
Jika sedang mengembangkan aplikasi yang masih baru atau sudah menjalankan layanan dengan traffic tinggi, Anda dapat memanfaatkan insight dan rekomendasi dalam panduan ini mengenai cara melakukan penskalaan secara lancar dengan FCM. Konsep dan praktik ini dapat membantu Anda menghindari dampak negatif saat Anda perlu mengirim pesan dalam jumlah besar.
Istilah dan konsep utama
Permintaan Pesan: Permintaan pesan FCM; digunakan secara bergantian dengan "request", "message", atau "query".
Permintaan per detik (RPS): Metrik untuk mendeskripsikan kecepatan permintaan masuk ke FCM; digunakan secara bergantian dengan Kueri per detik (QPS).
Token Kuota, Bucket Token, dan Isi Ulang: Saat mengirim pesan terhadap FCM HTTP v1 API, setiap permintaan menggunakan Token Kuota yang dialokasikan dalam jangka waktu tertentu. Jendela ini, yang disebut "Bucket Token", melakukan isi ulang hingga penuh di akhir jangka waktu. Misalnya: HTTP v1 API mengalokasikan 600 ribu Token Kuota untuk setiap Bucket Token 1 menit, yang akan diisi ulang hingga penuh pada akhir setiap periode 1 menit.
Throttling sisi server: Jika volume traffic melebihi kapasitas layanan FCM, permintaan di luar kapasitas penayangan akan ditolak untuk membatasi aliran traffic masuk. Respons error 429 dengan header retry-after dapat ditampilkan untuk menunjukkan
bahwa Anda harus menunggu jangka waktu tertentu sebelum mencoba kembali permintaan.
Throttling sisi klien: Saat klien mengamati kegagalan permintaan, latensi tinggi, atau error 429, mereka harus secara sukarela membatasi kapasitas aliran keluar untuk menghindari hambatan yang semakin parah.
Backoff eksponensial: Saat mencoba ulang error, tambahkan penundaan waktu yang meningkat secara eksponensial. Misalnya: 1 dtk, 2 dtk, 4 dtk, 8 dtk, 16 dtk, 32 dtk, dan seterusnya.
Jittering: Menghindari percobaan ulang permintaan pada interval yang tepat. Dengan jittering, Anda dapat memvariasikan penundaan percobaan ulang melalui proses acak untuk mendistribusikannya secara seragam dari waktu ke waktu (misalnya: 0,9 dtk, 2,3 dtk, 4,1 dtk, 8,5 dtk, 17,9 dtk, 34,7 dtk).
Mencoba ulang amplifikasi: Saat permintaan yang gagal dicoba kembali tanpa jittering/backoff eksponensial, permintaan tersebut sering terakumulasi dan menambah beban traffic yang sedang berlangsung, yang berpotensi "memperkuat" dan memperburuk masalah hambatan traffic.
Masalah: lonjakan traffic
FCM memproses jutaan permintaan per detik (RPS). Penyebab terbesar hambatan sistemik, masalah latensi, dan pemadaman layanan adalah lonjakan traffic.
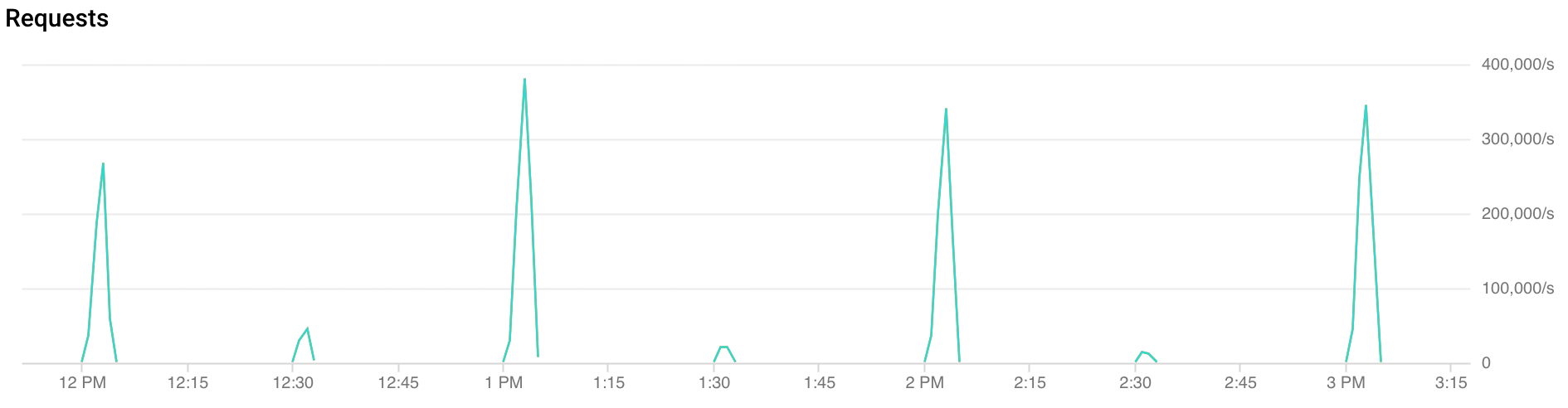
Apa itu lonjakan traffic?
Ada beberapa jenis lonjakan traffic.
Lonjakan on-the-hour: FCM menerima lebih dari dua kali lipat traffic selama 30 detik pertama hingga 2 menit setiap jam. Lonjakan serupa, meskipun lebih rendah, juga teramati pada tanda setengah jam dan seperempat jam (contoh: 00:15, 00:30, 00:45)
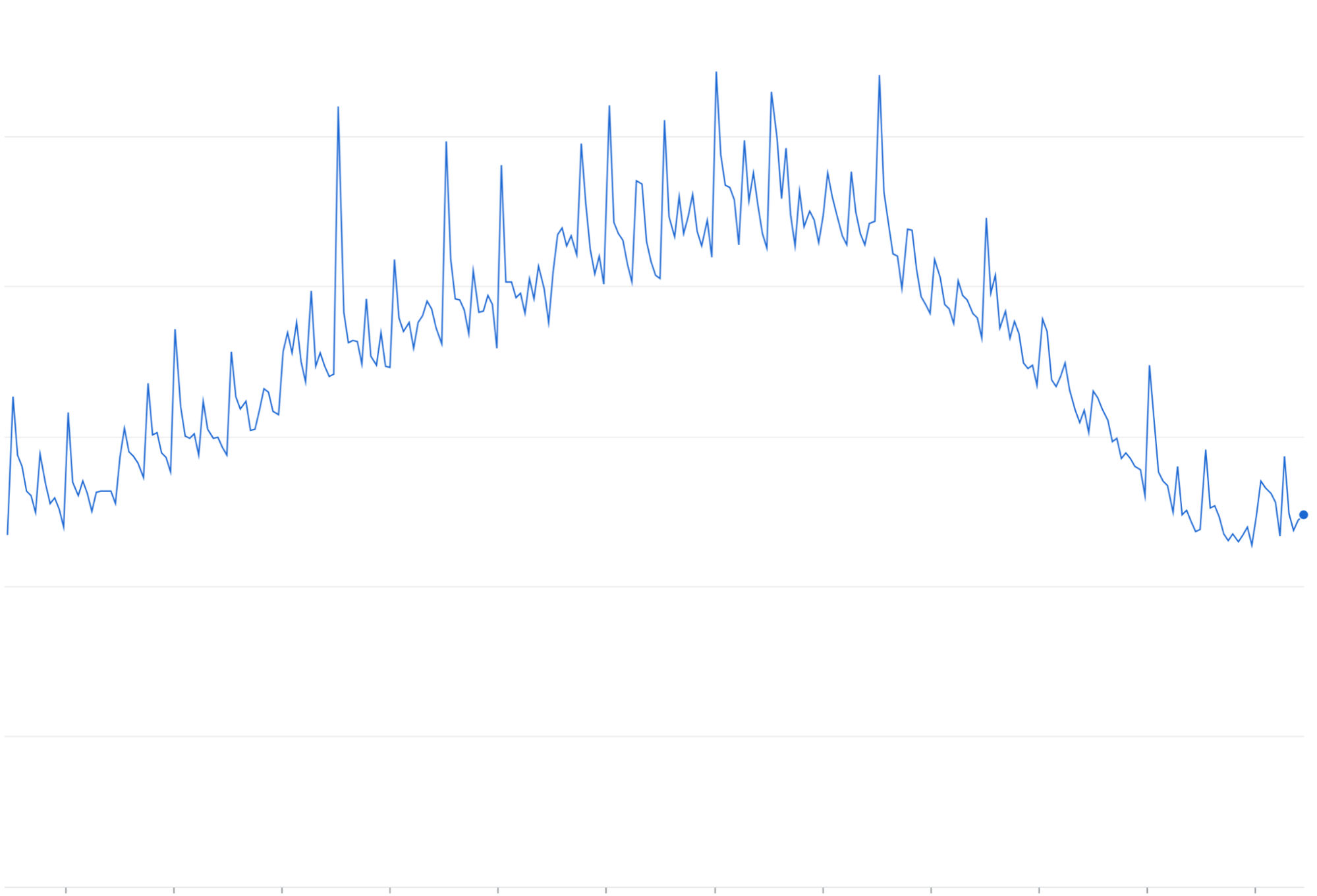
Mencoba ulang amplifikasi: Mencoba ulang permintaan yang gagal atau kehabisan waktu tanpa Backoff eksponensial dapat terakumulasi menjadi gelombang traffic berulang di atas puncak traffic yang ada.
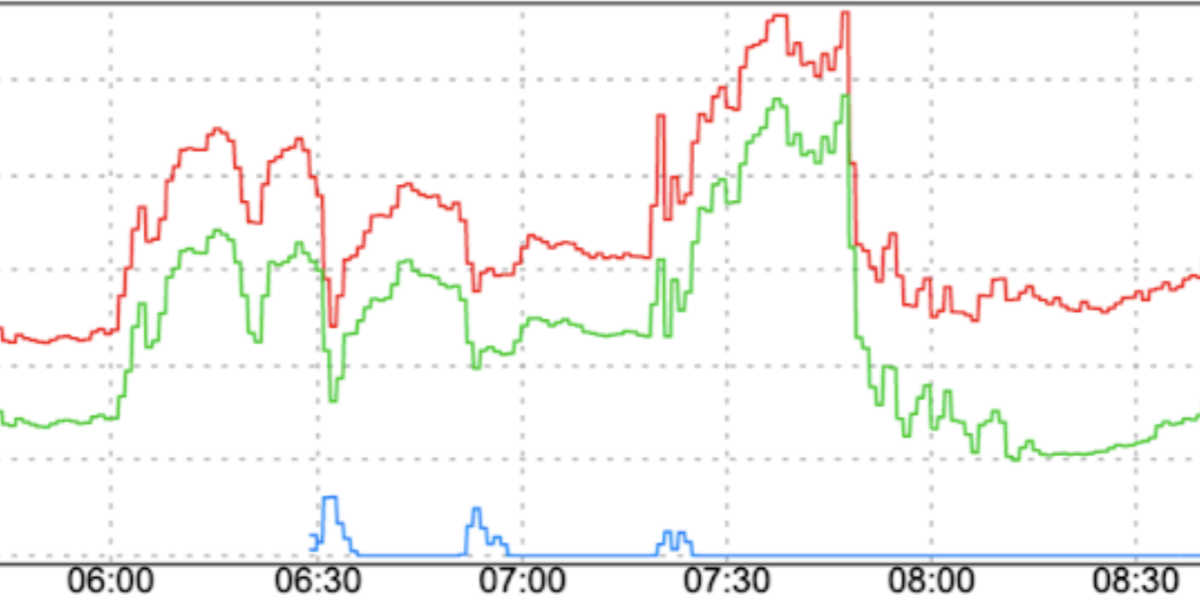
Perubahan pola traffic secara tiba-tiba: Mengarahkan traffic baru ke FCM atau memindahkan traffic ke FCM lintas region tanpa memperlancar faktor seperti peningkatan bertahap dapat menyebabkan lonjakan.
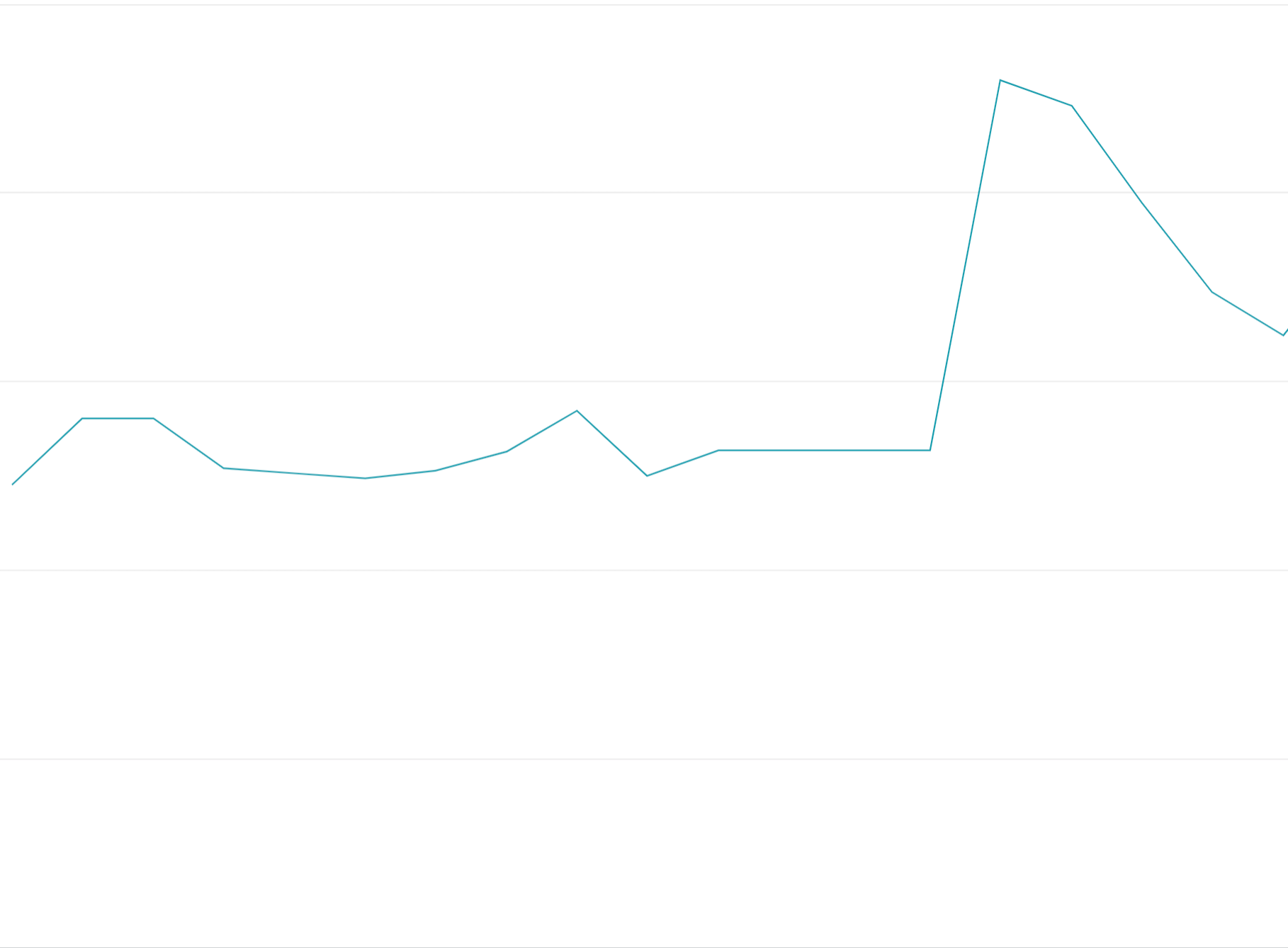
Penggunaan token kuota di awal: Menggunakan semua token kuota di awal periode kuota, bukan menyebarkan permintaan secara merata di seluruh periode kuota akan menghasilkan osilasi on-off yang sulit dan mahal untuk menyeimbangkan beban.
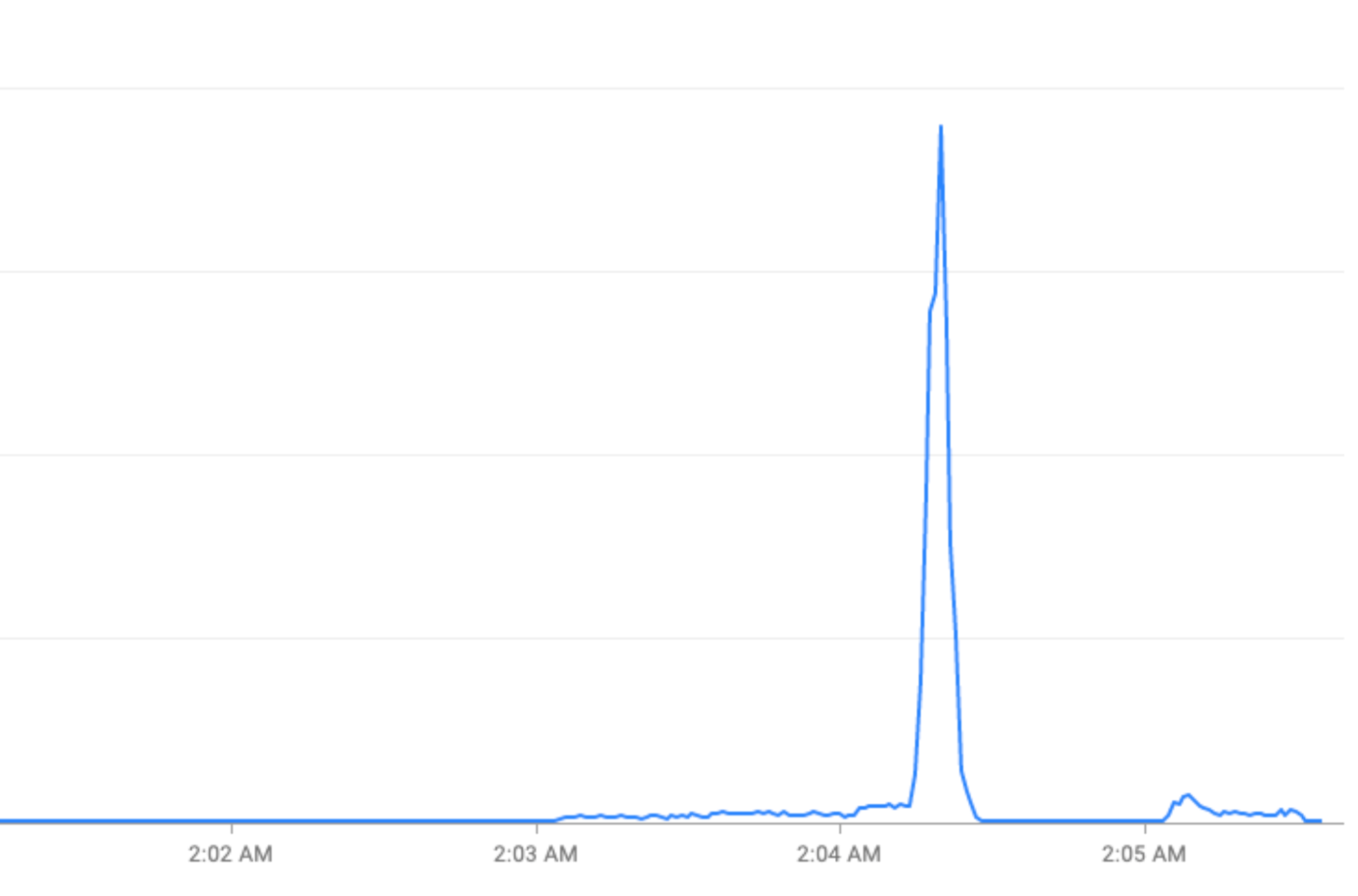
Peristiwa khusus: Peningkatan traffic selama musim liburan (Malam Tahun Baru) atau acara olahraga (Piala Dunia FIFA).
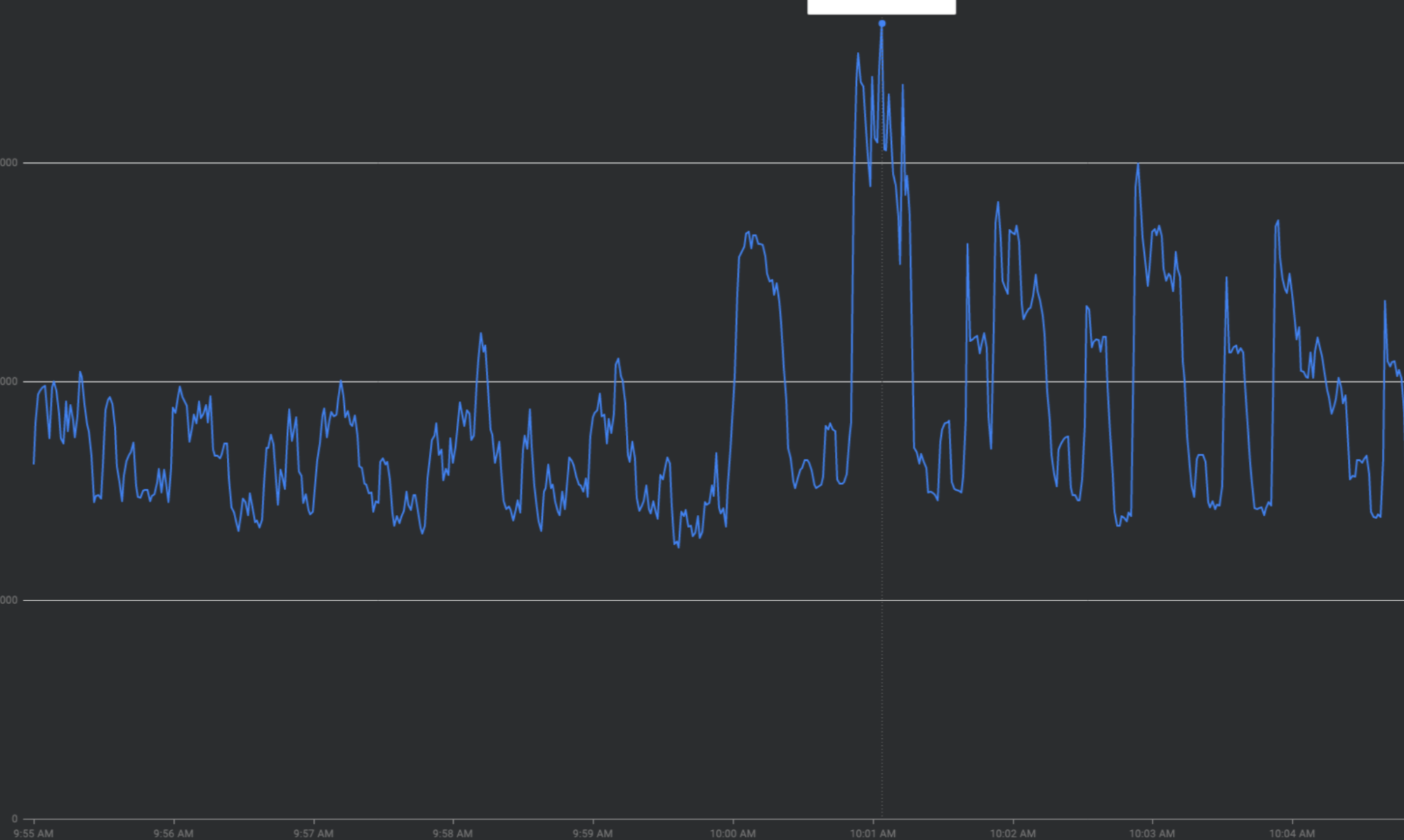
Mengatasi lonjakan traffic dengan "meratakan kurva"
Bagian ini menjelaskan strategi untuk melancarkan lonjakan traffic jika memungkinkan—strategi untuk "meratakan kurva".
Menggunakan FCM hanya untuk kasus penggunaan yang sesuai
Ada beberapa kasus penggunaan saat penggunaan FCM untuk mengirimkan notifikasi tidak diperlukan atau sesuai.
Misalnya, untuk notifikasi acara kalender, Anda dapat menjadwalkan tugas lokal di aplikasi untuk menampilkan notifikasi pada waktu yang tepat, bukan mengirimkannya dari server aplikasi Anda. Batasi pesan FCM untuk sinkronisasi kalender.
Menghindari lonjakan
Salah satu anti-pola penskalaan adalah mengirimkan notifikasi FCM secepat yang diizinkan sistem, bukan menerapkan throttling sisi server. Pertimbangkan hal berikut:
- Apakah semua pelanggan Anda perlu menerima notifikasi yang sama dalam jangka waktu 1 menit? Misalnya, apakah periode pengiriman 5 menit masih memenuhi kebutuhan bisnis Anda?
- Dapatkah pelanggan Anda disegmentasikan berdasarkan prioritas untuk mengatasi lonjakan?
- Apakah notifikasi Anda dapat dijadwalkan sebelumnya?
Jika memungkinkan: hindari strategi yang langsung menghabiskan kuota pengiriman FCM, hanya untuk mengulangi pola tersebut begitu bucket token Anda terisi ulang. Pola akses ini menimbulkan masalah load balancing untuk FCM dan sistem dependennya. Sebisa mungkin tingkatkan traffic secara bertahap. Setidaknya, tingkatkan dari 0 ke RPS maksimum dalam jangka waktu 60 detik. Pilih periode yang lebih panjang untuk RPS yang lebih tinggi.
Menghindari traffic "per jam"
Jika memungkinkan: hindari mengirim pesan dalam rentang waktu 2 menit untuk setiap tanda menit :00, :15, :30, dan :45.
Mengimplementasikan throttling sisi server
Implementasikan throttling sisi server untuk memantau dan mengelola aliran traffic ke FCM.
Menangani percobaan ulang
Meskipun FCM berusaha untuk membuat sangat tersedia, terkadang beberapa permintaan akan kehabisan waktu atau gagal. Meskipun alasannya bervariasi, praktik terbaik berikut mengoptimalkan perilaku percobaan ulang untuk mengirim pesan sesegera mungkin sambil meminimalkan dampak pada hambatan traffic.
Waktu tunggu
Tetapkan waktu tunggu minimal 10 detik pada permintaan kirim sebelum mencoba ulang. Sebagian besar Remote Procedure Call internal FCM menggunakan waktu tunggu 10 detik.
Error
- Untuk kesalahan 400, 401, 403, 404: batalkan, dan jangan coba lagi.
- Untuk error 429: coba lagi setelah menunggu durasi yang ditetapkan di header coba lagi. Jika tidak ada header coba lagi setelah ditetapkan, durasi defaultnya adalah 60 detik.
- Untuk error 500: coba lagi dengan backoff eksponensial.
Backoff eksponensial
Untuk menghindari amplifikasi percobaan ulang, terapkan back-off eksponensial dengan jittering untuk permintaan percobaan ulang. Firebase Admin SDK, misalnya, menerapkan backoff eksponensial.
Berikut adalah beberapa setelan lainnya yang direkomendasikan:
- Interval Minimum: Jangan langsung mencoba lagi permintaan yang gagal dengan FCM. Tunggu minimal 10 detik sebelum mencoba lagi permintaan yang gagal.
- Interval Maksimum: Tetapkan interval maksimum untuk menghapus permintaan yang tidak lagi tepat waktu, sebagai ganti mencoba ulang tanpa batas waktu.
Jika permintaan terus-menerus dicoba ulang dengan backoff eksponensial dan masih gagal 60 menit kemudian, permintaan tersebut akan salah dikategorikan sebagai error yang dapat dicoba lagi, atau FCM mengalami penghentian saat percobaan ulang mungkin secara tidak sengaja memperburuk situasi.
Membuat rencana peluncuran dan rollback, serta membuat perubahan bertahap
Saat membuat perubahan traffic berskala besar, seperti meningkatkan traffic ke FCM atau mengalihkan traffic ke berbagai region atau jaringan, mendesain rencana peluncuran/rollback dan menerapkan perubahan bertahap akan melindungi pengguna, layanan Anda, dan FCM.
- Rencana peluncuran menyelaraskan ekspektasi para pemangku kepentingan. Dalam situasi tertentu (dibahas di bawah), Anda mungkin ingin membagikan rencana peluncuran terlebih dahulu dengan tim FCM untuk menghindari hal yang tidak diinginkan.
- Rencana rollback memungkinkan Anda memperhitungkan kemungkinan dan menyiapkan mekanisme untuk pulih dengan cepat dan aman dari kegagalan tak terduga.
- Membuat perubahan bertahap memiliki dua aspek:
- Peningkatan "Step-wise": Langkah harus 1% -> 5% -> 10% -> 25% -> 50% -> 75% -> 100% atau lebih halus. "Soak" (amati perilaku sistem di bagian beban) setiap langkah selama 1 hari hingga 1 minggu. Hal ini memungkinkan Anda untuk menemukan potensi masalah sebelum "langkah-langkah berikutnya"
- Peningkatan traffic bertahap: Saat melakukan setiap "langkah" untuk meningkatkan traffic, kelancaran traffic selama rentang waktu minimal satu jam. Hal ini memungkinkan infrastruktur load balancing FCM untuk menskalakan traffic baru dengan tepat selagi meminimalkan potensi hotspot dan hambatan.
Berikut adalah skenario hipotesis untuk memigrasikan 500.000 RPS secara global dari FCM Legacy HTTP API ke FCM HTTP v1 API:
| Minggu | Langkah | Strategi Peningkatan Bertahap |
|---|---|---|
| 0 | 1% peningkatan | Peningkatan tanpa hambatan dari 0 menjadi 5.000 RPS ke FCM HTTP v1 selama satu jam. |
| 1 | 5% peningkatan | Peningkatan tanpa hambatan dari 5.000 menjadi 25.000 RPS selama 2 jam. |
| 2 | 10% peningkatan | Peningkatan tanpa hambatan dari 25.000 menjadi 50.000 RPS selama 2 jam. |
| 3 | 25% peningkatan | Peningkatan dari 50.000 menjadi 125.000 RPS selama 3 jam |
| 4 | 50% peningkatan | Peningkatan dari 125.000 menjadi 250.000 RPS selama 6 jam |
| 5 | 75% peningkatan | Peningkatan dari 250.000 menjadi 375.000 RPS dalam 6 jam |
| 6 | 100% peningkatan | Peningkatan dari 375.000 menjadi 500.000 RPS selama 6 jam |
Rencana rollback hipotesis:
- Jika latensi persentil 95 meningkat hingga lebih dari 500 milidetik atau jika rasio error melebihi 1% selama lebih dari satu jam pada setiap langkah, gunakan konfigurasi dinamis untuk segera roll back ke langkah sebelumnya.
- Lanjutkan rollback ke langkah sebelumnya hingga latensi dan rasio error kembali ke level nominal.
Waktu untuk menghubungi FCM
Hubungi FCM melalui Dukungan Firebase jika salah satu kondisi berikut terjadi:
- Kuota default tidak lagi memenuhi kasus penggunaan Anda
- Anda mengubah pola pengiriman dalam periode 3 bulan pada skala 100.000 RPS secara global atau 30.000 RPS secara kontinental.