
无论您是正在开发新生应用还是已经在运行高流量服务,都可以从本指南有关如何使用 FCM 顺利扩缩的数据洞见和建议中受益。当您需要发送大量消息时,这些概念和做法可帮助您避免负面影响。
关键术语和概念
消息请求:FCM 消息请求;与“请求”“消息”或“查询”互换使用。
每秒请求次数 (RPS):用于描述发送到 FCM 的传入请求速率的指标;与每秒查询次数 (QPS) 互换使用。
配额令牌、令牌桶和补充:向 FCM HTTP v1 API 发送消息时,每个请求都会在指定时间窗口内使用分配的配额令牌。此窗口称为“令牌桶”,它会在时间窗口结束时重新填充满。例如:HTTP v1 API 为每个 1 分钟的令牌桶分配 60 万个配额令牌,这些令牌桶会在每 1 分钟的窗口结束时重新填充满。
服务器端限制:当流量超过 FCM 服务的容量时,超出服务容量的请求将被拒绝,以对入站流量流进行速率限制。系统可能会返回带有 retry-after 标头的 429 错误响应,指示您应该等待指定的时间段,然后重试请求。
客户端节流:当客户端观察到请求失败、高延迟或 429 错误时,它们应主动限制出站流量速率,以避免拥塞加剧。
指数退避算法:在重试错误时,时间延迟以指数级增加。例如:1 秒、2 秒、4 秒、8 秒、16 秒、32 秒,依此类推。
抖动:避免按精确的时间间隔重试请求。借助抖动,您可以通过随机过程改变重试延迟时间,让它们随时间均匀分布(例如:0.9 秒、2.3 秒、4.1 秒、8.5 秒、17.9 秒、34.7 秒)。
重试放大:如果在没有指数退避算法/抖动的情况下重试失败的请求,这些请求通常会累积并添加到持续的流量负载,可能会“放大”并加剧流量拥塞问题。
问题:流量激增
FCM 每秒可处理数百万个请求 (RPS)。导致系统拥塞、延迟问题和服务中断的最大因素是流量激增。
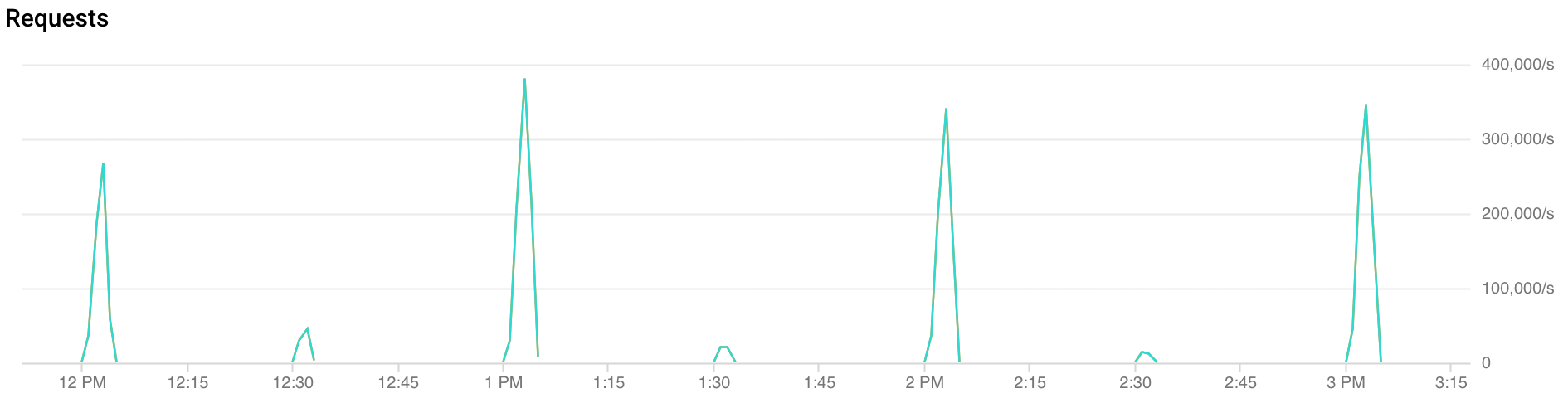
什么是流量激增?
流量激增有几种不同的类型。
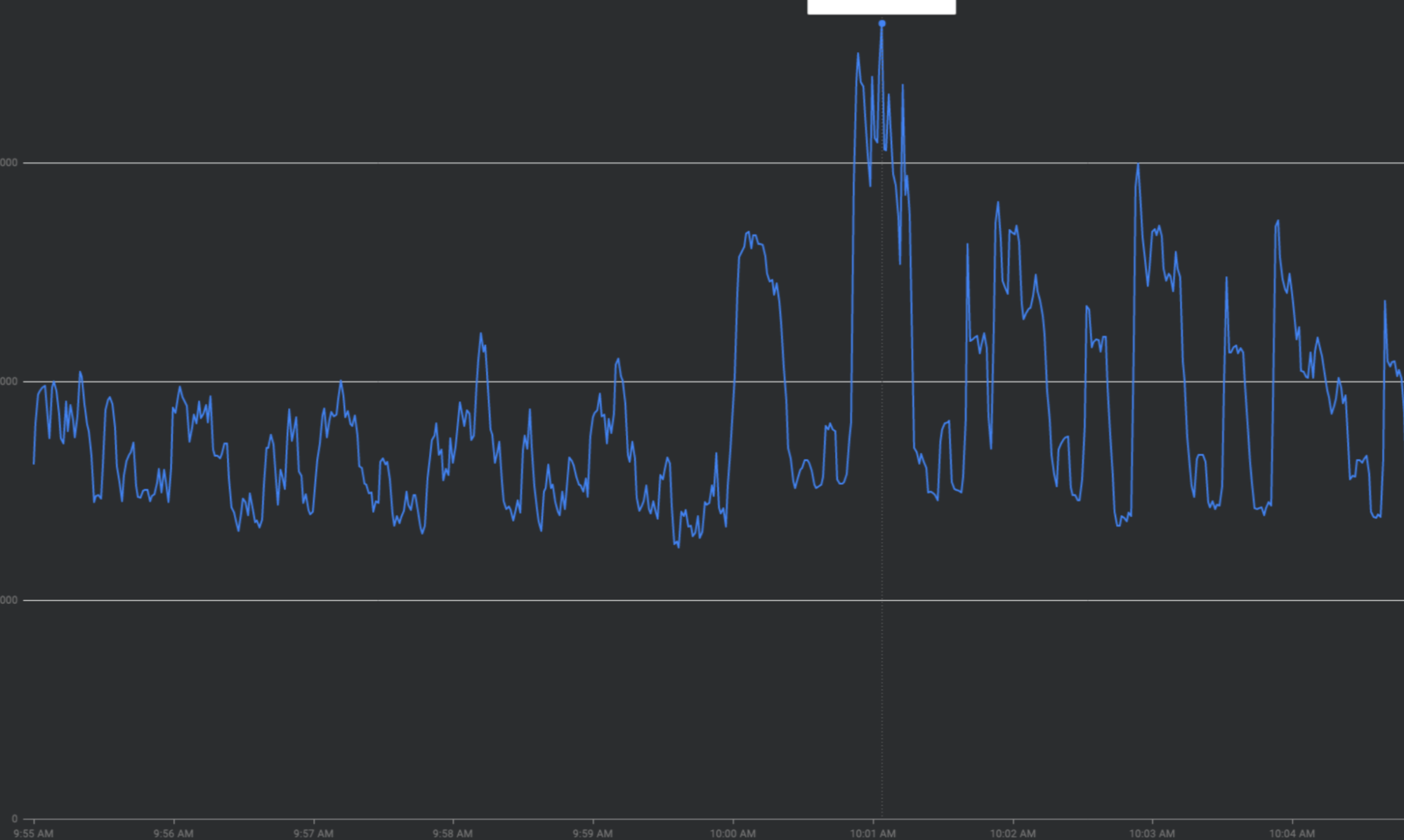
每小时峰值:FCM 在每小时的前 30 秒到每小时 2 分钟收到超过双倍的流量。在半小时和一刻钟标记处(示例:00:15、00:30、00:45)也会看到类似但更小的峰值
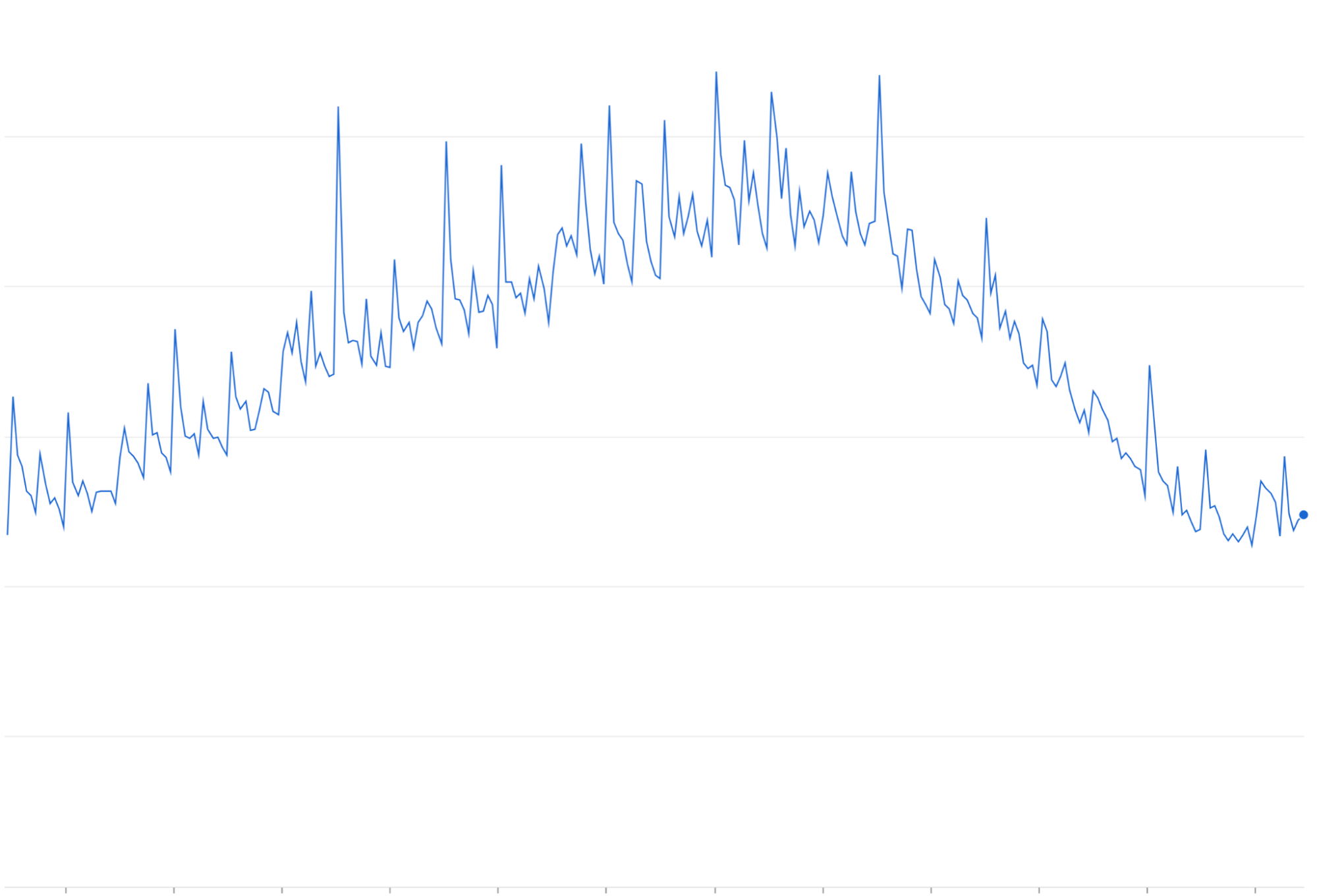
重试放大:在不使用指数退避算法的情况下重试失败或超时的请求可能会在现有流量波形上叠加重复的流量波。
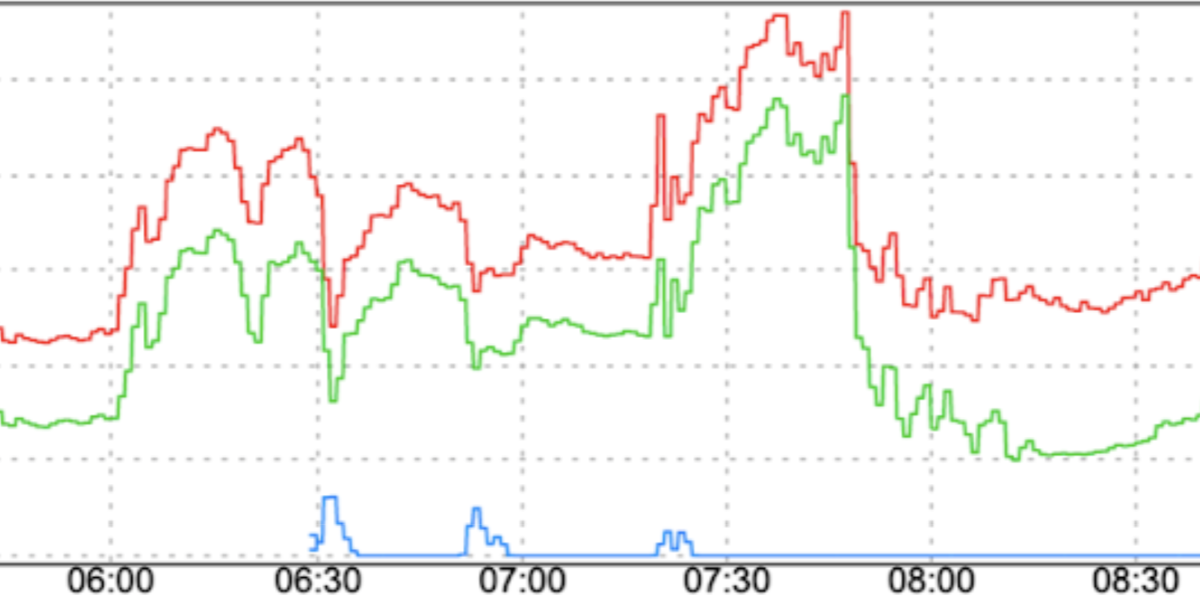
流量模式突然变化:如果在没有平滑因素(例如渐增)的情况下,将新流量定向到 FCM 或跨区域将流量移至 FCM,可能会导致流量激增。
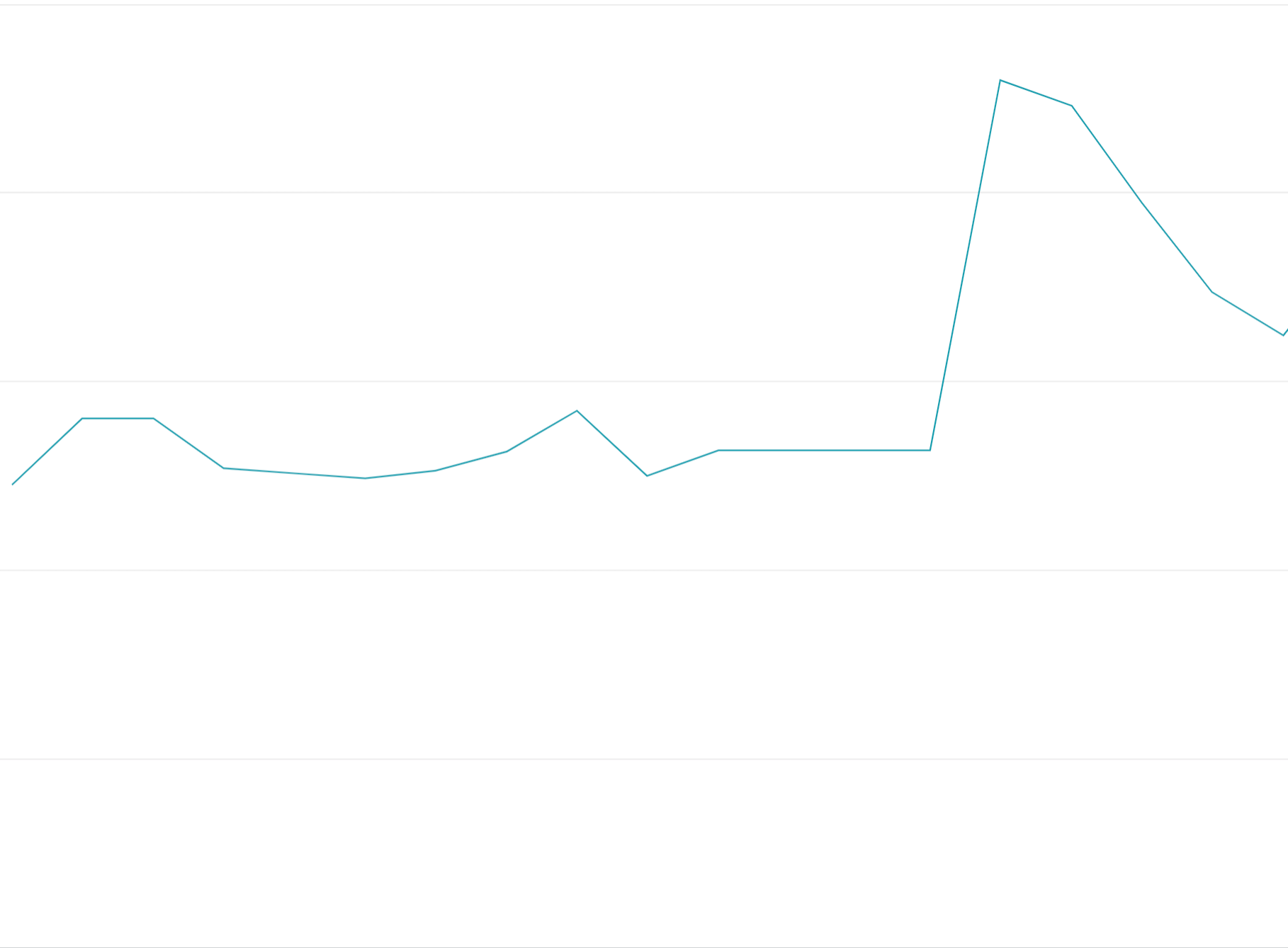
前端加载配额令牌用量:如果在配额限制开始时耗尽所有配额令牌,而不是在配额期限内均匀分布请求,就会产生开关振荡,难以进行负载均衡,而且成本高昂。
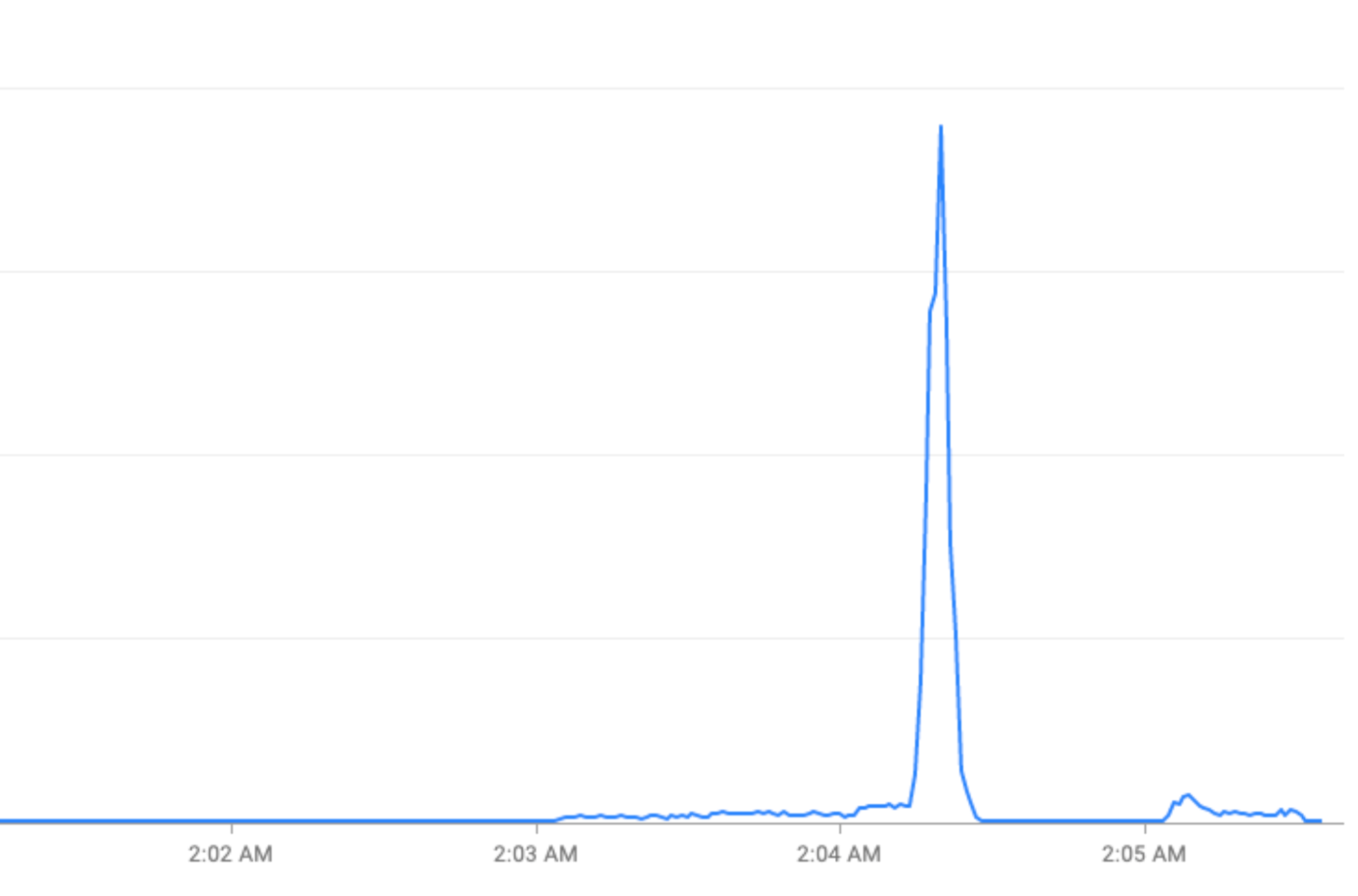
特殊活动:节假日(除夕)或体育赛事(FIFA 世界杯)期间的流量激增。
通过“扁平化曲线”解决流量激增问题
本部分介绍了削平流量高峰的策略,即“压平曲线”的策略。
仅在合适的应用场景中使用 FCM
在某些应用场景中,使用 FCM 发送通知是不必要或不合适的。
例如,对于日历活动通知,您可以在应用中预定一个本地任务,以便在适当的时间显示通知,而不是从应用服务器发送通知。请将 FCM 消息限制为日历同步。
避免激增
一种扩缩反模式是在系统允许的情况下尽快发送 FCM 通知,而不是应用服务器端限制。请考虑以下事项:
- 是否您的所有客户都需要在 1 分钟内收到相同的通知?例如,5 分钟的传递时间还能满足您的业务需求吗?
- 能否根据优先级对客户进行细分,以消除流量高峰?
- 可以提前安排通知吗?
尽可能:避免使用会导致 FCM 发送配额立即耗尽的策略,而应在令牌桶重新填充后才重复上述模式。此访问模式会导致 FCM 及其相关系统出现负载均衡问题。请尽可能循序渐进地增加流量。至少应在 60 秒的时间范围内从 0 增加到最大 RPS。为了获得更高的 RPS,首选更长的时间。
避免“准点”流量
尽可能:避免在 :00、:15、:30 和 :45 标记处的 2 分钟内发送消息。
实施服务器端限制
实施服务器端限制,以监控和管理流向 FCM 的流量。
处理重试
虽然 FCM 致力于保证高可用性,但有时某些请求会超时或失败。虽然导致此情况的原因多种多样,但以下最佳实践可优化重试行为,以便尽快传送消息,同时最大限度地减少流量拥塞。
超时
为发送请求设置至少 10 秒的超时,然后再重试。FCM 的大部分内部远程过程调用使用 10 秒的超时。
错误
- 对于 400、401、403、404 错误:取消,不重试。
- 对于 429 错误:在 retry-after 标头中设置的时长之后重试。如果未设置 retry-after 标头,则默认为 60 秒。
- 对于 500 错误:使用指数退避算法重试。
指数退避算法
为避免重试放大,请为重试请求实现带抖动的指数退避算法。例如,Firebase Admin SDK 实现了指数退避算法。
以下是其他一些推荐的设置:
- 最小间隔时间:不要使用 FCM 立即重试失败的请求。等待至少 10 秒,然后再重试失败的请求。
- 最大间隔时间:设置丢弃不再及时的请求的最大时间间隔,而不是无限期重试。
如果请求在使用指数退避算法的情况下不断重试,但在 60 分钟后仍然失败,则要么被错误归类为可重试的错误,要么 FCM 遇到了服务中断问题,此时重试可能会在无意间加剧问题。
创建发布和回滚计划,并逐步进行更改
进行大规模的流量更改(例如提高到 FCM 的流量或跨区域或网络转移流量)时,设计发布/回滚计划并实施逐步更改可以保护您的用户、服务和 FCM。
- 发布计划可以调整利益相关方的预期。在某些情况下(如下文所述),您可能需要提前与 FCM 团队分享您的发布计划,以避免意外。
- 回滚计划可让您考虑应急措施,并准备好相关机制,以便快速安全地从意外失败中恢复。
- 逐步更改有两个方面:
- “逐步”增加:步幅应为 1% -> 5% -> 10% -> 25% -> 50% -> 75% -> 100% 或更精细。每个步骤“持续”(观察负载下的系统行为)1 天至 1 周。这样您就可以在进行下一次“递增”之前发现潜在问题。
- 逐渐增加流量:当采取每一个“步骤”来增加流量时,请在至少一个小时内平滑流量。这样一来,FCM 的负载均衡基础实施便可适当扩缩您的新流量,同时最大限度地降低出现热点和拥塞的可能性。
下面是一个假设的场景,要将全球范围的 500,000 RPS 从 FCM 旧版 HTTP API 迁移到 FCM HTTP v1 API:
| 星期 | 步骤 | 逐步增加流量策略 |
|---|---|---|
| 0 | 增加 1% | 在一小时内,将 FCM HTTP v1 的 RPS 从 0 平稳增加到 5,000。 |
| 1 | 增加 5% | 在 2 小时内,从 5,000 RPS 平稳增加到 25,000 RPS。 |
| 2 | 增加 10% | 在 2 小时内,从 25,000 RPS 平稳增加到 50,000 RPS |
| 3 | 增加 25% | 在 3 小时内,将 RPS 从 50,000 增加到 125,000 |
| 4 | 增加 50% | 在 6 小时内,将 RPS 从 125,000 增加到 250,000 |
| 5 | 增加 75% | 在 6 小时内,将 RPS 从 250,000 增加到 375,000 |
| 6 | 增加 100% | 在 6 小时内,将 RPS 从 375,000 增加到 500,000 |
假设的回滚计划:
- 如果第 95 百分位延迟时间增加到超过 500 毫秒,或者错误率在任意步骤超过 1% 的时间超过 1 小时,请使用动态配置立即回滚到上一步。
- 继续回滚到更早的步骤,直到延迟时间和错误率恢复到标称水平。
何时应与 FCM 联系
如果您符合以下任一情况,请通过 Firebase 支持与 FCM 联系:
- 默认配额无法再满足您的应用场景
- 您将在 3 个月的时间内更改发送模式,规模为全球范围 100,000 RPS 或大洲范围 30,000 RPS。