
Przeczytaj ten dokument, aby podejmować świadome decyzje dotyczące projektowania aplikacji pod kątem wysokiej wydajności i niezawodności. Ten dokument zawiera zaawansowane tematy dotyczące Cloud Firestore. Jeśli dopiero zaczynasz korzystać z Cloud Firestore, zapoznaj się z krótkim przewodnikiem.
Cloud Firestore to elastyczna i skalowalna baza danych do tworzenia aplikacji mobilnych, internetowych i serwerowych od Firebase i Google Cloud. Rozpoczęcie pracy z Cloud Firestore i tworzenie zaawansowanych aplikacji jest bardzo proste.
Aby mieć pewność, że aplikacje będą działać prawidłowo wraz ze wzrostem rozmiaru bazy danych i ruchu, warto poznać mechanizmy odczytu i zapisu w Cloud Firestorebackendzie. Musisz też rozumieć interakcje odczytu i zapisu z warstwą pamięci oraz ograniczenia, które mogą wpływać na wydajność.
Zanim zaprojektujesz aplikację, zapoznaj się ze sprawdzonymi metodami w poniższych sekcjach.
Poznaj komponenty wysokiego poziomu
Na diagramie poniżej widać komponenty najwyższego poziomu biorące udział w żądaniu do interfejsu Cloud Firestore API.
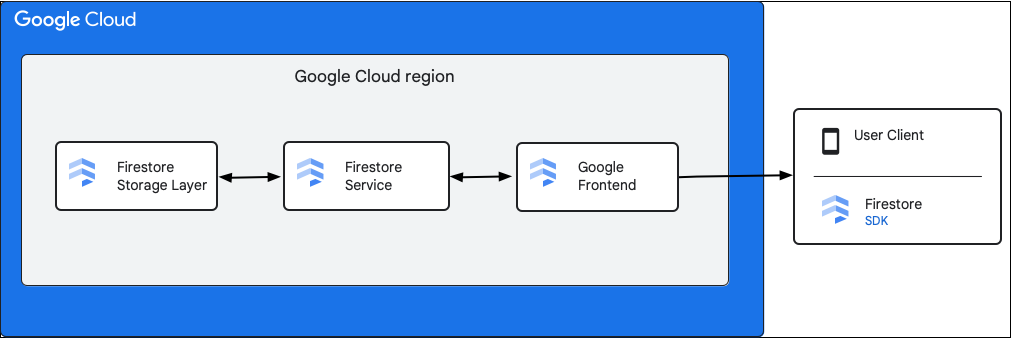
Cloud Firestore Pakiety SDK i biblioteki klienta
Cloud Firestore obsługuje pakiety SDK i biblioteki klienta na różnych platformach. Aplikacja może wykonywać bezpośrednie wywołania HTTP i RPC do interfejsu Cloud Firestore API, ale biblioteki klienta zapewniają warstwę abstrakcji, która upraszcza korzystanie z interfejsu API i wdrażanie sprawdzonych metod. Mogą też udostępniać dodatkowe funkcje, takie jak dostęp offline, pamięć podręczna itp.
Google Front End (GFE)
Jest to usługa infrastruktury wspólna dla wszystkich usług Google Cloud. GFE akceptuje przychodzące żądania i przekazuje je do odpowiedniej usługi Google (w tym przypadku do usługi Cloud Firestore). Zapewnia też inne ważne funkcje, w tym ochronę przed atakami typu DoS.
Usługa Cloud Firestore
Usługa Cloud Firestore przeprowadza kontrole żądania do interfejsu API, w tym uwierzytelnianie, autoryzację, sprawdzanie limitów i reguł bezpieczeństwa, a także zarządza transakcjami. Ta usługa Cloud Firestore obejmuje klienta pamięci, który wchodzi w interakcję z warstwą pamięci w celu odczytywania i zapisywania danych.
Cloud Firestore warstwa pamięci
Warstwa pamięci Cloud Firestore odpowiada za przechowywanie danych i metadanych oraz powiązanych funkcji bazy danych udostępnianych przez Cloud Firestore. W sekcjach poniżej opisujemy, jak dane są uporządkowane w warstwie pamięci Cloud Firestore i jak system skaluje się. Informacje o tym, jak są zorganizowane dane, mogą pomóc w zaprojektowaniu skalowalnego modelu danych i lepszym zrozumieniu sprawdzonych metod w Cloud Firestore.
Zakresy kluczy i podziały
Cloud Firestore to baza danych NoSQL zorientowana na dokumenty. Dane są przechowywane w dokumentach, które są uporządkowane w hierarchie kolekcji. Hierarchia kolekcji i identyfikator dokumentu są tłumaczone na jeden klucz dla każdego dokumentu. Dokumenty są przechowywane logicznie i porządkowane leksykograficznie według tego pojedynczego klucza. Terminu „zakres kluczy” używamy w odniesieniu do leksykograficznie ciągłego zakresu kluczy.
Typowa Cloud Firestore baza danych jest zbyt duża, aby zmieścić się na jednym komputerze fizycznym. Istnieją też scenariusze, w których obciążenie danych jest zbyt duże, aby jedna maszyna mogła sobie z nim poradzić. Aby obsługiwać duże obciążenia, Cloud Firestore dzieli dane na osobne części, które można przechowywać i udostępniać na wielu maszynach lub serwerach pamięci. Partycje są tworzone w tabelach bazy danych w blokach zakresów kluczy zwanych podziałami.
Replikacja synchroniczna
Warto pamiętać, że baza danych jest zawsze replikowana automatycznie i synchronicznie. Podziały danych mają repliki w różnych strefach, dzięki czemu są dostępne nawet wtedy, gdy strefa staje się niedostępna. Spójną replikacją do różnych kopii podziału zarządza algorytm Paxos, który zapewnia konsensus. Jedna replika każdego podziału jest wybierana jako lider protokołu Paxos, który odpowiada za obsługę zapisów w tym podziale. Replikacja synchroniczna umożliwia odczytywanie najnowszej wersji danych z Cloud Firestore.
W rezultacie otrzymujemy skalowalny i wysoce dostępny system, który zapewnia krótkie czasy oczekiwania zarówno w przypadku odczytu, jak i zapisu, niezależnie od dużych obciążeń i w bardzo dużej skali.
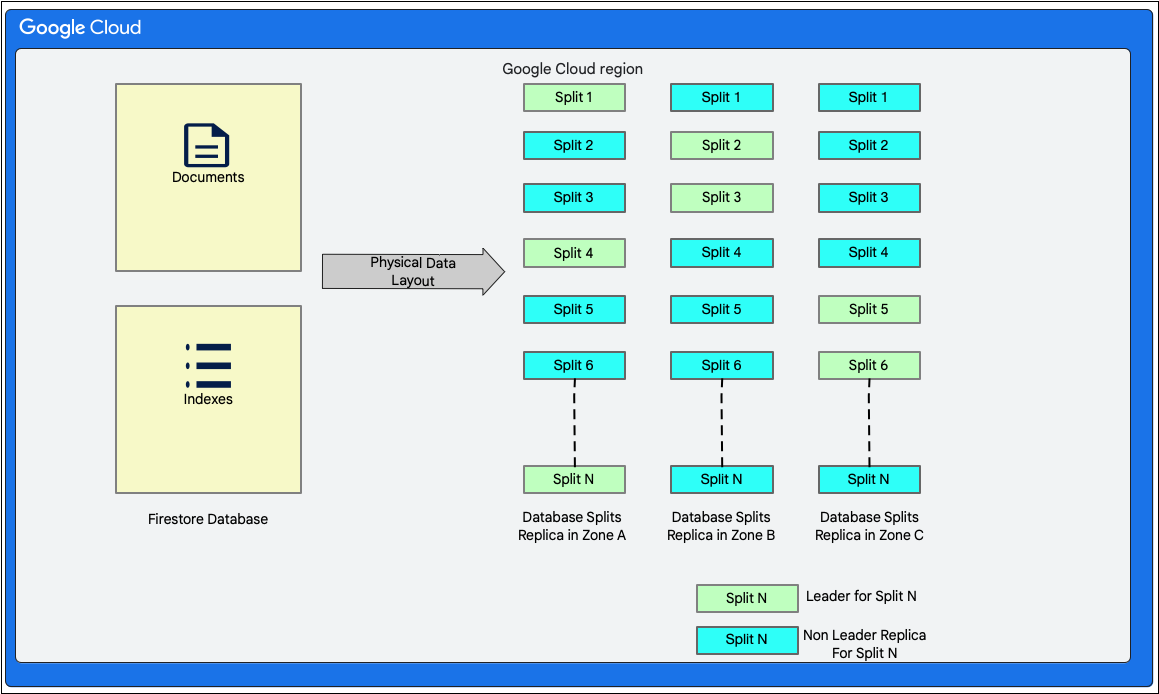
Układ danych
Cloud Firestore to baza danych dokumentów bez schematu. Wewnętrznie jednak dane są układane głównie w 2 tabelach w stylu relacyjnej bazy danych w warstwie pamięci masowej w ten sposób:
- Tabela Documents: dokumenty są przechowywane w tej tabeli.
- Tabela Indeksy: zawiera wpisy indeksu, które umożliwiają wydajne uzyskiwanie wyników posortowanych według wartości indeksu.
Ten diagram pokazuje, jak mogą wyglądać tabele w Cloud Firestore bazie danych po podziale. Podziały są replikowane w 3 różnych strefach, a każdy z nich ma przypisanego lidera protokołu Paxos.
Jeden region a wiele regionów
Podczas tworzenia bazy danych musisz wybrać region lub wiele regionów.
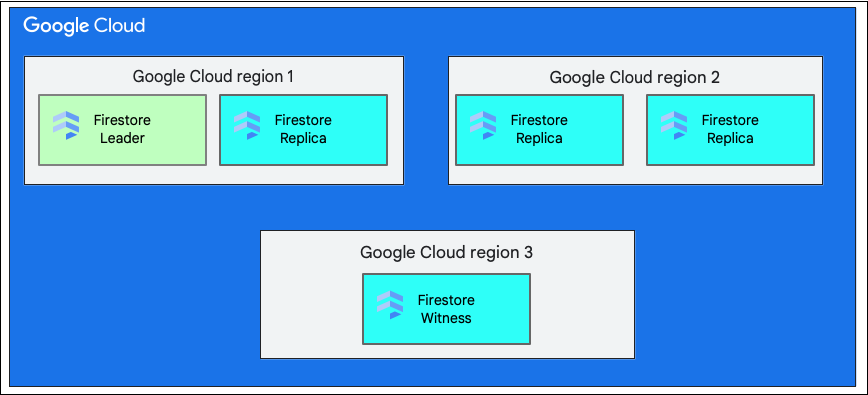
Pojedyncza lokalizacja regionalna to konkretna lokalizacja geograficzna, np. us-west1. Podziały danych w bazie danych Cloud Firestore mają repliki w różnych strefach w wybranym regionie, jak wyjaśniliśmy wcześniej.
Lokalizacja obejmująca wiele regionów składa się z określonego zestawu regionów, w których są przechowywane repliki bazy danych. W przypadku wdrożenia Cloud Firestore obejmującego wiele regionów 2 regiony mają pełne repliki wszystkich danych w bazie danych. W trzecim regionie znajduje się replika pomocnicza, która nie przechowuje pełnego zestawu danych, ale uczestniczy w replikacji. Dzięki replikacji danych w wielu regionach dane są dostępne do zapisu i odczytu nawet w przypadku utraty całego regionu.
Więcej informacji o lokalizacjach w regionie znajdziesz w artykule Cloud Firestorelokalizacje.
Okres ważności głosu oddanego na kandydata, którego nazwiska nie ma na liście Cloud Firestore
Klient Cloud Firestore może zapisywać dane, tworząc, aktualizując lub usuwając pojedynczy dokument. Zapis do pojedynczego dokumentu wymaga atomowego zaktualizowania zarówno dokumentu, jak i powiązanych z nim wpisów indeksu w warstwie pamięci. Cloud Firestore obsługuje też operacje niepodzielne składające się z wielu odczytów lub zapisów w co najmniej jednym dokumencie.
W przypadku wszystkich rodzajów zapisów Cloud Firestore zapewnia właściwości ACID (atomowość, spójność, izolacja i trwałość) relacyjnych baz danych. Cloud Firestore zapewnia też możliwość szeregowania, co oznacza, że wszystkie transakcje są wykonywane w kolejności szeregowej.
Ogólne kroki w transakcji zapisu
Gdy Cloud Firestoreklient wyśle żądanie zapisu lub zatwierdzi transakcję za pomocą jednej z wcześniej wymienionych metod, wewnętrznie zostanie to wykonane jako transakcja odczytu i zapisu w bazie danych w warstwie pamięci. Transakcja umożliwia Cloud Firestore zapewnienie wspomnianych wcześniej właściwości ACID.
W pierwszym kroku transakcji Cloud Firestore odczytuje istniejący dokument i określa zmiany, które mają zostać wprowadzone w danych w tabeli Documents.
Obejmuje to również wprowadzenie niezbędnych zmian w tabeli indeksów w sposób opisany poniżej:
- Pola dodawane do dokumentów muszą mieć odpowiednie wstawki w tabeli indeksów.
- Pola usuwane z dokumentów muszą mieć odpowiednie usunięcia w tabeli indeksów.
- Pola, które są modyfikowane w dokumentach, wymagają zarówno usunięcia (starych wartości), jak i wstawienia (nowych wartości) w tabeli indeksów.
Aby obliczyć wspomniane wcześniej mutacje, Cloud Firestore odczytuje konfigurację indeksowania projektu. Konfiguracja indeksowania przechowuje informacje o indeksach projektu. Cloud Firestore używa 2 rodzajów indeksów: indeksów pojedynczych pól i indeksów złożonych. Szczegółowe informacje o indeksach tworzonych w Cloud Firestore znajdziesz w artykule Typy indeksów w Cloud Firestore.
Po obliczeniu zmian Cloud Firestore zbiera je w transakcji, a następnie zatwierdza.
Omówienie transakcji zapisu w warstwie pamięci
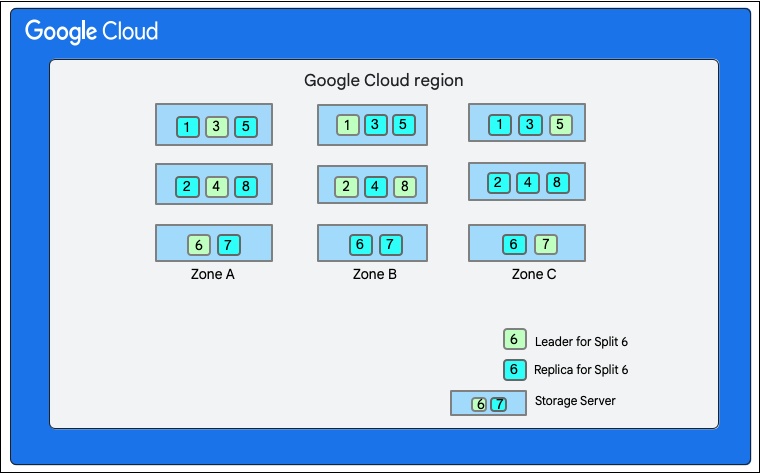
Jak już wspomnieliśmy, zapis w Cloud Firestore obejmuje transakcję odczytu i zapisu w warstwie pamięci. W zależności od układu danych zapis może obejmować co najmniej 1 podział, jak widać na układzie danych.
Na tym diagramie baza danych Cloud Firestore ma 8 podziałów (oznaczonych numerami 1–8) hostowanych na 3 różnych serwerach pamięci masowej w jednej strefie, a każdy podział jest replikowany w 3(lub więcej) różnych strefach. Każdy podział ma lidera protokołu Paxos, który może znajdować się w innej strefie w przypadku różnych podziałów.
 Podział bazy danych Cloud Firestore">
Podział bazy danych Cloud Firestore">
Rozważmy Cloud Firestore bazę danych, która zawiera Restaurants zbiór w tej postaci:
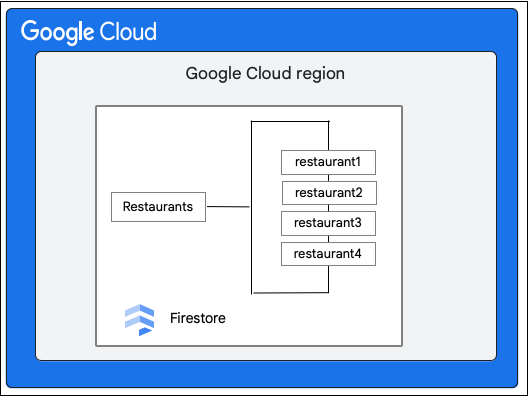
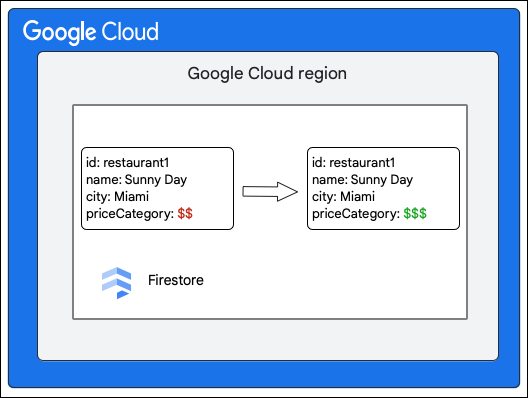
Cloud Firestore klient prosi o wprowadzenie w dokumencie w kolekcji Restaurant następującej zmiany: aktualizacja wartości pola priceCategory.
Poniżej znajdziesz ogólny opis tego, co się dzieje w ramach zapisu:
- Utwórz transakcję zapisu i odczytu.
- Odczytaj
restaurant1dokument zRestaurantskolekcji z tabeli Dokumenty z warstwy pamięci. - Odczytaj indeksy dokumentu z tabeli Indeksy.
- Oblicz mutacje, które mają zostać wprowadzone w danych. W tym przypadku jest 5 mutacji:
- M1. Zaktualizuj wiersz dla
restaurant1w tabeli Dokumenty, aby odzwierciedlał zmianę wartości polapriceCategory. - M2 i M3: usuń wiersze ze starą wartością
priceCategoryw tabeli Indeksy dla indeksów malejących i rosnących. - M4 i M5: wstaw wiersze dla nowej wartości
priceCategoryw tabeli Indeksy dla indeksów malejących i rosnących.
- M1. Zaktualizuj wiersz dla
- Zatwierdź te mutacje.
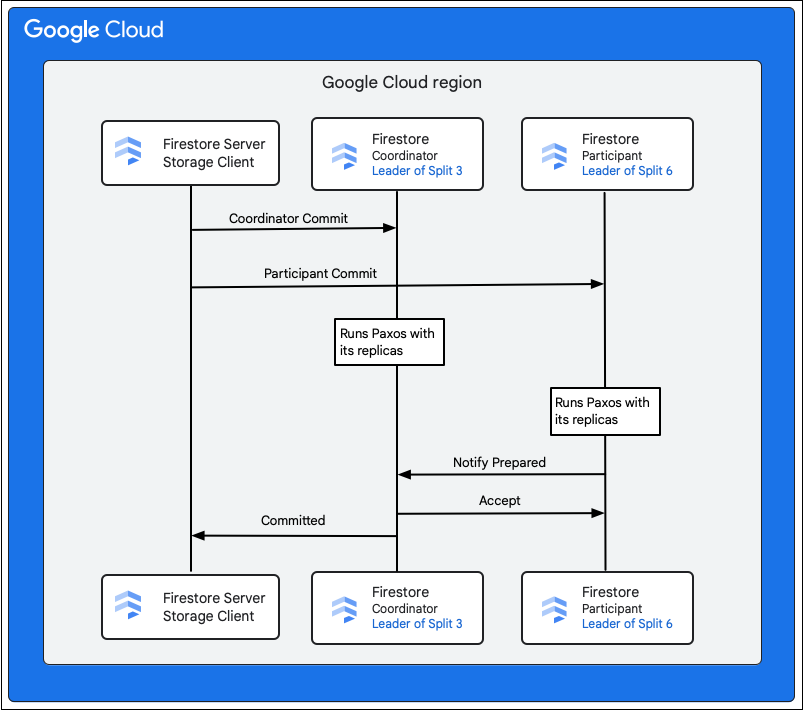
Klient usługi pamięci masowej w usłudze Cloud Firestore wyszukuje podziały, które są właścicielami kluczy wierszy do zmiany. Rozważmy przypadek, w którym podział 3 wyświetla M1, a podział 6 wyświetla M2–M5. Jest to transakcja rozproszona, w której wszystkie te podziały są uczestnikami. Podział uczestników może też obejmować inne podziały, z których dane zostały wcześniej odczytane w ramach transakcji odczytu i zapisu.
Poniżej opisujemy, co się dzieje w ramach zatwierdzania:
- Klient pamięci masowej wysyła zatwierdzenie. Zmiana zawiera mutacje M1–M5.
- W tej transakcji uczestniczą osoby 3 i 6. Jeden z uczestników jest wybierany jako koordynator, np. Split 3. Zadaniem koordynatora jest zapewnienie, że transakcja zostanie zatwierdzona lub przerwana w sposób niepodzielny u wszystkich uczestników.
- Repliki lidera tych podziałów są odpowiedzialne za pracę wykonaną przez uczestników i koordynatorów.
- Każdy uczestnik i koordynator uruchamia algorytm Paxos na swoich replikach.
- Lider uruchamia algorytm Paxos z replikami. Kworum jest osiągane, gdy większość replik odpowiada liderowi odpowiedzią
ok to commit. - Każdy uczestnik powiadamia koordynatora, gdy jest gotowy (pierwsza faza dwufazowego zatwierdzania). Jeśli którykolwiek z uczestników nie może zatwierdzić transakcji, cała transakcja
aborts.
- Lider uruchamia algorytm Paxos z replikami. Kworum jest osiągane, gdy większość replik odpowiada liderowi odpowiedzią
- Gdy koordynator wie, że wszyscy uczestnicy, w tym on sam, są gotowi, przekazuje wszystkim uczestnikom wynik transakcji
accept(druga faza dwufazowego zatwierdzania). W tej fazie każdy uczestnik zapisuje decyzję o zatwierdzeniu w pamięci trwałej i transakcja zostaje zatwierdzona. - Koordynator odpowiada klientowi usługi przechowywania w Cloud Firestore, że transakcja została zatwierdzona. Równolegle koordynator i wszyscy uczestnicy stosują zmiany w danych.
Gdy Cloud Firestore baza danych jest mała, może się zdarzyć, że pojedynczy podział zawiera wszystkie klucze w mutacjach M1–M5. W takim przypadku w transakcji uczestniczy tylko 1 podmiot, więc nie jest wymagane wspomniane wcześniej zatwierdzanie dwufazowe, co przyspiesza zapisywanie.
Zapisywanie w wielu regionach
W przypadku wdrożenia w wielu regionach rozproszenie replik w różnych regionach zwiększa dostępność, ale wiąże się z obniżeniem wydajności. Komunikacja między replikami w różnych regionach trwa dłużej. Dlatego podstawowe opóźnienie w przypadku operacji Cloud Firestore jest nieco większe niż w przypadku wdrożeń w jednym regionie.
Konfigurujemy repliki w taki sposób, aby replika wiodąca podziałów zawsze znajdowała się w regionie podstawowym. Główny region to region, z którego ruch przychodzący dociera na serwer Cloud Firestore. Ta decyzja kierownictwa zmniejsza opóźnienie w ruchu w obie strony w komunikacji między klientem pamięci masowej w Cloud Firestore a repliką główną (lub koordynatorem transakcji z wieloma podziałami).
Każdy zapis w Cloud Firestore wiąże się też z interakcją z silnikiem czasu rzeczywistego w Cloud Firestore. Więcej informacji o zapytaniach w czasie rzeczywistym znajdziesz w artykule Omówienie zapytań w czasie rzeczywistym na dużą skalę.
Poznaj okres ważności odczytu w Cloud Firestore
W tej sekcji znajdziesz informacje o samodzielnych odczytach w Cloud Firestore, które nie są wykonywane w czasie rzeczywistym. Wewnętrznie serwer Cloud Firestore obsługuje większość tych zapytań w 2 głównych etapach:
- Pojedyncze skanowanie zakresu w tabeli Indexes
- Wyszukiwanie punktowe w tabeli Dokumenty na podstawie wyniku wcześniejszego skanowania
Odczytywanie danych z warstwy pamięci jest wykonywane wewnętrznie przy użyciu transakcji bazy danych, aby zapewnić spójność odczytów. Jednak w przeciwieństwie do transakcji używanych do zapisów te transakcje nie blokują dostępu. Zamiast tego działają one w ten sposób, że wybierają sygnaturę czasową, a następnie wykonują wszystkie odczyty w tej sygnaturze. Ponieważ nie uzyskują blokad, nie blokują równoczesnych transakcji odczytu i zapisu. Aby wykonać tę transakcję, klient pamięci masowej w Cloud Firestore określa limit sygnatury czasowej, który informuje warstwę pamięci masowej, jak wybrać sygnaturę czasową odczytu. Typ wybranego przez klienta pamięci sygnatury czasowej w Cloud Firestore jest określany przez opcje odczytu w przypadku żądania odczytu.
Omówienie transakcji odczytu w warstwie pamięci
W tej sekcji opisujemy typy odczytów i sposób ich przetwarzania w warstwie pamięci w Cloud Firestore.
Wciągające lektury
Domyślnie odczyty Cloud Firestore są silnie spójne. Silna spójność oznacza, że Cloud Firestoreodczyt zwraca najnowszą wersję danych, która odzwierciedla wszystkie zapisy zatwierdzone do momentu rozpoczęcia odczytu.
Odczyt pojedynczego podziału
Klient pamięci masowej w Cloud Firestore wyszukuje podziały, które są właścicielami kluczy wierszy do odczytania. Załóżmy, że musi odczytać dane z Split 3 z wcześniejszej sekcji. Klient wysyła żądanie odczytu do najbliższej repliki, aby skrócić czas oczekiwania.
W zależności od wybranej repliki mogą wystąpić te sytuacje:
- Żądanie odczytu jest kierowane do repliki głównej (strefa A).
- Ponieważ lider jest zawsze aktualny, odczyt może być kontynuowany bezpośrednio.
- Żądanie odczytu jest kierowane do repliki niebędącej liderem (np. strefa B).
- Podział 3 może na podstawie swojego stanu wewnętrznego stwierdzić, że ma wystarczająco dużo informacji, aby obsłużyć odczyt, i to robi.
- Węzeł Split 3 nie ma pewności, czy widzi najnowsze dane. Wysyła do lidera wiadomość z prośbą o sygnaturę czasową ostatniej transakcji, którą musi zastosować, aby obsłużyć odczyt. Gdy ta transakcja zostanie zastosowana, odczyt może być kontynuowany.
Cloud Firestore zwraca odpowiedź do klienta.
Odczyt wielokrotny
Jeśli odczyty muszą być wykonywane z wielu podziałów, ten sam mechanizm działa we wszystkich podziałach. Gdy dane zostaną zwrócone ze wszystkich podziałów, klient pamięci masowej w Cloud Firestore łączy wyniki. Cloud Firestore odpowiada klientowi, przesyłając te dane.
Odczyty opóźnione
W Cloud Firestore domyślnym trybem jest tryb silnego odczytu. Wiąże się to jednak z potencjalnie większym opóźnieniem ze względu na komunikację, która może być wymagana z liderem. Często aplikacja Cloud Firestore nie musi odczytywać najnowszej wersji danych, a jej funkcje działają dobrze z danymi, które mogą być nieaktualne od kilku sekund.
W takim przypadku klient może zdecydować się na otrzymywanie nieaktualnych odczytów za pomocą opcji odczytu read_time. W tym przypadku odczyty są wykonywane w momencie, gdy dane były w stanie read_time, a najbliższa replika najprawdopodobniej już potwierdziła, że zawiera dane w określonym stanie read_time.
Aby uzyskać zauważalnie lepszą wydajność, rozsądną wartością nieaktualności jest 15 sekund. Nawet w przypadku nieaktualnych odczytów zwracane wiersze są ze sobą spójne.
Unikanie obszarów interaktywnych
Podziały w Cloud Firestore są automatycznie dzielone na mniejsze części, aby w razie potrzeby lub w przypadku rozszerzenia przestrzeni kluczy rozdzielić pracę związaną z obsługą ruchu na większą liczbę serwerów pamięci. Podziały utworzone w celu obsługi nadmiernego ruchu są zachowywane przez około 24 godziny, nawet jeśli ruch ustanie. Jeśli więc występują powtarzające się skoki ruchu, podziały są utrzymywane, a w razie potrzeby wprowadzane są kolejne. Te mechanizmy pomagają bazom danych Cloud Firestore automatycznie skalować się w miarę wzrostu obciążenia ruchem lub rozmiaru bazy danych. Istnieją jednak pewne ograniczenia, o których warto pamiętać. Opisujemy je poniżej.
Podział pamięci i obciążenia wymaga czasu, a zbyt szybkie zwiększanie ruchu może powodować duże opóźnienia lub błędy przekroczenia terminu, powszechnie określane jako hotspoty, podczas gdy usługa się dostosowuje. Zalecamy rozdzielanie operacji w zakresie kluczy i zwiększanie ruchu w kolekcji w bazie danych z 500 operacjami na sekundę. Po tym stopniowym wzroście zwiększaj ruch o maksymalnie 50% co 5 minut. Ten proces jest nazywany regułą 500/50/5 i umożliwia optymalne skalowanie bazy danych pod kątem Twojego zbioru zadań.
Podziały są tworzone automatycznie wraz ze wzrostem obciążenia, ale Cloud Firestore może podzielić zakres kluczy tylko do momentu, gdy będzie obsługiwać jeden dokument przy użyciu dedykowanego zestawu replikowanych serwerów pamięci masowej. W rezultacie duża i utrzymująca się liczba równoczesnych operacji na jednym dokumencie może spowodować powstanie hotspotu. Jeśli w przypadku jednego dokumentu występuje długotrwałe wysokie opóźnienie, rozważ zmodyfikowanie modelu danych, aby podzielić lub powielić dane w wielu dokumentach.
Błędy rywalizacji występują, gdy wiele operacji próbuje jednocześnie odczytać lub zapisać ten sam dokument.
Inny szczególny przypadek hotspottingu występuje, gdy jako identyfikator dokumentu w Cloud Firestore używany jest klucz rosnący lub malejący sekwencyjnie, a liczba operacji na sekundę jest bardzo wysoka. Tworzenie większej liczby podziałów nie pomoże, ponieważ nagły wzrost ruchu po prostu przeniesie się do nowo utworzonego podziału. Cloud Firestore domyślnie automatycznie indeksuje wszystkie pola w dokumencie, więc takie ruchome punkty aktywne mogą być też tworzone w przestrzeni indeksu dla pola dokumentu, które zawiera wartość rosnącą lub malejącą sekwencyjnie, np. sygnaturę czasową.
Pamiętaj, że stosując opisane powyżej metody, Cloud Firestore może skalować się tak, aby obsługiwać dowolnie duże obciążenia bez konieczności dostosowywania konfiguracji.
Rozwiązywanie problemów
Cloud Firestore udostępnia Key Visualizer jako narzędzie diagnostyczne przeznaczone do analizowania wzorców wykorzystania i rozwiązywania problemów z hotspotami.
Co dalej
- Więcej informacji o sprawdzonych metodach
- Więcej informacji o zapytaniach w czasie rzeczywistym na dużą skalę