
בין אם אתם מפתחים אפליקציה חדשה או מפעילים שירות עם נפח תנועה גבוה, תוכלו להיעזר בתובנות ובהמלצות שבמדריך הזה כדי להרחיב את הפעילות בצורה חלקה באמצעות FCM. המושגים והשיטות האלה יכולים לעזור לכם להימנע מהשפעות שליליות כשאתם צריכים לשלוח נפחים גדולים של הודעות.
מושגים והגדרות חשובים
בקשת הודעה: בקשת הודעה ב-FCM. המונח משמש לסירוגין עם 'בקשה', 'הודעה' או 'שאילתה'.
בקשות לשנייה (RPS): מדד שמתאר את קצב הבקשות הנכנסות ל-FCM. משתמשים בו לסירוגין עם 'שאילתות לשנייה' (QPS).
טוקנים של מכסות, מאגרי טוקנים ומילויים: כששולחים הודעות באמצעות FCM HTTP v1 API, כל בקשה צורכת טוקן מכסה שהוקצה לה בחלון זמן נתון. החלון הזה, שנקרא Token Bucket, מתמלא מחדש עד הסוף בסוף חלון הזמן. לדוגמה: ב-HTTP v1 API מוקצים 600,000 אסימוני מכסת שימוש לכל דלי אסימונים של דקה אחת, והוא מתמלא מחדש בסוף כל חלון זמן של דקה אחת.
ויסות בצד השרת: כשנפח התנועה חורג מהקיבולת של שירות FCM, בקשות שחורגות מקיבולת ההצגה נדחות כדי להגביל את קצב הזרימה של התנועה הנכנסת. יכול להיות שיוחזרו תגובות שגיאה מסוג 429 עם כותרות retry-after, כדי לציין שצריך להמתין פרק זמן מסוים לפני שמנסים שוב לשלוח את הבקשה.
הגבלת קצב העברת נתונים בצד הלקוח: אם הלקוחות מזהים כשלים בבקשות, חביון גבוה או שגיאות 429, הם צריכים להגביל את קצב העברת הנתונים היוצאים כדי למנוע החמרה של העומס.
השהיה מעריכית לפני ניסיון חוזר (exponential backoff): כשמנסים שוב לתקן שגיאות, מוסיפים השהיות שהולכות וגדלות באופן אקספוננציאלי. לדוגמה: 1s, 2s, 4s, 8s, 16s, 32s וכן הלאה.
שינוי קל של מרווחי הזמן: הימנעות מניסיון חוזר לשלוח בקשות במרווחי זמן מדויקים. בשיטת ה-jittering, משנים את ההשהיות בין הניסיונות החוזרים באמצעות תהליך אקראי כדי לפזר אותן באופן אחיד לאורך זמן (לדוגמה: 0.9 שניות, 2.3 שניות, 4.1 שניות, 8.5 שניות, 17.9 שניות, 34.7 שניות).
הגברה של ניסיונות חוזרים: כשמנסים לשלוח שוב בקשות שנכשלו בלי להשתמש בהשהיה מעריכית לפני ניסיון חוזר או בהוספת רעש אקראי, הבקשות האלה מצטברות ומוסיפות לעומס התנועה הקיים, ויכול להיות שהן יגבירו את הבעיות שקשורות לעומסי תנועה.
הבעיה: עליות חדות בתנועת הגולשים
מערכת FCM מעבדת מיליוני בקשות בשנייה (RPS). הגורם שהכי תורם לעומס יתר במערכת, לבעיות בזמן האחזור ולהפסקות שירות הוא עליות חדות בתעבורה.

מהי תנועה עם עליות חדות?
יש כמה סוגים שונים של עליות פתאומיות בתנועה.
עליות פתאומיות בתנועה בתחילת השעה: מערכת FCM מקבלת יותר מפי שניים תנועה במהלך 30 השניות הראשונות עד 2 הדקות של כל שעה. עלייה דומה, אם כי פחות משמעותית, נצפית גם בנקודות של חצי שעה ורבע שעה (דוגמאות: 00:15, 00:30, 00:45)

הגברת ניסיונות חוזרים: ניסיון חוזר של בקשות שנכשלו או שחלף הזמן הקצוב לתגובה שלהן בלי השהיה מעריכית לפני ניסיון חוזר (exponential backoff) יכול להצטבר לגלים חוזרים של תעבורת נתונים בנוסף לשיאי תעבורת הנתונים הקיימים.
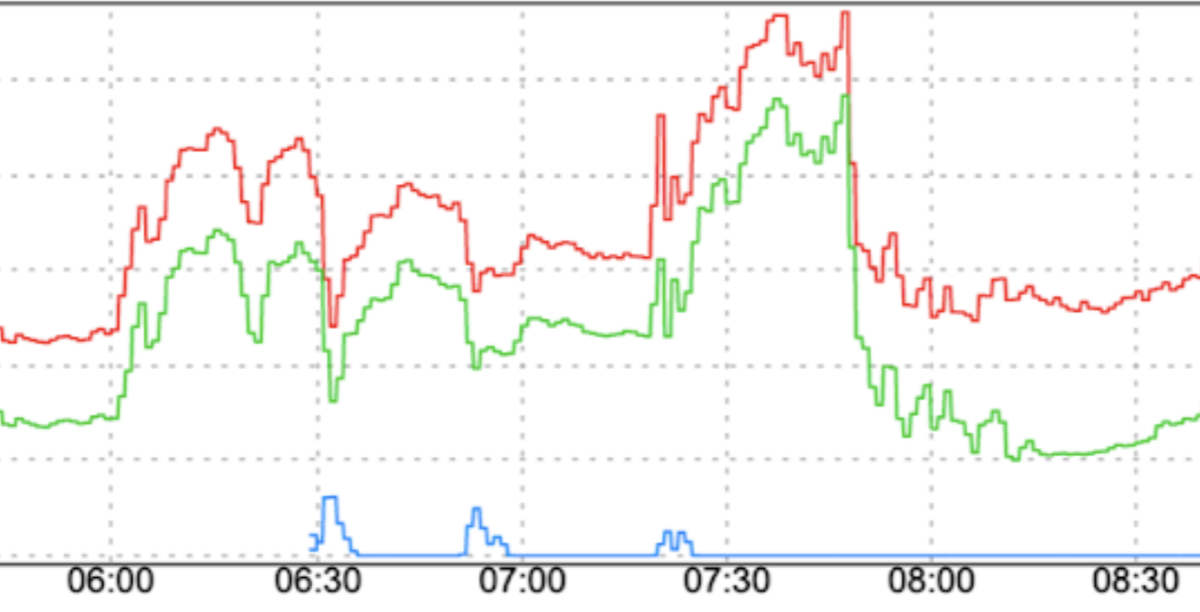
שינויים פתאומיים בדפוסי התנועה: הפניית תנועה חדשה ל-FCM או העברת תנועה ל-FCM באזורים שונים ללא גורמי החלקה כמו הגדלה הדרגתית עלולה לגרום לעליות חדות.
שימוש מוגבר באסימוני מכסה בתחילת חלונות המכסה: אם תנצלו את כל אסימוני המכסה בתחילת חלונות המכסה במקום לפזר את הבקשות באופן שווה לאורך חלונות המכסה, תיווצר תנודה של הפעלה והשבתה שקשה ויקר לבצע איזון עומסים שלה.

אירועים מיוחדים: עליות חדות בתנועה במהלך חגים (ערב השנה החדשה) או אירועי ספורט (גביע העולם בכדורגל).
איך אפשר לטפל בעליות חדות בתנועה על ידי "השטחת העקומה"
בקטע הזה מתוארות אסטרטגיות להפחתת העליות החדות בתנועה, ככל האפשר – אסטרטגיות ל'השטחת העקומה'.
שימוש במשתנה FCM רק בתרחישים מתאימים
יש כמה תרחישי שימוש שבהם אין צורך להשתמש ב-FCM כדי להעביר התראה, או שזה לא מתאים.
לדוגמה, לגבי התראות על אירועים ביומן, אפשר לתזמן משימה מקומית באפליקציה כדי להציג התראה בזמנים המתאימים במקום לשלוח אותה משרת האפליקציה. הגבלת הודעות FCM לסנכרון היומן.
הימנעות מעליות חדות
דוגמה לאנטי-תבנית שקשורה להרחבת היקף השימוש היא שליחת התראות FCM במהירות המקסימלית שהמערכות מאפשרות, במקום להשתמש בוויסות בצד השרת. כמה נקודות שכדאי לזכור:
- האם כל הלקוחות שלכם צריכים לקבל את אותה הודעה בתוך חלון זמן של דקה אחת? לדוגמה, האם חלון זמן של 5 דקות למשלוח עדיין יתאים לצרכים העסקיים שלך?
- האם אפשר לפלח את הלקוחות לפי סדר עדיפויות כדי להחליק את העליות החדות?
- האם אפשר לתזמן מראש את ההתראות?
בכל מקום שאפשר: מומלץ להימנע משימוש בשיטות שגורמות לניצול מלא של מכסת השליחה של FCM באופן מיידי, ואז חוזרות על התבנית הזו ברגע שה-token bucket מתחדש. דפוס הגישה הזה יוצר בעיות באיזון העומסים ב-FCM ובמערכות שתלויות בו. הגדילו את נפח התנועה בצורה הדרגתית ככל האפשר. לפחות, צריך להגדיל את מספר הבקשות לשנייה מ-0 למספר המקסימלי בחלון זמן של 60 שניות. מומלץ להשתמש בחלונות ארוכים יותר כדי להשיג ערך גבוה יותר של RPS.
הימנעות מפקקים בשעות עגולות
אם אפשר: מומלץ להימנע משליחת הודעות בטווח של 2 דקות לפני או אחרי כל אחת מהנקודות הבאות: 00:00, 00:15, 00:30 ו-00:45.
הטמעה של ויסות נתונים בצד השרת
כדאי להטמיע הגבלת קצב בצד השרת כדי לעקוב אחרי זרימת התנועה אל FCM ולנהל אותה.
טיפול בניסיונות חוזרים
למרות ש-FCM שואף להיות זמין מאוד, לפעמים חלק מהבקשות יגיעו לזמן קצוב לתפוגה או ייכשלו. הסיבות לכך משתנות, אבל השיטות המומלצות הבאות עוזרות לבצע אופטימיזציה של התנהגות הניסיון החוזר כדי להעביר הודעות בהקדם האפשרי, תוך צמצום ההשפעה על עומסי התנועה.
חסימות זמניות
מגדירים לפחות 10 שניות של פסק זמן לבקשות שליחה לפני שמנסים שוב. רוב הקריאות הפנימיות לפרוצדורות מרוחקות (RPC) ב-FCM משתמשות בערך הזמן הקצוב לתפוגה של 10 שניות.
שגיאות
- בשגיאות 400, 401, 403 ו-404: מבטלים את הפעולה ולא מנסים שוב.
- לשגיאות 429: צריך לנסות שוב אחרי שמחכים את משך הזמן שמוגדר בכותרת retry-after. אם לא מוגדר כותר retry-after, ברירת המחדל היא 60 שניות.
- שגיאות 500: צריך לנסות שוב עם השהיה מעריכית לפני ניסיון חוזר (exponential backoff).
השהיה מעריכית לפני ניסיון חוזר (exponential backoff)
כדי להימנע מהגברה של ניסיונות חוזרים, צריך להטמיע השהיה מעריכית לפני ניסיון חוזר (exponential backoff) עם רעידות (jittering) כדי לנסות שוב את הבקשות. לדוגמה, ב-SDK של Firebase לאדמינים מיושם מנגנון של השהיה מעריכית לפני ניסיון חוזר (exponential backoff).
הנה עוד כמה הגדרות מומלצות:
- מרווח זמן מינימלי: אל תנסו מיד לשלוח מחדש בקשה שנכשלה באמצעות FCM. צריך להמתין לפחות 10 שניות לפני שמנסים שוב לשלוח בקשה שנכשלה.
- מרווח מקסימלי: הגדרת מרווח מקסימלי להפסקת בקשות שכבר לא רלוונטיות, במקום לנסות שוב ללא הגבלה.
אם בקשה נשלחת שוב ושוב עם השהיה מעריכית לפני ניסיון חוזר, והיא עדיין נכשלת 60 דקות לאחר מכן, יכול להיות שהיא סווגה באופן שגוי כשגיאה שאפשר לנסות לשלוח שוב, או ש-FCM חווה הפסקה בשירות שבה ניסיונות חוזרים עלולים להחמיר את המצב שלא במכוון.
יצירת תוכניות להשקה ולביטול השינויים, וביצוע שינויים הדרגתיים
כשמבצעים שינויים בתנועת הגולשים בקנה מידה גדול, כמו הגדלת תנועת הגולשים ל-FCM או העברת תנועת הגולשים בין אזורים או רשתות, תכנון של תוכנית השקה או חזרה לגרסה קודמת ויישום שינויים הדרגתיים יגנו על המשתמשים, על השירות ועל FCM.
- תוכנית השקה עוזרת לבעלי העניין להבין מה מצופה מהם. במצבים מסוימים (שמפורטים בהמשך), כדאי לשתף את תוכנית ההשקה עם צוות FCM מראש כדי למנוע הפתעות.
- תוכנית חזרה למצב הקודם מאפשרת לכם להתכונן למקרי חירום וליצור מנגנונים לשחזור מהיר ובטוח של נתונים במקרה של כשלים בלתי צפויים.
- לשינויים הדרגתיים יש שני היבטים:
- השקות הדרגתיות: השלבים צריכים להיות 1% -> 5% -> 10% -> 25% -> 50% -> 75% -> 100% או יותר. Soak (התבוננות בהתנהגות המערכת בעומס) בכל שלב למשך יום אחד עד שבוע. כך תוכלו לזהות בעיות פוטנציאליות לפני השלב הבא
- הגדלה הדרגתית של נפח התנועה: כשמבצעים כל 'שלב' בהגדלת נפח התנועה, כדאי להחליק את התנועה על פני שעה לפחות. כך, תשתית איזון העומסים של FCM יכולה להתאים את עצמה לתנועת הגולשים החדשה בצורה נכונה, תוך צמצום הסיכון לנקודות חמות ולעומס.
הנה תרחיש היפותטי להעברת 500,000 בקשות לשנייה (RPS) ברחבי העולם מ-FCM Legacy HTTP API ל-FCM HTTP v1 API:
| שבוע | שלב | אסטרטגיה של הגדלה הדרגתית של נפח התנועה |
|---|---|---|
| 0 | הגדלת נפח החשיפה ב-1% | הגברת נפח התנועה בצורה חלקה מ-0 ל-5,000 בקשות לשנייה ל-FCM HTTP v1 במהלך שעה. |
| 1 | 5% הגדלת נפח החשיפה | הגדלה הדרגתית מ-5,000 ל-25,000 בקשות לשנייה במשך שעתיים. |
| 2 | הגדלת נפח של 10% | הגדלה הדרגתית מ-25,000 ל-50,000 בקשות לשנייה (RPS) במשך שעתיים |
| 3 | הגדלת נפח ב-25% | הגדלת נפח התנועה מ-50,000 ל-125,000 בקשות לשנייה (RPS) במשך 3 שעות |
| 4 | הגדלת נפח החשיפה ב-50% | הגדלת נפח התנועה מ-125,000 ל-250,000 בקשות לשנייה (RPS) במהלך 6 שעות |
| 5 | הגדלת נפח החשיפה ב-75% | הגדלה הדרגתית מ-250,000 ל-375,000 בקשות לשנייה (RPS) במשך 6 שעות |
| 6 | הגדלה הדרגתית של נפח התנועה ב-100% | הגדלה הדרגתית מ-375,000 ל-500,000 בקשות לשנייה במשך 6 שעות |
תוכנית היפותטית לביטול השינויים:
- אם זמן האחזור של אחוזון 95 עולה על 500 אלפיות השנייה או אם יחס השגיאות עולה על 1% למשך יותר משעה בכל שלב, צריך להשתמש בהגדרה דינמית כדי לחזור לשלב הקודם באופן מיידי.
- ממשיכים להחזיר את השינויים לשלבים קודמים עד שזמן האחזור ויחס השגיאות חוזרים לרמות הרגילות.
באילו מקרים צריך לפנות לתמיכה של FCM
אם אחד מהמקרים הבאים רלוונטי, אפשר לפנות ל-FCM דרך התמיכה של Firebase:
- המכסות שמוגדרות כברירת מחדל כבר לא מתאימות לתרחיש השימוש שלכם
- אתם משנים את דפוסי השליחה שלכם במסגרת חלון של 3 חודשים בקנה מידה של 100,000 בקשות לשנייה ברחבי העולם או 30,000 בקשות לשנייה ביבשת.