
Se você estiver desenvolvendo um app iniciante ou já executando um serviço de alto tráfego, poderá se beneficiar dos insights e recomendações deste guia sobre como escalonar sem problemas com o FCM. Esses conceitos e práticas podem ajudar a evitar impactos negativos quando você precisar enviar grandes volumes de mensagens.
Principais termos e conceitos
Solicitação de mensagem: uma solicitação de mensagem do FCM. Usado alternadamente com "solicitação", "mensagem" ou "consulta".
Solicitações por segundo (RPS, na sigla em inglês): uma métrica para descrever a taxa de solicitações recebidas para o FCM. Usado de forma intercambiável com consultas por segundo (QPS).
Tokens de cota, buckets de tokens e recarregamentos: ao enviar mensagens na API FCM HTTP v1, cada solicitação consome um token de cota alocado em uma janela de tempo. Essa janela, chamada de "bucket de token", é preenchida novamente no final da janela. Por exemplo: a API HTTP v1 aloca 600 mil tokens de cota para cada bucket de tokens de um minuto, que é recarregado ao fim de cada intervalo de um minuto.
Limitação do lado do servidor: quando o volume de tráfego excede a capacidade do serviço do FCM,
as solicitações que excedem a capacidade de exibição são rejeitadas para o fluxo
de entrada com limite de taxa. As respostas de erro 429 com cabeçalhos retry-after podem ser retornadas para indicar
que você precisa aguardar um determinado período antes de repetir a solicitação.
Limitação do lado do cliente: quando os clientes observam falhas de solicitação, alta latência
ou erros de 429, eles precisam limitar a taxa voluntariamente o fluxo de saída para evitar
o congestionamento.
Espera exponencial: ao tentar novamente os erros, adicione atrasos que aumentam exponencialmente. Por exemplo: 1s, 2s, 4s, 8s, 16s, 32s e assim por diante.
Instabilidade: evite repetir solicitações em intervalos exatos. Com a instabilidade, você varia os atrasos das tentativas por meio de um processo aleatório para distribuí-los de maneira uniforme ao longo do tempo (por exemplo: 0,9s, 2,3s, 4,1s, 8,5s, 17,9s, 34,7s).
Amplificação de repetição: quando há novas tentativas para solicitações com falha sem espera exponencial/instabilidade, elas geralmente se acumulam e aumentam a carga de tráfego em andamento, possivelmente "amplificando" e agravando problemas de congestionamento de tráfego.
O problema: picos de tráfego
O FCM processa milhões de solicitações por segundo (RPS). Os maiores fatores que causam congestionamento sistêmico, problemas de latência e interrupções são os picos de tráfego.
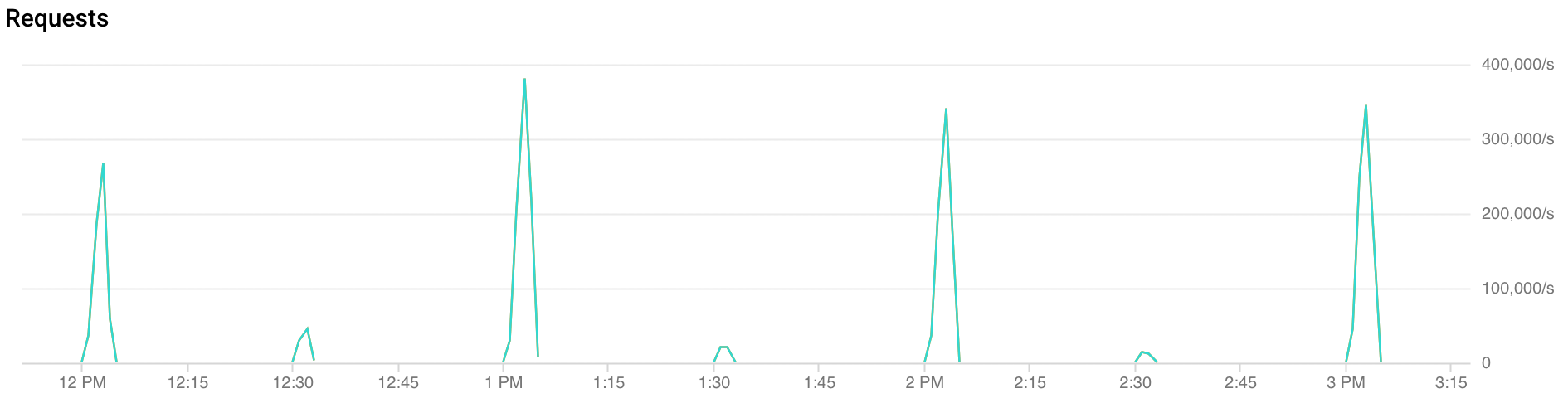
O que são picos de tráfego?
Há vários tipos diferentes de picos de tráfego.
Picos a cada hora: o FCM recebe mais do que o dobro de tráfego durante os primeiros 30 segundos a dois minutos de cada hora. Semelhantes, embora menores, os picos também são observados nas marcas de meia hora e quinze minutos (exemplos: 00:15, 00:30, 00:45)
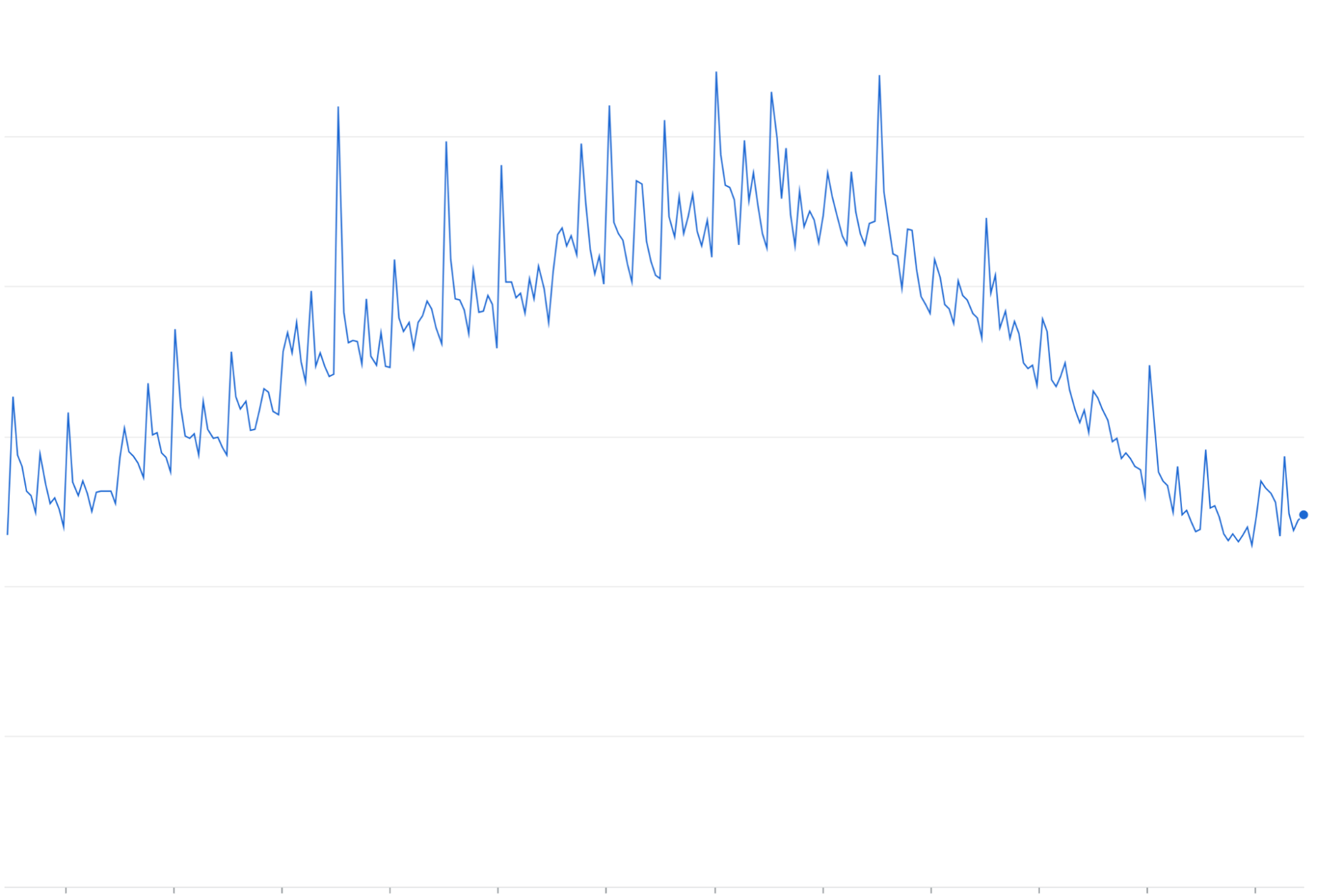
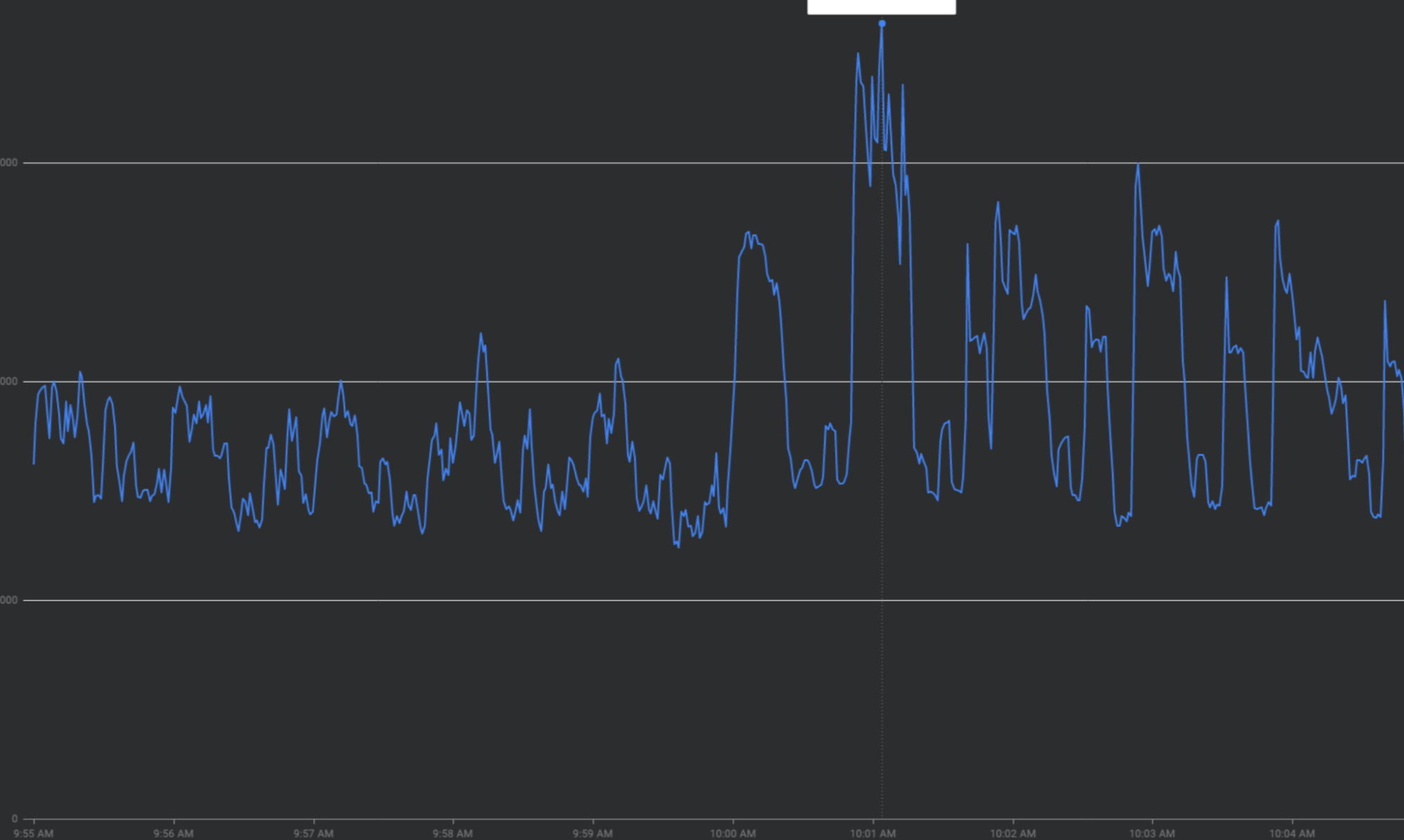
Tentar amplificação de novo:novas tentativas de solicitações com falha ou expiradas sem espera exponencial podem acumular ondas repetidas de tráfego acima de cristas de tráfego existentes.
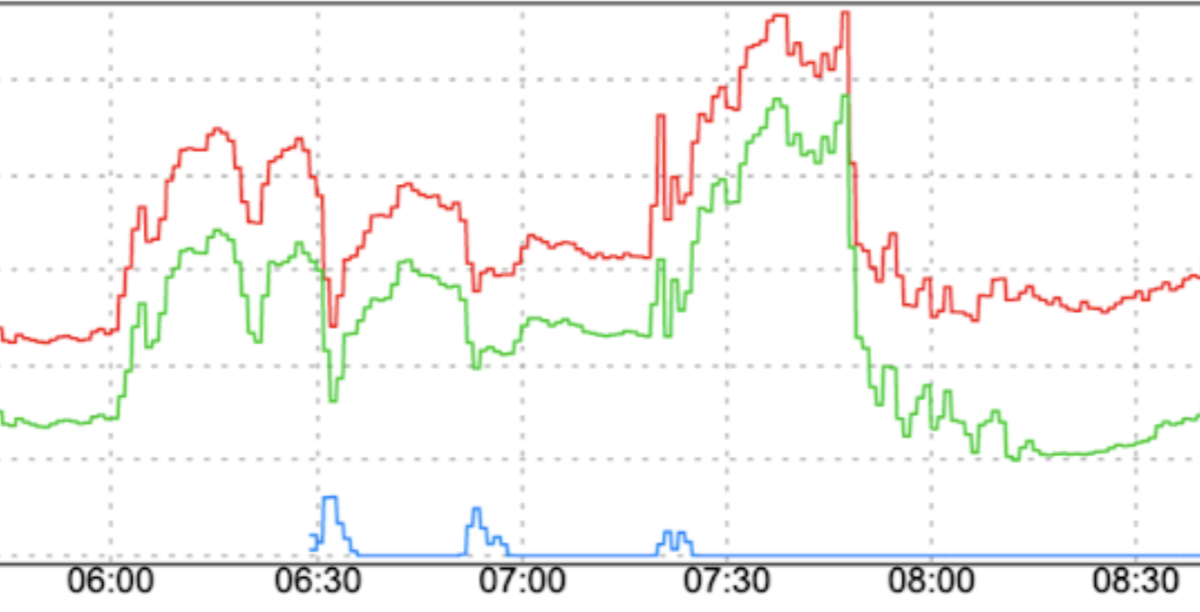
Alterações repentinas no padrão de tráfego: direcionar um novo tráfego para o FCM ou mover o tráfego para o FCM entre regiões sem suavizar fatores como um aumento gradual pode causar picos.
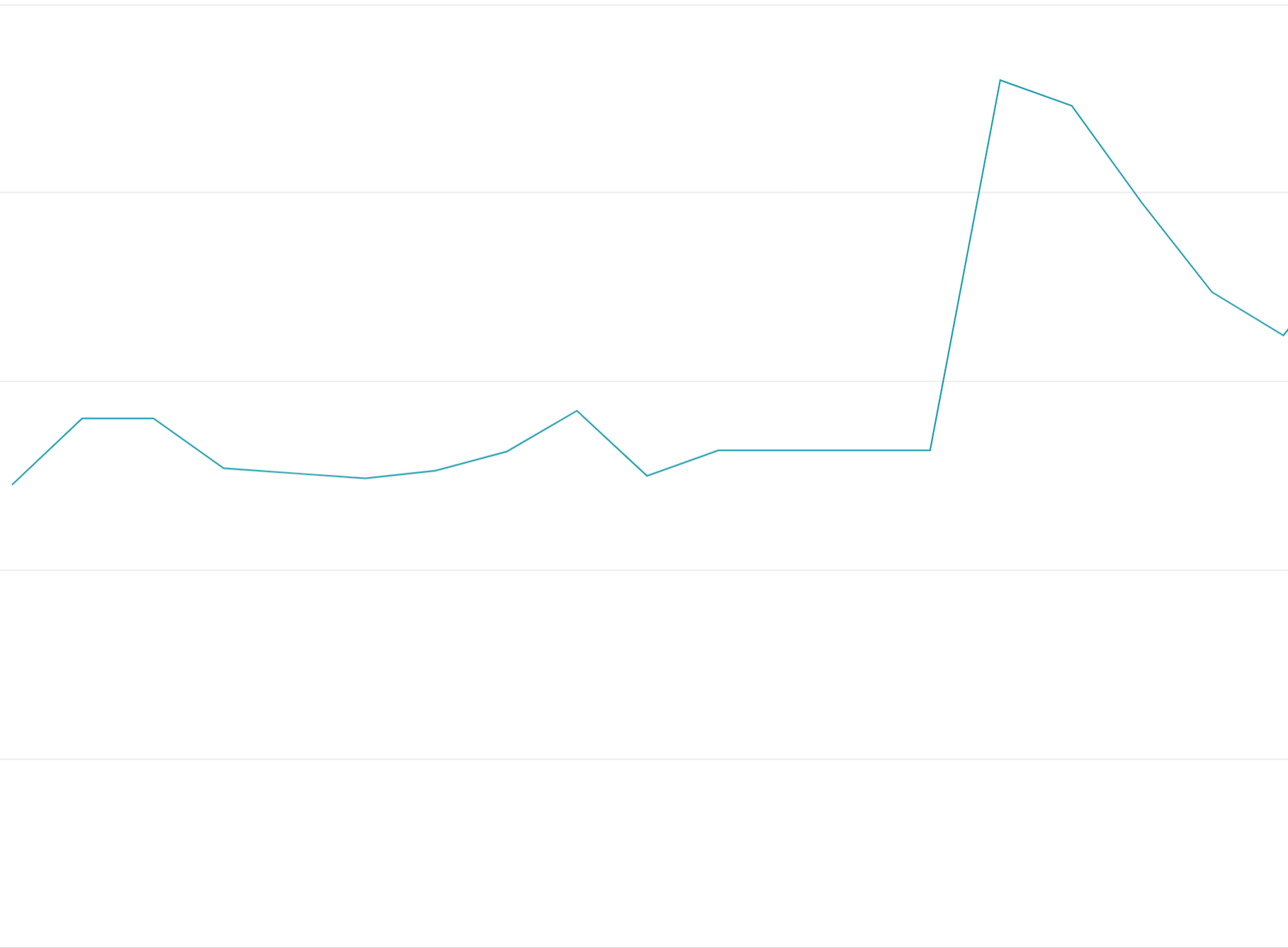
Uso antecipado de tokens de cota: esgotar todos os tokens no início das janelas de cota em vez de distribuir as solicitações de maneira uniforme pelas janelas vai criar oscilações de ativação que são difíceis e caras de balancear.
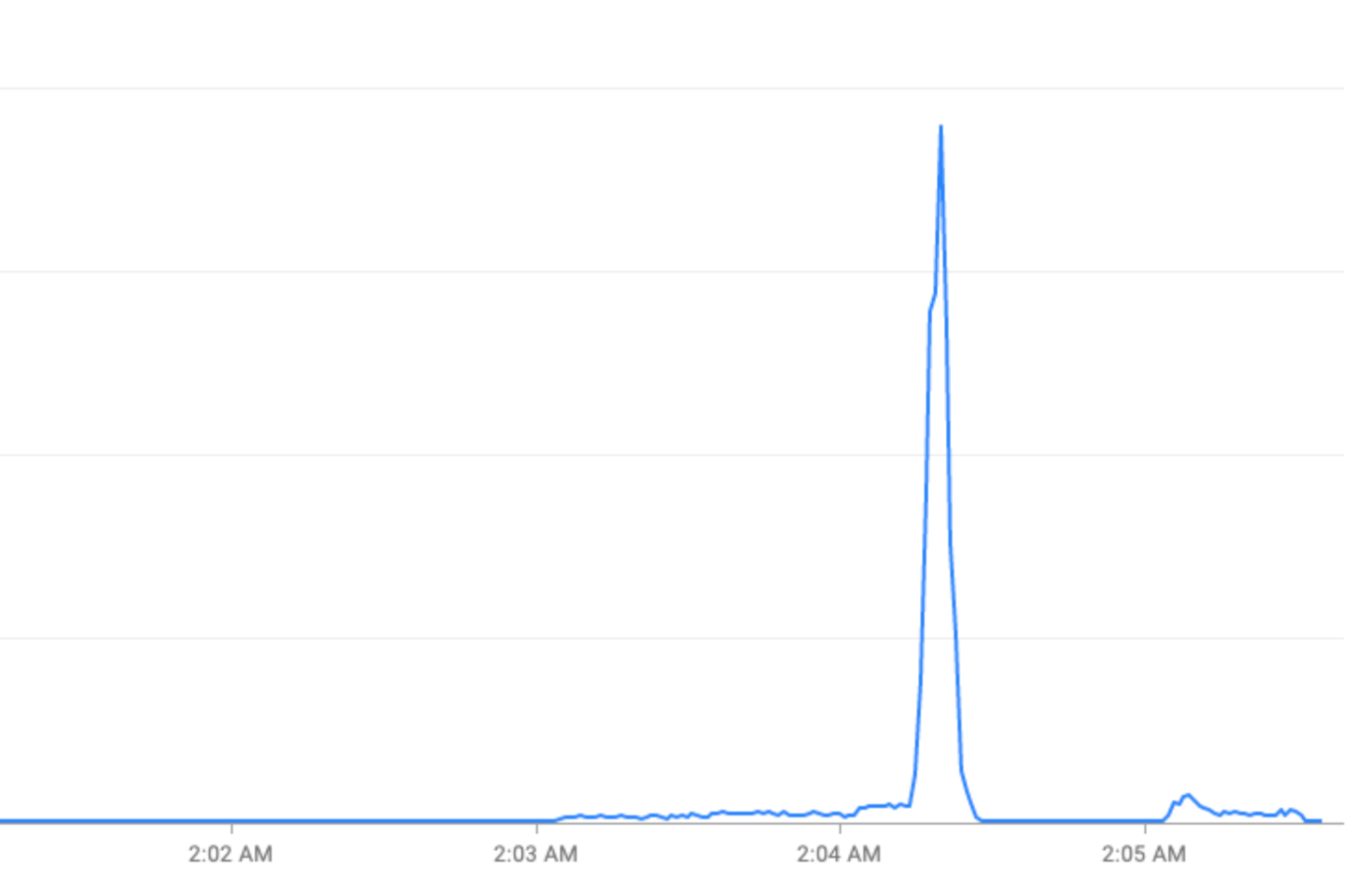
Eventos especiais: picos de tráfego durante feriados (Véspera de Ano-Novo) ou eventos esportivos (Copa do Mundo da FIFA).
Diminua os picos de tráfego ao "nivelar a curva"
Esta seção descreve estratégias para suavizar os picos de tráfego quando possível, com estratégias para "nivelar a curva".
Use o FCM apenas para casos de uso apropriados
Em alguns casos de uso, usar FCM para entregar uma notificação não é necessário ou adequado.
Por exemplo, para notificações de eventos da agenda, é possível programar uma tarefa local no seu app para exibir uma notificação nos horários adequados, em vez de enviá-la do servidor do app. Limite as mensagens do FCM a sincronizações da agenda.
Evite picos
Um antipadrão de escalonamento é enviar notificações do FCM o mais rápido possível pelos sistemas, em vez de aplicar a limitação do lado do servidor. Considere o seguinte:
- Todos os seus clientes precisam receber a mesma notificação em uma janela de um minuto? Por exemplo, uma janela de entrega de 5 minutos ainda atenderia às suas necessidades de negócios?
- Os clientes podem ser segmentados com base na prioridade para suavizar os picos?
- Suas notificações podem ser programadas com antecedência?
Sempre que possível: evite estratégias que esgotam imediatamente sua cota de envio do FCM e repita o padrão assim que o token bucket for recarregado. Esse padrão de acesso cria problemas de balanceamento de carga para o FCM e os sistemas dependentes. Aumente o tráfego gradualmente. No mínimo, aumente o RPS de 0 para a RPS máximo em um período de 60 segundos. Prefira janelas mais longas para aumentar a RPS.
Evitar trânsito "no horário"
Quando possível: evite enviar mensagens em uma janela de dois minutos para cada uma das marcas :00, :15, :30 e 45 minutos.
Implementar a limitação do lado do servidor
Implemente a limitação do lado do servidor para monitorar e gerenciar o fluxo de tráfego para o FCM.
Como gerenciar novas tentativas
O FCM se esforça para ter alta disponibilidade, mas, às vezes, algumas solicitações expiram ou falham. Embora os motivos variem, as práticas recomendadas a seguir otimizam o comportamento de repetição para entregar mensagens o mais rápido possível, minimizando o impacto no congestionamento do tráfego.
Tempo limite
Defina um tempo limite de pelo menos 10 segundos para solicitações de envio antes de tentar novamente. A maioria das chamadas de procedimento remoto internas do FCM usa um tempo limite de 10 segundos.
Erros
- Para os erros 400, 401, 403, 404: cancele e não tente novamente.
- Para erros 429: tente novamente após aguardar a duração definida no cabeçalho "tentar novamente após". Se nenhum cabeçalho de nova tentativa for definido, o padrão será 60 segundos.
- Para erros 500: tente novamente com espera exponencial.
Espera exponencial
Para evitar a amplificação de novas tentativas, implemente a espera exponencial com instabilidade para repetir solicitações. O SDK Admin do Firebase, por exemplo, implementa a espera exponencial.
Confira mais algumas configurações recomendadas:
- Intervalo mínimo: não repita imediatamente uma solicitação com falha com o FCM. Aguarde pelo menos 10 segundos antes de repetir uma solicitação com falha.
- Intervalo máximo: defina um intervalo máximo para descartar solicitações que não são mais oportunas, em vez de tentar indefinidamente.
Se uma solicitação é repetida continuamente com espera exponencial e ainda está falhando 60 minutos depois, ela foi categorizada incorretamente como um erro que pode ser repetido ou o FCM está passando por uma interrupção em que as novas tentativas podem agravar a situação acidentalmente.
Criar planos de lançamento e reversão e fazer mudanças graduais
Ao fazer alterações de tráfego em grande escala, como aumentar o tráfego para o FCM ou deslocar o tráfego entre regiões ou redes, projetar um plano de implementação/reversão e implementar alterações graduais protegerá seus usuários, seu serviço e o FCM.
- Um plano de lançamento alinha as expectativas das partes interessadas. Em determinadas situações, discutidas abaixo, você pode compartilhar seu plano de lançamento antecipadamente com a equipe do FCM para evitar surpresas.
- Um plano de reversão permite considerar as contingências e preparar mecanismos para se recuperar de maneira rápida e segura de falhas imprevistas.
- Há dois aspectos para fazer mudanças graduais:
- Aumentos por etapas: os passos devem ser de 1% -> 5% -> 10% -> 25% -> 50% -> 75% -> 100% ou mais refinados. "Imersão" (observar o comportamento do sistema sob carga) a cada etapa por um dia a uma semana. Isso permite que você identifique possíveis problemas antes da próxima "etapa"
- Aumento gradual do tráfego: ao seguir cada "etapa" para aumentar o tráfego, suavize o trânsito ao longo de pelo menos uma hora. Isso permite que a infraestrutura de balanceamento de carga do FCM faça o escalonamento adequado do novo tráfego, minimizando o potencial de congestionamento e pontos de acesso.
Confira um cenário hipotético para migrar 500.000 RPS globalmente da API FCM HTTP legada para a API FCM HTTP v1:
| Semana | Etapa | Estratégia de expansão gradual |
|---|---|---|
| 0 | Aumento de 1% | Aumente suavemente de 0 a 5.000 RPS para o FCM HTTP v1 ao longo de uma hora. |
| 1 | Aumento de 5% | Aumente tranquilamente de 5.000 para 25.000 RPS ao longo de 2 horas. |
| 2 | Aumento de 10% | Aumente tranquilamente de 25.000 para 50.000 RPS ao longo de 2 horas |
| 3 | Aumento de 25% | Aumente de 50.000 para 125.000 RPS em 3 horas |
| 4 | Aumento de 50% | Aumente de 125.000 para 250.000 RPS em 6 horas |
| 5 | Aumento de 75% | Aumente de 250.000 para 375.000 RPS em 6 horas |
| 6 | Aumento de 100% | Aumente de 375.000 para 500.000 RPS em 6 horas |
Plano hipotético de reversão:
- Se a latência de 95 percentis aumentar para mais de 500 ms ou se a proporção de erro exceder 1% por mais de uma hora em qualquer etapa, use a configuração dinâmica para voltar à etapa anterior imediatamente.
- Continue as reversões para as etapas anteriores até que a latência e a proporção de erros retornem aos níveis nominais.
Quando entrar em contato com o FCM
Entre em contato com o FCM por meio do suporte do Firebase, se uma das seguintes condições se aplicar:
- As cotas padrão não atendem mais ao seu caso de uso
- Você está alterando seus padrões de envio em um intervalo de três meses em uma escala de 100.000 RPS globalmente ou 30.000 RPS continental.