم قاعدة 500/50/5، وهي تضع قاعدة البيانات في موضع يتيح لها التوسّع على النحو الأمثل لتلبية أعباء العمل.
على الرغم من أنّ عمليات التقسيم يتم إنشاؤها تلقائيًا مع زيادة الحمل، لا يمكن لـ Cloud Firestore تقسيم نطاق مفاتيح إلا إلى أن يعرض مستندًا واحدًا باستخدام مجموعة مخصّصة من خوادم التخزين المنسوخة. نتيجةً لذلك، قد تؤدي الكميات الكبيرة والمستمرة من العمليات المتزامنة على مستند واحد إلى حدوث نقطة ساخنة في هذا المستند. إذا واجهت حالات تأخير عالية مستمرة في مستند واحد، عليك التفكير في تعديل نموذج البيانات لتقسيم البيانات أو تكرارها في مستندات متعددة.
تحدث أخطاء التنازع عندما تحاول عمليات متعددة قراءة و/أو كتابة المستند نفسه في الوقت نفسه.
تحدث حالة خاصة أخرى من hotspotting عندما يتم استخدام مفتاح متزايد/متناقص بالتسلسل كمعرّف مستند في Cloud Firestore، ويكون هناك عدد كبير جدًا من العمليات في الثانية. لن يساعد إنشاء المزيد من عمليات التقسيم في هذه الحالة، لأنّ الارتفاع المفاجئ في عدد الزيارات سينتقل ببساطة إلى عملية التقسيم التي تم إنشاؤها حديثًا. بما أنّ Cloud Firestore يفهرس تلقائيًا جميع الحقول في المستند تلقائيًا، يمكن أيضًا إنشاء نقاط فعّالة متحرّكة في مساحة الفهرس لحقل مستند يحتوي على قيمة متزايدة أو متناقصة بالتسلسل، مثل الطابع الزمني.
يُرجى العِلم أنّه باتّباع الممارسات الموضّحة أعلاه، يمكن توسيع نطاق Cloud Firestore لتقديم أحجام عمل كبيرة بشكل عشوائي بدون الحاجة إلى تعديل أي إعدادات.
تحديد المشاكل وحلّها
توفّر Cloud Firestore أداة Key Visualizer كأداة تشخيص مصمَّمة لتحليل أنماط الاستخدام وتحديد المشاكل وحلّها.