
Consulta este documento que te permitirá tomar decisiones fundamentadas sobre la arquitectura de tus aplicaciones para lograr un alto rendimiento y una alta confiabilidad. En este documento, se incluyen temas avanzados de Cloud Firestore. Si estás comenzando a usar Cloud Firestore, consulta la guía de inicio rápido.
Cloud Firestore es una base de datos flexible y escalable para el desarrollo en servidores, dispositivos móviles y la Web desde Firebase y Google Cloud. Comenzar a usar Cloud Firestore y escribir aplicaciones enriquecidas y potentes es muy fácil.
Para garantizar que tus aplicaciones continúen funcionando bien a medida que el tamaño y el tráfico de tu base de datos aumentan, es útil comprender la mecánica de las operaciones de lectura y escritura en el backend de Cloud Firestore. También debes comprender la interacción entre tus operaciones de lectura y escritura con la capa de almacenamiento y las restricciones subyacentes que pueden afectar el rendimiento.
Consulta las siguientes secciones para conocer las prácticas recomendadas antes de diseñar tu aplicación.
Comprende los componentes de alto nivel
En el siguiente diagrama, se muestran los componentes de alto nivel que participan en una solicitud a la API de Cloud Firestore.
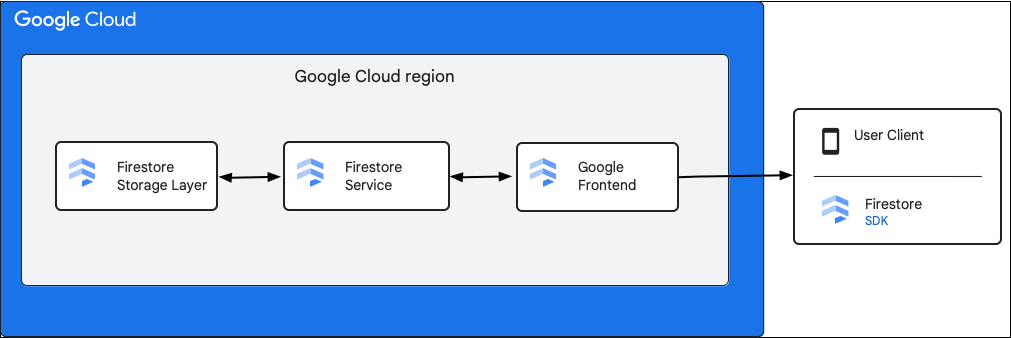
SDK y bibliotecas cliente de Cloud Firestore
Cloud Firestore admite SDK y bibliotecas cliente para diferentes plataformas. Si bien una app puede realizar llamadas de HTTP y RPC directas a la API de Cloud Firestore, las bibliotecas cliente proporcionan una capa de abstracción para simplificar el uso de la API y aplicar prácticas recomendadas. También pueden proporcionar funciones adicionales, como acceso sin conexión, cachés, etcétera.
Google Front End (GFE)
Este es un servicio de infraestructura común entre todos los servicios de Google Cloud. GFE acepta solicitudes entrantes y las reenvía al servicio de Google relevante (en este contexto, el servicio de Cloud Firestore). También proporciona otras funciones importantes, como protección contra ataques de denegación del servicio.
Servicio Cloud Firestore
El servicio de Cloud Firestore realiza verificaciones, como de autenticación, autorización, verificaciones de cuota y reglas de seguridad, en la solicitud a la API, y también administra transacciones. Este servicio de Cloud Firestore incluye un cliente de almacenamiento que interactúa con la capa que almacena las operaciones de lectura y escritura de datos.
Capa de almacenamiento de Cloud Firestore
La capa de almacenamiento de Cloud Firestore se encarga de almacenar los datos y metadatos, así como las funciones asociadas de bases de datos que proporciona Cloud Firestore. En las siguientes secciones, se describe cómo se organizan los datos en la capa de almacenamiento de Cloud Firestore y cómo escala el sistema. Aprender cómo están organizados los datos puede ayudarte a diseñar un modelo escalable y a comprender mejor las prácticas recomendadas en Cloud Firestore.
Rangos y divisiones clave
Cloud Firestore es una base de datos NoSQL orientada a documentos. Los datos se almacenan en documentos, que se organizan en jerarquías de colecciones. La jerarquía de la colección y el ID del documento se traducen a una sola clave para cada documento. Los documentos se almacenan y ordenan de manera lógica y lexicográfica con esta clave única. Usamos el término rango de claves para hacer referencia a un rango de claves lexicográficamente contiguo.
Una base de datos típica de Cloud Firestore es demasiado grande para caber en una sola máquina física. También hay situaciones en las que la carga de trabajo en los datos es demasiado pesada para que una máquina la pueda manejar. Cloud Firestore particiona los datos en secciones independientes que se pueden almacenar y entregar desde múltiples máquinas o servidores de almacenamiento para controlar cargas de trabajo grandes. Estas particiones se realizan en las tablas de la base de datos, en bloques de rangos de claves llamados divisiones.
Replicación síncrona
Es importante tener en cuenta que la base de datos siempre se replica de forma automática y síncrona. Las divisiones de datos tienen réplicas en diferentes zonas para que estén disponibles incluso cuando una zona se vuelve inaccesible. El algoritmo Paxos administra la replicación coherente en las diferentes copias de la división para lograr un consenso. Se elige una réplica de cada división para que actúe como líder de Paxos, cuya responsabilidad consiste en administrar las operaciones de escritura en esa división. La replicación síncrona te permite leer siempre la versión más reciente de los datos de Cloud Firestore.
El resultado general es un sistema escalable y con alta disponibilidad que proporciona latencias bajas para las operaciones de lectura y escritura a gran escala, independientemente de las cargas de trabajo pesadas.
Diseño de datos
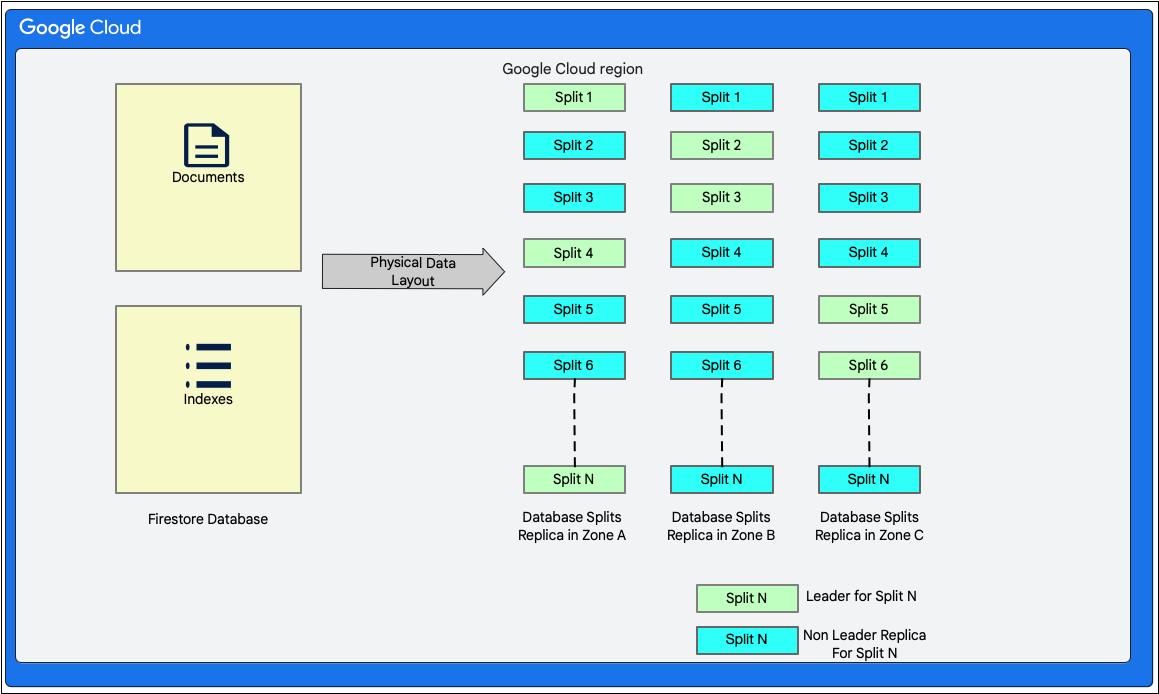
Cloud Firestore es una base de datos de documentos sin esquemas. Sin embargo, de forma interna, dispone los datos principalmente en dos tablas con estilo de base de datos relacional, en su capa de almacenamiento, de la siguiente manera:
- Tabla de documentos: Los documentos se almacenan en esta tabla.
- Tabla de índices: En esta tabla se almacenan las entradas que permiten obtener resultados ordenados por valor de índice de forma eficiente.
En el siguiente diagrama, se muestra cómo se verían las tablas de una base de datos de Cloud Firestore con las divisiones. Las divisiones se replican en tres zonas diferentes y cada una tiene un líder de Paxos asignado.
Región única o multirregión
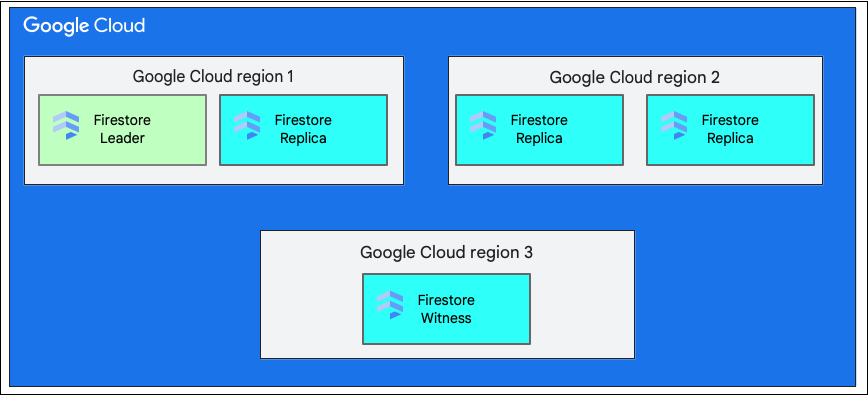
Cuando creas una base de datos, debes seleccionar una región o multirregión.
Una ubicación regional única es una ubicación geográfica específica, como us-west1. Las divisiones de datos de una base de datos de Cloud Firestore tienen réplicas en diferentes zonas dentro de la región seleccionada, como se explicó anteriormente.
Una ubicación multirregional consiste en un conjunto definido de regiones en las que se almacenan réplicas de la base de datos. En una implementación multirregional de Cloud Firestore, dos de las regiones tienen réplicas completas de todos los datos de la base de datos. Una tercera región tiene una réplica testigo que no mantiene un conjunto completo de datos, pero participa en la replicación. Cuando se replican los datos entre múltiples regiones, estos se pueden seguir escribiendo y leyendo, incluso con la pérdida de toda una región.
Para obtener más información sobre las ubicaciones de una región, consulta Ubicaciones de Cloud Firestore.
Comprende el ciclo de vida de una operación de escritura en Cloud Firestore
Para escribir datos, un cliente de Cloud Firestore puede crear, actualizar o borrar un documento. Una operación de escritura en un solo documento requiere de la actualización atómica del documento y sus entradas de índice asociadas en la capa de almacenamiento. Cloud Firestore también admite operaciones atómicas que constan de varias lecturas o escrituras en uno o más documentos.
Para todos los tipos de escrituras, Cloud Firestore proporciona las propiedades ACID (atomicidad, coherencia, aislamiento y durabilidad) de las bases de datos relacionales. Cloud Firestore también proporciona serialización, lo que significa que todas las transacciones aparecen como si se ejecutaran en serie.
Pasos de alto nivel en una transacción de escritura
Cuando el cliente de Cloud Firestore envía una operación de escritura o confirma una transacción, a través de cualquiera de los métodos mencionados, esta se ejecuta de forma interna como una transacción de operaciones de lectura y escritura de la base de datos en la capa de almacenamiento. La transacción permite que Cloud Firestore proporcione las propiedades ACID mencionadas antes.
En el primer paso de una transacción, Cloud Firestore lee el documento existente y determina las mutaciones que se deben realizar a los datos en la tabla Documentos.
Esto también incluye realizar las actualizaciones necesarias en la tabla Índices de la siguiente manera:
- Los campos que se agregan a los documentos necesitan las inserciones correspondientes en la tabla Índices.
- Los campos que se quitan de los documentos necesitan las eliminaciones correspondientes en la tabla Índices.
- Los campos que se modifican en los documentos necesitan eliminaciones (para valores anteriores), así como inserciones (para valores nuevos) en la tabla Índices.
Para calcular las mutaciones que se mencionaron antes, Cloud Firestore lee la configuración de indexación del proyecto. Esta configuración almacena información sobre los índices de un proyecto. Cloud Firestore usa dos tipos de índices: los de campo único y los compuestos. Para obtener información detallada sobre los índices creados en Cloud Firestore, consulta Tipos de índices en Cloud Firestore.
Una vez que se calculan las mutaciones, Cloud Firestore las recopila dentro de una transacción y, luego, las confirma.
Comprende una transacción de escritura en la capa de almacenamiento
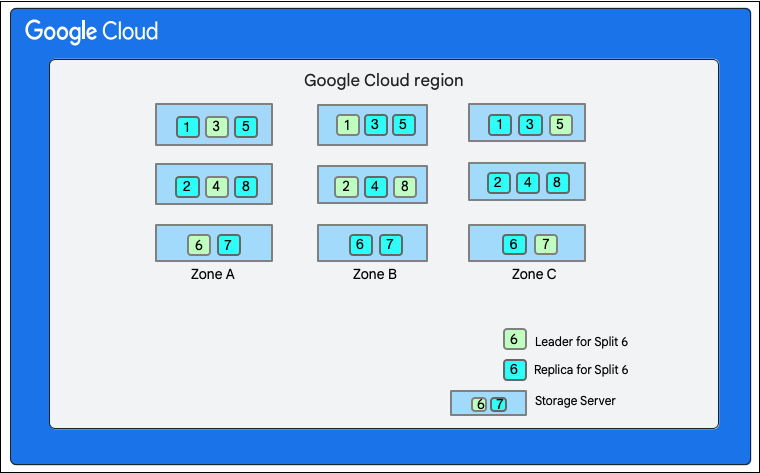
Como se mencionó antes, una operación de escritura en Cloud Firestore implica una transacción de operaciones de lectura y escritura en la capa de almacenamiento. Según el diseño de los datos, una operación de escritura puede implicar una o más divisiones, como se ve en el diseño de datos.
En el siguiente diagrama, la base de datos de Cloud Firestore tiene ocho divisiones (marcadas del 1 al 8) alojadas en tres servidores de almacenamiento diferentes dentro de una sola zona y cada una se replica en 3 o más zonas. ada división se replica en 3 o más zonas y tiene un líder de Paxos, que puede estar en una zona diferente para distintas divisiones.
 Cloud Firestore database split">
Cloud Firestore database split">
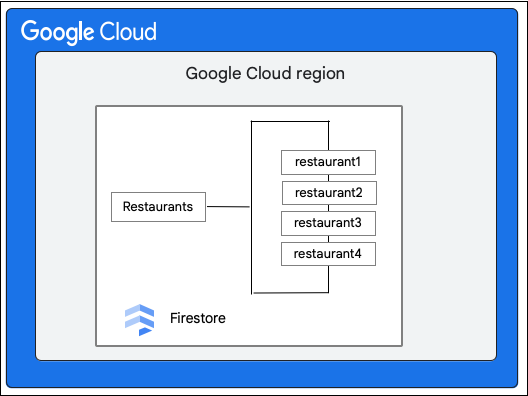
Considera una base de datos de Cloud Firestore que tiene la colección Restaurants de la siguiente manera:
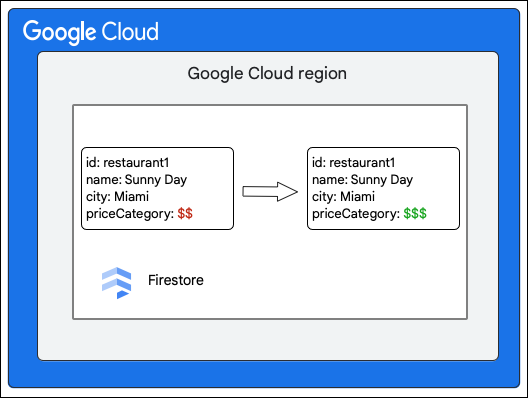
El cliente de Cloud Firestore solicita el siguiente cambio para un documento de la colección Restaurant mediante la actualización del valor del campo priceCategory.
Los siguientes pasos de alto nivel describen lo que sucede como parte de la operación de escritura:
- Crea una transacción de lectura y escritura.
- Lee el documento
restaurant1de la colecciónRestaurantsque aparece en la tabla Documentos de la capa de almacenamiento. - Lee los índices del documento de la tabla Índices.
- Calcula las mutaciones que se realizarán en los datos. En este caso, hay cinco mutaciones:
- M1: Actualiza la fila de
restaurant1en la tabla Documentos para reflejar el cambio en el valor del campopriceCategory. - M2 y M3: Borran las filas del valor anterior de
priceCategoryen la tabla Índices para los índices ascendentes y descendentes. - M4 y M5: Insertan las filas del valor nuevo de
priceCategoryen la tabla Índices para los índices ascendentes y descendentes.
- M1: Actualiza la fila de
- Confirma estas mutaciones.
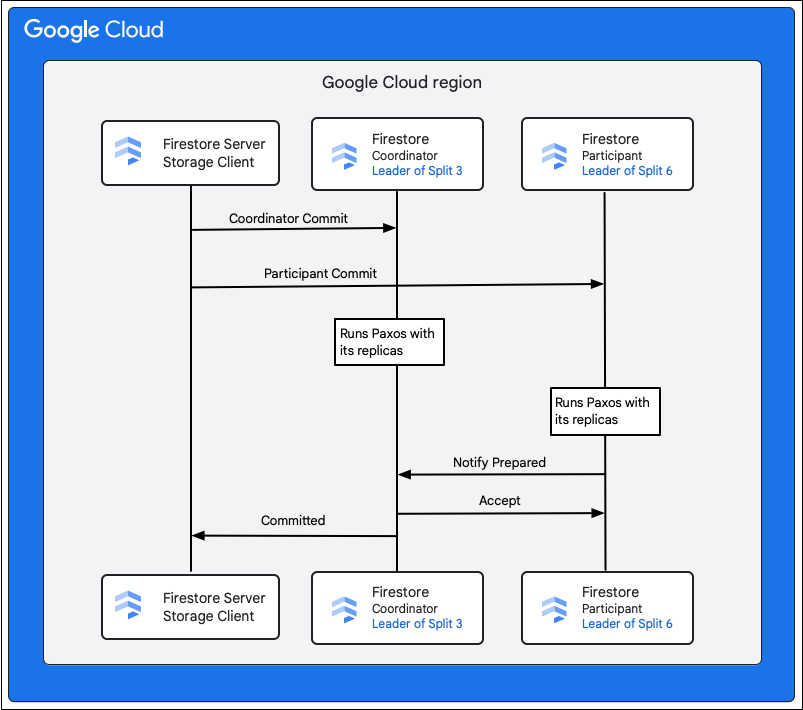
El cliente de almacenamiento en el servicio de Cloud Firestore busca las divisiones que poseen las claves de las filas que se cambiarán. Consideremos un caso en el que la División 3 entrega la M1 y la División 6 entrega de la M2 a la M5. De esta forma, se genera una transacción distribuida que incluye todas estas divisiones como participantes. Las divisiones de los participantes también pueden incluir cualquier otra división de la que se hayan leído datos anteriormente como parte de la transacción de lectura y escritura.
En los siguientes pasos, se describe lo que sucede como parte de la confirmación:
- El cliente de almacenamiento emite una confirmación. La confirmación contiene mutaciones de la M1 a la M5.
- Las divisiones 3 y 6 son los participantes de esta transacción. Se elige a uno de los participantes como el coordinador, como en la División 3. El trabajo del coordinador consiste en asegurarse de que la transacción se confirme o se anule de forma automática en todos los participantes.
- Las réplicas líderes de estas divisiones son responsables del trabajo que realizan los participantes y coordinadores.
- Cada participante y coordinador ejecuta un algoritmo Paxos con sus respectivas réplicas.
- El líder ejecuta un algoritmo Paxos con las réplicas. El quórum se logra si la mayoría de las réplicas responden con una respuesta
ok to commital líder. - Luego, cada participante notifica al coordinador cuando esté preparado (primera fase de la confirmación en dos fases). Si algún participante no puede confirmar la transacción, se anula toda la transacción (
aborts).
- El líder ejecuta un algoritmo Paxos con las réplicas. El quórum se logra si la mayoría de las réplicas responden con una respuesta
- Una vez que el coordinador conoce a todos los participantes, incluido él mismo, está preparado para comunicar el resultado de la transacción de
accepta todos los participantes (segunda fase de la confirmación en dos fases). En esta fase, cada participante registra la decisión de confirmación en un almacenamiento estable para confirmarla. - El coordinador responde al cliente de almacenamiento en Cloud Firestore que se confirmó la transacción. Al mismo tiempo, el coordinador y todos los participantes aplican las mutaciones a los datos.
Cuando la base de datos de Cloud Firestore es pequeña, puede suceder que una sola división posea todas las claves de las mutaciones M1 a la M5. En ese caso, solo hay un participante en la transacción y no se requiere la confirmación en dos fases mencionada anteriormente, por lo que las operaciones de escritura se agilizan.
Operaciones de escritura multirregionales
En una implementación multirregional, la distribución de réplicas entre regiones aumenta la disponibilidad, aunque esto conlleva un costo de rendimiento. La comunicación entre réplicas en diferentes regiones ralentiza más los tiempos de ida y vuelta. Por lo tanto, la latencia del modelo de referencia para las operaciones de Cloud Firestore es ligeramente mayor en comparación con las implementaciones de una sola región.
Configuramos las réplicas de modo que el liderazgo de las divisiones siempre permanezca en la región principal. La región principal es la que recibe tráfico del servidor de Cloud Firestore. Esta decisión de liderazgo reduce el retraso de ida y vuelta en la comunicación entre el cliente de almacenamiento en Cloud Firestore y el líder de réplica (o coordinador de las transacciones de división múltiple).
Cada operación de escritura en Cloud Firestore también implica alguna interacción con el motor en tiempo real en Cloud Firestore. Para obtener más información sobre las consultas en tiempo real, consulta Comprende las consultas en tiempo real a gran escala.
Comprende el ciclo de vida de una operación de lectura en Cloud Firestore
En esta sección, se profundiza en las operaciones de lectura independientes que no se ejecutan en tiempo real de Cloud Firestore. De forma interna, el servidor de Cloud Firestore controla la mayoría de estas consultas en dos etapas principales:
- Un único análisis de rango en la tabla Índices
- Búsquedas de puntos en la tabla Documentos basadas en el resultado del análisis anterior
Las operaciones de lectura de datos de la capa de almacenamiento se realizan internamente mediante una transacción de base de datos para garantizar lecturas coherentes. Sin embargo, a diferencia de las transacciones que se usan para las operaciones de escritura, estas no aceptan bloqueos. En su lugar, funcionan eligiendo una marca de tiempo y, luego, ejecutando todas las lecturas en esa marca de tiempo. Dado que no adquieren bloqueos, no bloquean las transacciones simultáneas de lectura y escritura. Para ejecutar esta transacción, el cliente de almacenamiento en Cloud Firestore especifica un límite de marca de tiempo que le indica a la capa de almacenamiento cómo elegir una marca de tiempo de lectura. El tipo de límite de marca de tiempo que elige el cliente de almacenamiento en Cloud Firestore se determina mediante las opciones de lectura para la solicitud de lectura.
Comprende una transacción de lectura en la capa de almacenamiento
En esta sección, se describen los tipos de lecturas y cómo se procesan en la capa de almacenamiento en Cloud Firestore.
Operaciones de lectura sólidas
De forma predeterminada, las lecturas de Cloud Firestore tienen una coherencia sólida. Esta coherencia sólida significa que una operación de lectura de Cloud Firestore muestra la versión más reciente de los datos que reflejan todas las operaciones de escritura confirmadas antes del inicio de la operación de lectura.
Operaciones de lectura única divididas
El cliente de almacenamiento en Cloud Firestore busca las divisiones que poseen las claves de las filas que se leerán. Supongamos que necesitas ejecutar una operación de lectura de la División 3 de la sección anterior. El cliente envía la solicitud de lectura a la réplica más cercana para reducir la latencia de ida y vuelta.
En este punto, pueden ocurrir los siguientes casos según la réplica elegida:
- La solicitud de lectura se dirige a una réplica líder (Zona A).
- Dado que el líder está siempre actualizado, la operación de lectura puede continuar directamente.
- La solicitud de lectura se dirige a una réplica no líder (como la zona B).
- Debido al estado interno de la división 3, se puede saber que contiene suficiente información para entregar la operación de lectura, y así lo hace.
- La División 3 no está segura de haber visto los datos más recientes. Le envía un mensaje al líder solicitando la marca de tiempo de la última transacción que debe aplicar para entregar la lectura. Una vez que se aplica la transacción, la operación de lectura puede continuar.
Luego, Cloud Firestore muestra la respuesta a su cliente.
Operaciones de lectura de división múltiple
En caso de que las operaciones de lectura se deban realizar desde varias divisiones, se produce el mismo mecanismo en todas ellas. Una vez que se muestran los datos de todas las divisiones, el cliente de almacenamiento de Cloud Firestore combina los resultados. Luego, Cloud Firestore responde a su cliente con estos datos.
Operaciones de lectura inactivas
Las operaciones de lectura sólidas son la opción predeterminada en Cloud Firestore. Sin embargo, tiene un costo potencial de latencia mayor debido a la comunicación que podría requerir el líder. A menudo, tu aplicación de Cloud Firestore no necesita leer la versión más reciente de los datos, y la función opera bien con datos que podrían estar inactivos durante unos segundos.
En ese caso, el cliente puede optar por recibir operaciones de lectura inactivas mediante las opciones de lectura de read_time. En este caso, las operaciones de lectura se realizan porque los datos estaban en read_time, y es probable que la réplica más cercana ya haya verificado que tiene datos en el read_time especificado.
Para obtener un rendimiento notablemente mejor, 15 segundos es un valor de inactividad razonable. Incluso para las lecturas inactivas, las filas generadas son coherentes entre sí.
Evita los hotspots
Las divisiones en Cloud Firestore se separan automáticamente en partes más pequeñas de modo que puedan distribuir el trabajo de entregar tráfico a más servidores de almacenamiento cuando sea necesario o cuando se expande el espacio de claves. Las divisiones creadas para manejar el exceso de tráfico se retienen durante aproximadamente 24 horas, incluso si el tráfico desaparece. Por lo tanto, si hay aumentos repentinos de tráfico recurrentes, se mantienen las divisiones y se agregan más divisiones siempre que sea necesario. Estos mecanismos ayudan a las bases de datos de Cloud Firestore a escalar automáticamente cuando se aumenta la carga de tráfico o el tamaño de la base de datos. Sin embargo, existen algunas limitaciones que se deben tener en cuenta, como se explica a continuación.
Dividir el almacenamiento y la carga lleva tiempo, y aumentar el tráfico demasiado rápido puede causar errores de latencia alta o errores de vencimiento excedido, lo que comúnmente se conoce como hotspots, mientras se ajusta el servicio. La práctica recomendada es distribuir las operaciones dentro del rango de claves, mientras se aumenta el tráfico en una colección, dentro de una base de datos con 500 operaciones por segundo. Después de este aumento gradual, aumenta el tráfico hasta un 50% cada cinco minutos. Este proceso se denomina regla 500/50/5 y posiciona la base de datos para ajustar la escala de manera óptima para satisfacer sus cargas de trabajo.
Aunque las divisiones se crean automáticamente a medida que crece la carga, es posible que Cloud Firestore divida un rango de claves solo hasta que entregue un solo documento con un conjunto exclusivo de servidores de almacenamiento replicado. Como resultado, los volúmenes altos y constantes de las operaciones simultáneas en un solo documento pueden llevar a un hotspot en ese documento. Si encuentras latencias altas constantes en un documento, puedes modificar el modelo de datos para dividir o replicar los datos en múltiples documentos.
Los errores de contención se producen cuando múltiples operaciones intentan realizar operaciones de lectura o escritura en el mismo documento de forma simultánea.
Otro caso especial de generación de hotspots ocurre cuando se usa una clave que aumenta o disminuye de forma secuencial se usa como ID de documento en Cloud Firestore y se genera una cantidad considerablemente alta de operaciones por segundo. Crear más divisiones no es útil en este caso, ya que el aumento de tráfico simplemente se traslada a la división recién creada. Dado que Cloud Firestore indexa automáticamente todos los campos del documento de forma predeterminada, es posible que se creen hotspots en movimiento en el espacio de índice de un campo de documento que contiene un valor que aumenta o disminuye secuencialmente, como una marca de tiempo.
Ten en cuenta que, si sigues las prácticas descritas anteriormente, Cloud Firestore se puede escalar para entregar cargas de trabajo arbitrariamente grandes sin que tengas que ajustar ninguna configuración.
Soluciona problemas
Cloud Firestore proporciona Key Visualizer como una herramienta de diagnóstico diseñada para analizar patrones de uso y solucionar problemas de generación de hotspots.
Pasos siguientes
- Obtén más información sobre las prácticas recomendadas.
- Obtén información sobre las consultas en tiempo real a gran escala.