
อ่านเอกสารนี้เพื่อประกอบการตัดสินใจเกี่ยวกับการออกแบบแอปพลิเคชันให้มีประสิทธิภาพและความน่าเชื่อถือสูง เอกสารนี้มีหัวข้อขั้นสูงของ Cloud Firestore หากเพิ่งเริ่มต้นใช้งาน Cloud Firestore โปรดดูคู่มือเริ่มใช้งานฉบับย่อแทน
Cloud Firestore คือฐานข้อมูลที่ยืดหยุ่นและปรับขนาดได้สำหรับการพัฒนาอุปกรณ์เคลื่อนที่ เว็บ และเซิร์ฟเวอร์จาก Firebase และ Google Cloud การเริ่มต้นใช้งาน Cloud Firestore นั้นง่ายมาก และคุณสามารถเขียนแอปพลิเคชันที่ทรงพลังและมีฟีเจอร์มากมายได้
เพื่อให้แน่ใจว่าแอปพลิเคชันจะยังคงทำงานได้ดีเมื่อขนาดฐานข้อมูลและการเข้าชมเพิ่มขึ้น คุณควรทำความเข้าใจกลไกการอ่านและการเขียนในCloud Firestoreแบ็กเอนด์ นอกจากนี้ คุณต้องเข้าใจการโต้ตอบของการอ่านและการเขียนกับเลเยอร์พื้นที่เก็บข้อมูลและข้อจำกัดพื้นฐานที่อาจส่งผลต่อประสิทธิภาพด้วย
โปรดดูแนวทางปฏิบัติแนะนำในส่วนต่อไปนี้ก่อนออกแบบแอปพลิเคชัน
ทำความเข้าใจคอมโพเนนต์ระดับสูง
แผนภาพต่อไปนี้แสดงคอมโพเนนต์ระดับสูงที่เกี่ยวข้องกับคำขอ API ของ Cloud Firestore
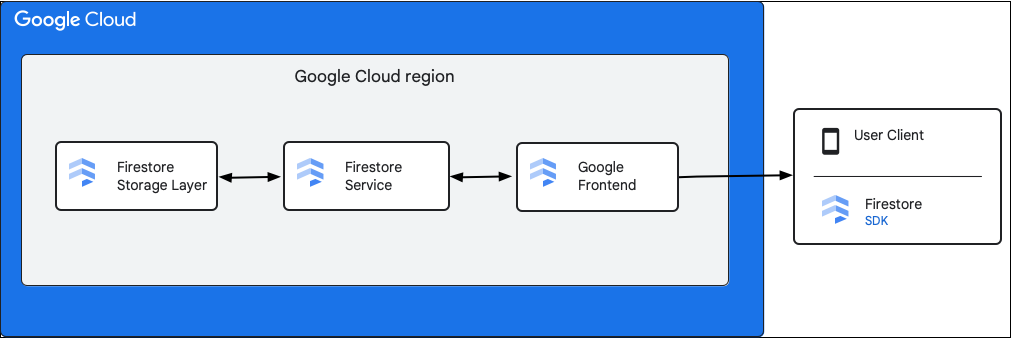
Cloud Firestore SDK และไลบรารีของไคลเอ็นต์
Cloud Firestore รองรับ SDK และไลบรารีไคลเอ็นต์สำหรับแพลตฟอร์มต่างๆ แม้ว่าแอปจะสามารถเรียก HTTP และ RPC ไปยัง Cloud Firestore API ได้โดยตรง แต่ไลบรารีของไคลเอ็นต์จะจัดเลเยอร์การแยกข้อมูลเพื่อลดความซับซ้อนในการใช้งาน API และใช้แนวทางปฏิบัติแนะนำ นอกจากนี้ ยังอาจมีฟีเจอร์เพิ่มเติม เช่น การเข้าถึงแบบออฟไลน์ แคช และอื่นๆ
Google Front End (GFE)
ซึ่งเป็นบริการโครงสร้างพื้นฐานที่ใช้ร่วมกันในบริการคลาวด์ทั้งหมดของ Google GFE จะยอมรับคำขอขาเข้าและส่งต่อคำขอไปยังบริการของ Google ที่เกี่ยวข้อง (Cloud Firestore ในบริบทนี้) นอกจากนี้ ยังมีฟังก์ชันการทำงานที่สำคัญอื่นๆ รวมถึงการป้องกันการโจมตีแบบปฏิเสธการให้บริการ
Cloud Firestore บริการ
Cloud Firestore บริการจะตรวจสอบคำขอ API ซึ่งรวมถึงการตรวจสอบสิทธิ์ การให้สิทธิ์ การตรวจสอบโควต้า และกฎความปลอดภัย รวมถึงจัดการธุรกรรมด้วย Cloud Firestore บริการนี้มีไคลเอ็นต์พื้นที่เก็บข้อมูลที่โต้ตอบกับเลเยอร์พื้นที่เก็บข้อมูลสำหรับการอ่านและเขียนข้อมูล
Cloud Firestore เลเยอร์พื้นที่เก็บข้อมูล
Cloud Firestore เลเยอร์พื้นที่เก็บข้อมูลมีหน้าที่จัดเก็บทั้งข้อมูลและข้อมูลเมตา รวมถึงฟีเจอร์ฐานข้อมูลที่เกี่ยวข้องซึ่ง Cloud Firestore เป็นผู้ให้บริการ ส่วนต่อไปนี้จะอธิบายวิธีจัดระเบียบข้อมูลในCloud Firestoreเลเยอร์พื้นที่เก็บข้อมูลและวิธีที่ระบบปรับขนาด การเรียนรู้เกี่ยวกับวิธีจัดระเบียบข้อมูลจะช่วยให้คุณออกแบบโมเดลข้อมูลที่ปรับขนาดได้และเข้าใจแนวทางปฏิบัติแนะนำใน Cloud Firestore ได้ดียิ่งขึ้น
ช่วงคีย์และการแยก
Cloud Firestore เป็นฐานข้อมูล NoSQL ที่เน้นเอกสาร คุณจัดเก็บข้อมูลในเอกสาร ซึ่งจัดระเบียบเป็นลำดับชั้นของคอลเล็กชัน ระบบจะแปลลำดับชั้นของคอลเล็กชันและรหัสเอกสารเป็นคีย์เดียวสำหรับเอกสารแต่ละรายการ ระบบจะจัดเก็บเอกสารอย่างเป็นตรรกะและจัดเรียงตามพจนานุกรมด้วยคีย์เดียวนี้ เราใช้คำว่าช่วงคีย์เพื่ออ้างอิงถึงช่วงของคีย์ที่อยู่ติดกันตามลำดับพจนานุกรม
โดยปกติแล้ว Cloud Firestore ฐานข้อมูลมีขนาดใหญ่เกินกว่าจะใส่ในเครื่องจริงเครื่องเดียวได้ นอกจากนี้ยังมีสถานการณ์ที่ภาระงานในข้อมูลหนักเกินกว่าที่เครื่องเดียวจะรับไหว Cloud Firestore จะแบ่งพาร์ติชันข้อมูลออกเป็นส่วนๆ แยกกันซึ่งจัดเก็บและแสดงจากเครื่องหลายเครื่องหรือเซิร์ฟเวอร์พื้นที่เก็บข้อมูลได้ เพื่อรองรับปริมาณงานจำนวนมาก พาร์ติชันเหล่านี้สร้างขึ้นในตารางฐานข้อมูลเป็นบล็อกของช่วงคีย์ที่เรียกว่าการแยก
การจำลองแบบซิงโครนัส
โปรดทราบว่าระบบจะจำลองแบบฐานข้อมูลโดยอัตโนมัติและพร้อมกันเสมอ การแยกข้อมูลจะมีสำเนาในโซนต่างๆ เพื่อให้ข้อมูลพร้อมใช้งานแม้ว่าโซนจะเข้าถึงไม่ได้ก็ตาม อัลกอริทึม Paxos จะจัดการการจำลองที่สอดคล้องกันไปยังสำเนาต่างๆ ของการแยกเพื่อสร้างฉันทามติ ระบบจะเลือกสำเนาของแต่ละการแยกเพื่อทำหน้าที่เป็นผู้นำ Paxos ซึ่งมีหน้าที่รับผิดชอบในการจัดการการเขียนไปยังการแยกนั้น การจำลองแบบพร้อมกันช่วยให้คุณอ่านข้อมูลเวอร์ชันล่าสุดจาก Cloud Firestore ได้เสมอ
ผลลัพธ์โดยรวมคือระบบที่ปรับขนาดได้และมีความพร้อมใช้งานสูงซึ่งมีเวลาในการตอบสนองต่ำสำหรับการอ่านและการเขียน ไม่ว่าจะมีภาระงานหนักเพียงใดและมีขนาดใหญ่มากเพียงใด
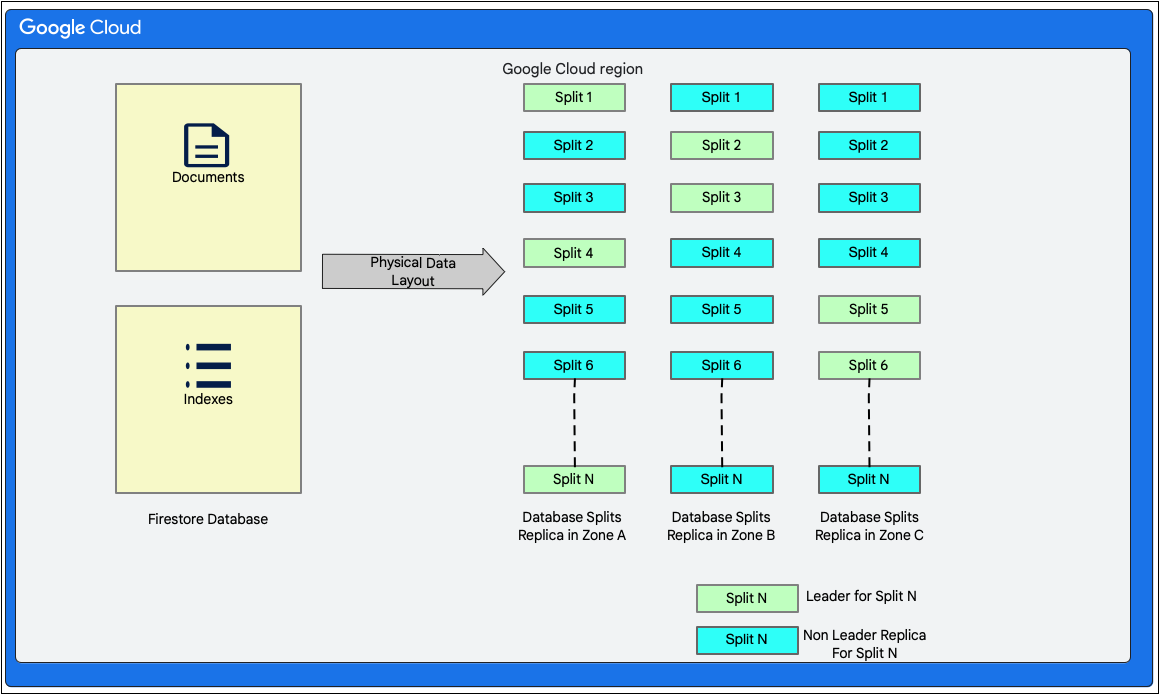
เลย์เอาต์ข้อมูล
Cloud Firestore เป็นฐานข้อมูลเอกสารแบบไม่มีสคีมา อย่างไรก็ตาม ภายในแล้วระบบจะจัดวางข้อมูลเป็นหลักในตาราง 2 ตารางในรูปแบบฐานข้อมูลเชิงสัมพันธ์ในเลเยอร์พื้นที่เก็บข้อมูล ดังนี้
- ตารางเอกสาร: ระบบจะจัดเก็บเอกสารไว้ในตารางนี้
- ตารางดัชนี: รายการดัชนีที่ช่วยให้รับผลลัพธ์ได้อย่างมีประสิทธิภาพและจัดเรียงตามค่าดัชนีจะจัดเก็บไว้ในตารางนี้
แผนภาพต่อไปนี้แสดงลักษณะที่ตารางสำหรับฐานข้อมูล Cloud Firestore อาจมีลักษณะเป็นอย่างไรเมื่อมีการแยก การแยกจะจำลองใน 3 โซนที่แตกต่างกัน และการแยกแต่ละครั้งจะมีผู้นำ Paxos ที่ได้รับมอบหมาย
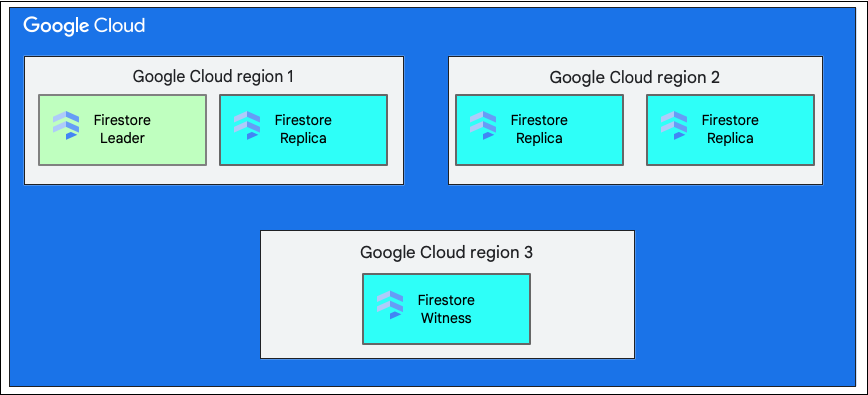
ภูมิภาคเดียวเทียบกับหลายภูมิภาค
เมื่อสร้างฐานข้อมูล คุณต้องเลือกภูมิภาคหรือหลายภูมิภาค
ตำแหน่งระดับภูมิภาคเดียวคือตำแหน่งทางภูมิศาสตร์ที่เฉพาะเจาะจง เช่น us-west1 การแยกข้อมูลของฐานข้อมูล Cloud Firestore จะมีสำเนาในโซนต่างๆ ภายในภูมิภาคที่เลือก ดังที่อธิบายไว้ก่อนหน้านี้
ตำแหน่งแบบหลายภูมิภาคประกอบด้วยชุดภูมิภาคที่กำหนดไว้ซึ่งจัดเก็บสำเนาของฐานข้อมูล ในการติดตั้งใช้งาน Cloud Firestore แบบหลายภูมิภาค 2 ภูมิภาคจะมีสำเนาแบบเต็มของข้อมูลทั้งหมดในฐานข้อมูล ภูมิภาคที่ 3 มีสำเนาพยานที่ไม่ได้เก็บชุดข้อมูลทั้งหมดไว้ แต่มีส่วนร่วมในการจำลอง การจำลองข้อมูลระหว่างหลายภูมิภาคทำให้ข้อมูลพร้อมใช้งานสำหรับการเขียนและอ่านแม้ว่าทั้งภูมิภาคจะสูญหายไป
ดูข้อมูลเพิ่มเติมเกี่ยวกับสถานที่ตั้งของภูมิภาคได้ที่Cloud Firestoreสถานที่ตั้ง
ทำความเข้าใจวงจรการเขียนใน Cloud Firestore
Cloud Firestore ไคลเอ็นต์สามารถเขียนข้อมูลได้โดยการสร้าง อัปเดต หรือลบเอกสารเดียว การเขียนไปยังเอกสารเดียวต้องอัปเดตทั้งเอกสารและรายการดัชนีที่เชื่อมโยงแบบอะตอมในเลเยอร์ที่เก็บข้อมูล Cloud Firestore ยังรองรับการดำเนินการแบบอะตอมซึ่งประกอบด้วยการอ่านและ/หรือเขียนหลายรายการไปยังเอกสารอย่างน้อย 1 รายการด้วย
สำหรับการเขียนทุกประเภท Cloud Firestore จะมีคุณสมบัติ ACID (ความเป็นอะตอม ความสอดคล้อง การแยก และความทนทาน) ของฐานข้อมูลเชิงสัมพันธ์ Cloud Firestore ยังมีการทำให้เป็นอนุกรม ซึ่งหมายความว่าธุรกรรมทั้งหมดจะปรากฏราวกับว่าดำเนินการตามลำดับอนุกรม
ขั้นตอนระดับสูงในธุรกรรมการเขียน
เมื่อไคลเอ็นต์ Cloud Firestore ออกคำสั่งเขียนหรือยืนยันธุรกรรมโดยใช้วิธีใดก็ตามที่กล่าวถึงก่อนหน้านี้ ภายในระบบจะดำเนินการเป็นธุรกรรมการอ่าน-เขียนฐานข้อมูลในเลเยอร์พื้นที่เก็บข้อมูล ธุรกรรมนี้ช่วยให้ Cloud Firestore สามารถให้คุณสมบัติ ACID ที่กล่าวถึงก่อนหน้านี้
ในขั้นตอนแรกของธุรกรรม Cloud Firestore จะอ่านเอกสารที่มีอยู่ และพิจารณาการเปลี่ยนแปลงที่จะเกิดขึ้นกับข้อมูลในตารางเอกสาร
ซึ่งรวมถึงการอัปเดตตารางดัชนีที่จำเป็นดังนี้
- ฟิลด์ที่เพิ่มลงในเอกสารต้องมีการแทรกที่สอดคล้องกันในตารางดัชนี
- ฟิลด์ที่นำออกจากเอกสารต้องมีการลบที่สอดคล้องกันในตารางดัชนี
- ฟิลด์ที่กำลังแก้ไขในเอกสารต้องมีการลบ (สำหรับค่าเก่า) และการแทรก (สำหรับค่าใหม่) ทั้ง 2 อย่างในตารางดัชนี
หากต้องการคำนวณการเปลี่ยนแปลงที่กล่าวถึงก่อนหน้านี้ Cloud Firestore จะอ่านการกำหนดค่าการจัดทำดัชนีสำหรับโปรเจ็กต์ การกำหนดค่าการจัดทำดัชนีจะจัดเก็บข้อมูลเกี่ยวกับดัชนีสำหรับโปรเจ็กต์ Cloud Firestore ใช้ดัชนี 2 ประเภท ได้แก่ ดัชนีช่องเดียวและดัชนีผสม ดูรายละเอียดเกี่ยวกับดัชนีที่สร้างใน Cloud Firestore ได้ที่ประเภทดัชนีใน Cloud Firestore
เมื่อคำนวณการเปลี่ยนแปลงแล้ว Cloud Firestore จะรวบรวมการเปลี่ยนแปลงเหล่านั้นไว้ในธุรกรรม แล้วจึงยืนยัน
ทำความเข้าใจธุรกรรมการเขียนในเลเยอร์พื้นที่เก็บข้อมูล
ตามที่คุยกันไปก่อนหน้านี้ การเขียนใน Cloud Firestore เกี่ยวข้องกับธุรกรรมการอ่าน-เขียนในเลเยอร์พื้นที่เก็บข้อมูล การเขียนอาจเกี่ยวข้องกับการแยกอย่างน้อย 1 รายการตามเลย์เอาต์ของข้อมูลดังที่เห็นในเลย์เอาต์ข้อมูล
ในไดอะแกรมต่อไปนี้ Cloud Firestoreฐานข้อมูลมีการแยก 8 รายการ (ทำเครื่องหมาย 1-8) ซึ่งโฮสต์อยู่ในเซิร์ฟเวอร์พื้นที่เก็บข้อมูล 3 เครื่องที่แตกต่างกันในโซนเดียว และการแยกแต่ละรายการจะจำลองในโซนที่แตกต่างกัน 3 โซน(หรือมากกว่า) การแยกแต่ละครั้งจะมีผู้นำ Paxos ซึ่งอาจอยู่ในโซนที่แตกต่างกันสำหรับการแยกที่แตกต่างกัน
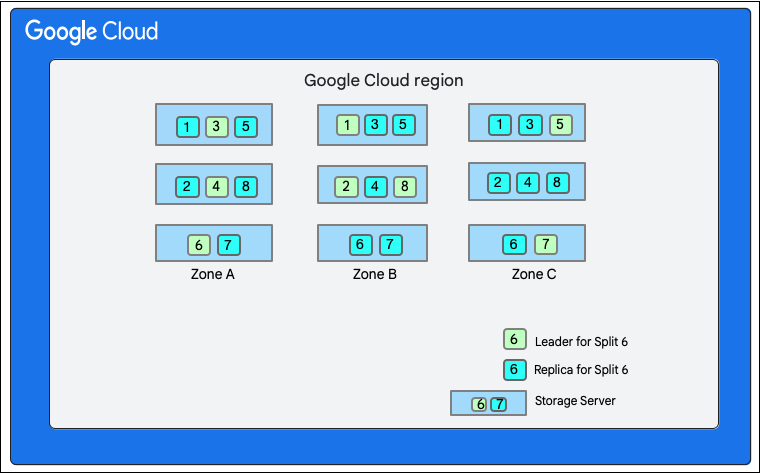 การแยกฐานข้อมูล Cloud Firestore">
การแยกฐานข้อมูล Cloud Firestore">
พิจารณาCloud Firestoreฐานข้อมูลที่มีRestaurantsคอลเล็กชันดังนี้
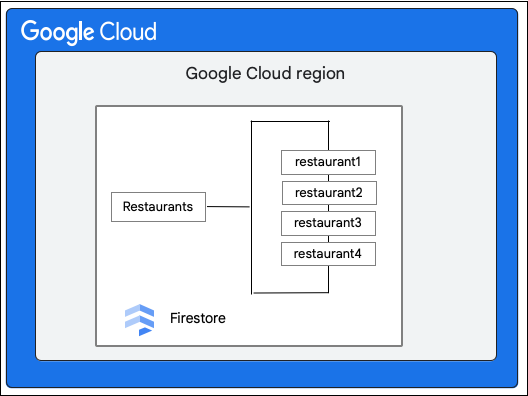
ไคลเอ็นต์ Cloud Firestore ขอเปลี่ยนแปลงเอกสารในคอลเล็กชัน Restaurant ดังต่อไปนี้โดยการอัปเดตค่าของฟิลด์ priceCategory
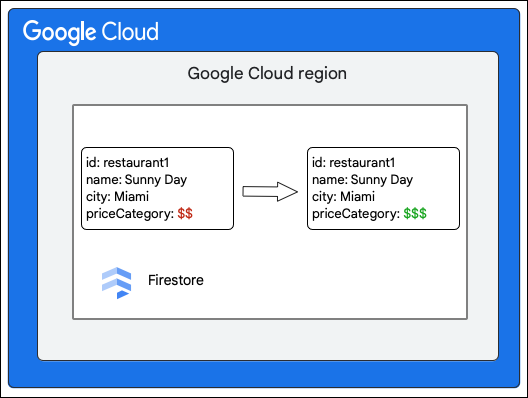
ขั้นตอนระดับสูงต่อไปนี้จะอธิบายสิ่งที่เกิดขึ้นในขั้นตอนการเขียน
- สร้างธุรกรรมแบบอ่าน-เขียน
- อ่าน
restaurant1เอกสารในคอลเล็กชันRestaurantsจากตารางเอกสารจากเลเยอร์พื้นที่เก็บข้อมูล - อ่านดัชนีสำหรับเอกสารจากตารางดัชนี
- คำนวณการเปลี่ยนแปลงที่จะเกิดขึ้นกับข้อมูล ในกรณีนี้ มีการเปลี่ยนแปลง 5 รายการ ดังนี้
- M1: อัปเดตแถวสำหรับ
restaurant1ในตารางเอกสารเพื่อให้สอดคล้องกับการเปลี่ยนแปลงค่าของฟิลด์priceCategory - M2 และ M3: ลบแถวสำหรับค่าเก่าของ
priceCategoryในตารางดัชนีสำหรับดัชนีจากมากไปน้อยและจากน้อยไปมาก - M4 และ M5: แทรกแถวสำหรับค่าใหม่ของ
priceCategoryในตารางดัชนีสำหรับดัชนีจากมากไปน้อยและจากน้อยไปมาก
- M1: อัปเดตแถวสำหรับ
- ยืนยันการกลายพันธุ์เหล่านี้
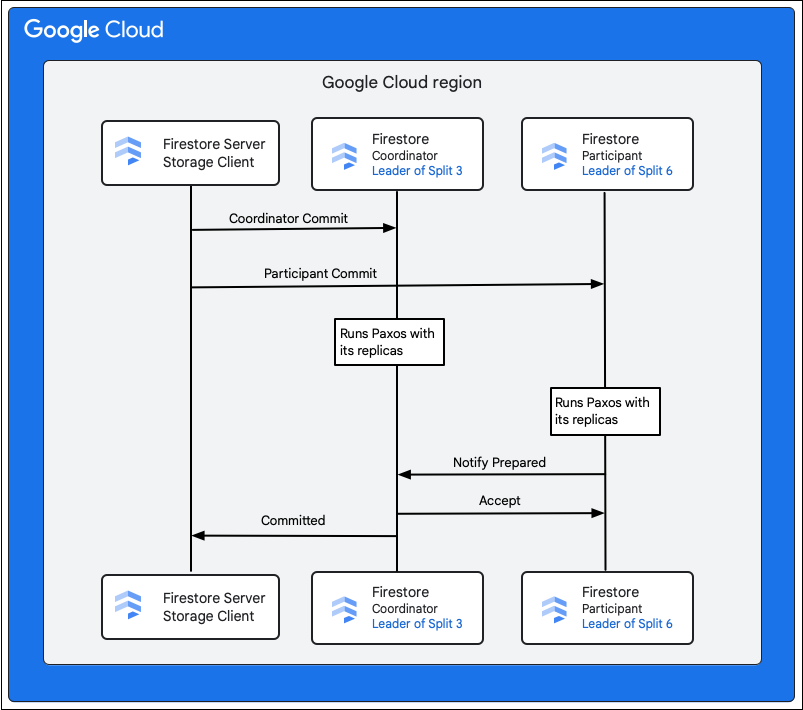
ไคลเอ็นต์พื้นที่เก็บข้อมูลในบริการ Cloud Firestore จะค้นหาการแยกที่เป็นเจ้าของคีย์ของแถวที่จะเปลี่ยนแปลง ลองพิจารณากรณีที่ Split 3 แสดงโฆษณา M1 และ Split 6 แสดงโฆษณา M2-M5 มีธุรกรรมแบบกระจายที่เกี่ยวข้องกับการแยกรายได้ทั้งหมดเหล่านี้ในฐานะผู้เข้าร่วม การแยกพาร์ติชันของผู้เข้าร่วมอาจรวมถึงการแยกพาร์ติชันอื่นๆ ที่มีการอ่านข้อมูลก่อนหน้านี้เป็นส่วนหนึ่งของธุรกรรมการอ่านและเขียนด้วย
ขั้นตอนต่อไปนี้จะอธิบายสิ่งที่เกิดขึ้นในกระบวนการคอมมิต
- ไคลเอ็นต์ที่เก็บข้อมูลจะออกคำสั่งคอมมิต การคอมมิตมีการเปลี่ยนแปลง M1-M5
- โดยการแยกที่ 3 และ 6 คือผู้เข้าร่วมในธุรกรรมนี้ ระบบจะเลือกผู้เข้าร่วมคนใดคนหนึ่งเป็นผู้ประสานงาน เช่น Split 3 หน้าที่ของผู้ประสานงานคือการตรวจสอบว่าธุรกรรมจะคอมมิตหรือยกเลิกแบบอะตอมมิกในผู้เข้าร่วมทั้งหมด
- รีพลิกาผู้นำของการแยกเหล่านี้มีหน้าที่รับผิดชอบต่องานที่ผู้เข้าร่วมและผู้ประสานงานทำ
- ผู้เข้าร่วมและผู้ประสานงานแต่ละคนจะเรียกใช้อัลกอริทึม Paxos กับสำเนาที่เกี่ยวข้อง
- ลีดเดอร์จะเรียกใช้อัลกอริทึม Paxos กับรีพลิก้า จะถือว่ามีจำนวนขั้นต่ำหากสำเนาส่วนใหญ่ตอบกลับผู้นำด้วยการตอบกลับ
ok to commit - จากนั้นผู้เข้าร่วมแต่ละคนจะแจ้งให้ผู้ประสานงานทราบเมื่อพร้อม (เฟสแรกของการคอมมิตแบบ 2 เฟส) หากผู้เข้าร่วมทำธุรกรรมไม่ได้ ธุรกรรมทั้งหมดจะ
aborts
- ลีดเดอร์จะเรียกใช้อัลกอริทึม Paxos กับรีพลิก้า จะถือว่ามีจำนวนขั้นต่ำหากสำเนาส่วนใหญ่ตอบกลับผู้นำด้วยการตอบกลับ
- เมื่อผู้ประสานงานทราบว่าผู้เข้าร่วมทั้งหมดรวมถึงตัวผู้ประสานงานเองพร้อมแล้ว ผู้ประสานงานจะแจ้ง
acceptผลลัพธ์ของธุรกรรมให้ผู้เข้าร่วมทั้งหมดทราบ (ระยะที่ 2 ของการคอมมิตแบบ 2 เฟส) ในขั้นตอนนี้ ผู้เข้าร่วมแต่ละรายจะบันทึกการตัดสินใจคอมมิตลงในที่เก็บข้อมูลที่เสถียรและคอมมิตธุรกรรม - โดยผู้ประสานงานจะตอบกลับไคลเอ็นต์พื้นที่เก็บข้อมูลใน Cloud Firestore ว่าธุรกรรมได้รับการยืนยันแล้ว ในขณะเดียวกัน ผู้ประสานงานและผู้เข้าร่วมทั้งหมดจะใช้การเปลี่ยนแปลงกับข้อมูล
เมื่อCloud Firestoreฐานข้อมูลมีขนาดเล็ก อาจเกิดกรณีที่การแยกรายการเดียวเป็นเจ้าของคีย์ทั้งหมดในการเปลี่ยนแปลง M1-M5 ในกรณีดังกล่าว จะมีผู้เข้าร่วมในธุรกรรมเพียงรายเดียว และไม่จำเป็นต้องใช้การคอมมิต 2 เฟสที่กล่าวถึงก่อนหน้านี้ จึงทำให้การเขียนเร็วขึ้น
การเขียนในหลายภูมิภาค
ในการติดตั้งใช้งานแบบหลายภูมิภาค การกระจายรีพลิคาในภูมิภาคต่างๆ จะเพิ่มความพร้อมใช้งาน แต่ก็มีค่าใช้จ่ายด้านประสิทธิภาพ การสื่อสารระหว่างรีพลิกาในภูมิภาคต่างๆ จะใช้เวลาในการรับส่งนานกว่า ดังนั้น เวลาในการตอบสนองพื้นฐานสำหรับCloud Firestoreจึงสูงกว่าการติดตั้งใช้งานในภูมิภาคเดียวเล็กน้อย
เรากำหนดค่ารีพลิกาในลักษณะที่การเป็นผู้นำสำหรับการแยกจะอยู่ในภูมิภาคหลักเสมอ ภูมิภาคหลักคือภูมิภาคที่การเข้าชมเข้ามายังCloud Firestoreเซิร์ฟเวอร์ การตัดสินใจของผู้นำนี้ช่วยลดเวลาในการตอบสนองไป-กลับในการสื่อสารระหว่างไคลเอ็นต์พื้นที่เก็บข้อมูลใน Cloud Firestore กับผู้นำแบบจำลอง (หรือผู้ประสานงานสำหรับการทำธุรกรรมแบบหลายส่วน)
การเขียนแต่ละครั้งใน Cloud Firestore ยังเกี่ยวข้องกับการโต้ตอบกับเครื่องมือแบบเรียลไทม์ใน Cloud Firestore ด้วย ดูข้อมูลเพิ่มเติมเกี่ยวกับคำค้นหาแบบเรียลไทม์ได้ที่ทําความเข้าใจคําค้นหาแบบเรียลไทม์ที่ปรับขนาดได้
ทำความเข้าใจวงจรการอ่านใน Cloud Firestore
ส่วนนี้จะเจาะลึกการอ่านแบบสแตนด์อโลนที่ไม่ใช่แบบเรียลไทม์ใน Cloud Firestore ภายใน Cloud Firestore เซิร์ฟเวอร์จะจัดการคำค้นหาส่วนใหญ่เหล่านี้ใน 2 ขั้นตอนหลัก ดังนี้
- การสแกนช่วงเดียวในตารางดัชนี
- ค้นหาจุดในตารางเอกสารตามผลการสแกนก่อนหน้า
การอ่านข้อมูลจากเลเยอร์พื้นที่เก็บข้อมูลจะดำเนินการภายในโดยใช้ธุรกรรมฐานข้อมูลเพื่อให้มั่นใจว่าการอ่านจะสอดคล้องกัน อย่างไรก็ตาม ธุรกรรมเหล่านี้จะไม่ใช้การล็อก ซึ่งแตกต่างจากธุรกรรมที่ใช้สำหรับการเขียน แต่จะทำงานโดยการเลือกการประทับเวลา แล้วดำเนินการอ่านทั้งหมดที่การประทับเวลานั้น เนื่องจากไม่ได้ใช้การล็อก จึงไม่บล็อกธุรกรรมการอ่าน-เขียนพร้อมกัน หากต้องการดำเนินการธุรกรรมนี้ ไคลเอ็นต์พื้นที่เก็บข้อมูลใน Cloud Firestore จะระบุขอบเขตการประทับเวลา ซึ่งจะบอกเลเยอร์พื้นที่เก็บข้อมูลถึงวิธีเลือกการประทับเวลาการอ่าน ประเภทการประทับเวลาที่ผูกไว้ซึ่งไคลเอ็นต์พื้นที่เก็บข้อมูลเลือกใน Cloud Firestore จะกำหนดโดยตัวเลือกการอ่านสำหรับคำขออ่าน
ทําความเข้าใจธุรกรรมการอ่านในเลเยอร์พื้นที่เก็บข้อมูล
ส่วนนี้จะอธิบายประเภทการอ่านและวิธีประมวลผลในเลเยอร์พื้นที่เก็บข้อมูลใน Cloud Firestore
การอ่านที่แข็งแกร่ง
โดยค่าเริ่มต้น การอ่าน Cloud Firestore จะสอดคล้องกันอย่างยิ่ง ความสอดคล้องที่เข้มงวดนี้หมายความว่าการอ่าน Cloud Firestore จะแสดงข้อมูลเวอร์ชันล่าสุดที่แสดงถึงการเขียนทั้งหมดที่ได้รับการคอมมิตจนถึงจุดเริ่มต้นของการอ่าน
การอ่านแบบแยกเดี่ยว
ไคลเอ็นต์พื้นที่เก็บข้อมูลใน Cloud Firestore จะค้นหาส่วนที่เป็นเจ้าของคีย์ของแถวที่จะอ่าน สมมติว่าต้องอ่านจาก Split 3 จากส่วนก่อนหน้า ไคลเอ็นต์จะส่งคำขออ่านไปยังรีพลิการายการที่ใกล้ที่สุดเพื่อลดเวลาในการตอบสนองแบบไปกลับ
ในขั้นตอนนี้ อาจเกิดกรณีต่อไปนี้ขึ้นอยู่กับรีเพล็กซ์ที่เลือก
- คำขออ่านจะไปที่รีพลิการะดับผู้นำ (โซน A)
- เนื่องจากผู้นำจะอัปเดตอยู่เสมอ การอ่านจึงดำเนินการต่อได้โดยตรง
- คำขออ่านจะไปที่รีเพล็กซ์ที่ไม่ใช่ผู้นำ (เช่น โซน B)
- Split 3 อาจทราบจากสถานะภายในว่ามีข้อมูลเพียงพอที่จะแสดงการอ่านและดำเนินการแยก
- Split 3 ไม่แน่ใจว่าได้เห็นข้อมูลล่าสุดหรือไม่ โดยจะส่งข้อความไปยังลีดเดอร์เพื่อขอการประทับเวลาของธุรกรรมสุดท้ายที่ต้องใช้เพื่อแสดงผลการอ่าน เมื่อระบบใช้ธุรกรรมดังกล่าวแล้ว การอ่านจะดำเนินการต่อได้
Cloud Firestore จากนั้นจะส่งคำตอบกลับไปยังไคลเอ็นต์
การอ่านแบบหลายส่วน
ในกรณีที่ต้องอ่านจากหลายส่วน กลไกเดียวกันนี้จะเกิดขึ้นในทุกส่วน เมื่อระบบส่งคืนข้อมูลจากทุกการแยกแล้ว ไคลเอ็นต์พื้นที่เก็บข้อมูลใน Cloud Firestore จะรวมผลลัพธ์ Cloud Firestore จากนั้นจะตอบกลับไคลเอ็นต์ด้วยข้อมูลนี้
การอ่านที่ไม่มีอัปเดต
การอ่านที่ชัดเจนเป็นโหมดเริ่มต้นใน Cloud Firestore อย่างไรก็ตาม การดำเนินการนี้อาจทำให้เกิดเวลาในการตอบสนองที่สูงขึ้นเนื่องจากการสื่อสารที่อาจต้องใช้กับลีดเดอร์ บ่อยครั้งที่แอปพลิเคชัน Cloud Firestore ไม่จำเป็นต้องอ่านข้อมูลเวอร์ชันล่าสุด และฟังก์ชันการทำงานก็ทำงานได้ดีกับข้อมูลที่อาจล้าสมัยไปไม่กี่วินาที
ในกรณีเช่นนี้ ไคลเอ็นต์อาจเลือกรับการอ่านที่ล้าสมัยได้โดยใช้read_timeตัวเลือกการอ่าน ในกรณีนี้ การอ่านจะดำเนินการตามข้อมูล ณ read_time และมีแนวโน้มสูงที่รีเพล็ก้าที่ใกล้ที่สุดจะได้รับการยืนยันแล้วว่ามีข้อมูล ณ read_time ที่ระบุ
ค่าความล้าที่เหมาะสมคือ 15 วินาทีเพื่อให้ได้ประสิทธิภาพที่ดีขึ้นอย่างเห็นได้ชัด แม้จะเป็นการอ่านข้อมูลที่ล้าสมัย แถวที่แสดงผลก็ยังสอดคล้องกัน
หลีกเลี่ยงฮอตสปอต
ระบบจะแบ่งการแยกใน Cloud Firestore ออกเป็นส่วนเล็กๆ โดยอัตโนมัติเพื่อกระจายงานในการแสดงผลการเข้าชมไปยังเซิร์ฟเวอร์พื้นที่เก็บข้อมูลเพิ่มเติมเมื่อจำเป็นหรือเมื่อพื้นที่คีย์ขยาย ระบบจะเก็บการแยกที่สร้างขึ้นเพื่อจัดการการเข้าชมที่มากเกินไปไว้ประมาณ 24 ชั่วโมงแม้ว่าการเข้าชมจะหายไปแล้วก็ตาม ดังนั้นหากมีการเข้าชมที่เพิ่มขึ้นซ้ำๆ ระบบจะคงการแยกการเข้าชมไว้และจะเพิ่มการแยกการเข้าชมเมื่อจำเป็น กลไกเหล่านี้ช่วยให้ฐานข้อมูล Cloud Firestore ปรับขนาดอัตโนมัติได้ภายใต้ปริมาณการเข้าชมที่เพิ่มขึ้นหรือขนาดฐานข้อมูลที่เพิ่มขึ้น อย่างไรก็ตาม คุณควรทราบข้อจำกัดบางประการตามที่อธิบายไว้ด้านล่าง
การแยกพื้นที่เก็บข้อมูลและการโหลดต้องใช้เวลา และการเพิ่มการเข้าชมเร็วเกินไปอาจทำให้เกิดข้อผิดพลาดเกี่ยวกับเวลาในการตอบสนองสูงหรือเกินกำหนด ซึ่งมักเรียกว่าฮอตสปอต ขณะที่บริการปรับ แนวทางปฏิบัติแนะนำคือการกระจายการดำเนินการในคีย์ช่วงหลัก ขณะเดียวกันก็เพิ่มการเข้าชมในคอลเล็กชันในฐานข้อมูลที่มีการดำเนินการ 500 รายการต่อวินาที หลังจากเพิ่มขึ้นอย่างค่อยเป็นค่อยไปแล้ว ให้เพิ่มการเข้าชมสูงสุด 50% ทุกๆ 5 นาที กระบวนการนี้เรียกว่ากฎ 500/50/5 และจะจัดตำแหน่งฐานข้อมูลให้ปรับขนาดได้อย่างเหมาะสมเพื่อรองรับปริมาณงาน
แม้ว่าระบบจะสร้างการแยกโดยอัตโนมัติเมื่อโหลดเพิ่มขึ้น แต่ Cloud Firestore จะแยกช่วงคีย์ได้จนกว่าจะแสดงเอกสารเดียวโดยใช้ชุดเซิร์ฟเวอร์จัดเก็บข้อมูลที่จำลองแบบเฉพาะ ด้วยเหตุนี้ การดำเนินการพร้อมกันจำนวนมากและต่อเนื่องในเอกสารเดียวอาจทำให้เกิดฮอตสปอตในเอกสารนั้น หากพบว่าเอกสารเดียวมีเวลาในการตอบสนองสูงอย่างต่อเนื่อง คุณควรพิจารณาแก้ไขโมเดลข้อมูลเพื่อแยกหรือจำลองข้อมูลในเอกสารหลายฉบับ
ข้อผิดพลาดในการแย่งกันเกิดขึ้นเมื่อการดำเนินการหลายอย่างพยายามอ่านและ/หรือเขียนเอกสารเดียวกันพร้อมกัน
อีกกรณีพิเศษของการเกิดฮอตสปอตคือเมื่อใช้คีย์ที่เพิ่มขึ้น/ลดลงตามลำดับเป็นรหัสเอกสารใน Cloud Firestore และมีการดำเนินการต่อวินาทีเป็นจำนวนมาก การสร้างการแยกส่วนเพิ่มเติมไม่ได้ช่วยในกรณีนี้ เนื่องจากปริมาณการเข้าชมที่เพิ่มขึ้นจะย้ายไปที่การแยกส่วนที่สร้างขึ้นใหม่ เนื่องจาก Cloud Firestore จะจัดทำดัชนีช่องทั้งหมดในเอกสารโดยอัตโนมัติโดยค่าเริ่มต้น จึงอาจมีการสร้างฮอตสปอตที่เคลื่อนไหวดังกล่าวในพื้นที่ดัชนีสำหรับช่องเอกสารที่มีค่าเพิ่มขึ้น/ลดลงตามลำดับ เช่น การประทับเวลา
โปรดทราบว่าการปฏิบัติตามแนวทางที่ระบุไว้ข้างต้นจะช่วยให้ Cloud Firestore ปรับขนาดเพื่อรองรับปริมาณงานขนาดใหญ่ได้โดยที่คุณไม่ต้องปรับการกำหนดค่าใดๆ
การแก้ปัญหา
Cloud Firestore มี Key Visualizer เป็นเครื่องมือวินิจฉัยที่ออกแบบมาเพื่อวิเคราะห์รูปแบบการใช้งานและแก้ปัญหาฮอตสปอต
ขั้นตอนถัดไป
- อ่านแนวทางปฏิบัติแนะนำเพิ่มเติม
- ดูข้อมูลเกี่ยวกับการค้นหาแบบเรียลไทม์ที่ปรับขนาดได้