
Dù đang phát triển một ứng dụng mới hay đã vận hành một dịch vụ có lưu lượng truy cập cao, bạn đều có thể hưởng lợi từ thông tin chi tiết và đề xuất trong hướng dẫn này về cách mở rộng quy mô một cách suôn sẻ bằng FCM. Các khái niệm và phương pháp này có thể giúp bạn tránh những tác động tiêu cực khi cần gửi một lượng lớn thông báo.
Các khái niệm và thuật ngữ chính
Yêu cầu thông báo: Yêu cầu thông báo FCM; được dùng thay thế cho "yêu cầu", "thông báo" hoặc "truy vấn".
Yêu cầu mỗi giây (RPS): Một chỉ số để mô tả tốc độ yêu cầu đến FCM; được dùng thay thế cho Truy vấn mỗi giây (QPS).
Mã thông báo hạn mức, Nhóm mã thông báo và Nạp lại: Khi gửi thông báo thông qua FCM HTTP v1 API, mỗi yêu cầu sẽ sử dụng một Mã thông báo hạn mức được phân bổ trong một khoảng thời gian nhất định. Khoảng thời gian này, được gọi là "Nhóm mã thông báo", sẽ được nạp lại đầy đủ vào cuối khoảng thời gian. Ví dụ: HTTP v1 API phân bổ 600 nghìn Mã thông báo hạn mức cho mỗi Nhóm mã thông báo 1 phút, nhóm này sẽ được nạp lại đầy đủ vào cuối mỗi khoảng thời gian 1 phút.
Điều tiết phía máy chủ: Khi lượng truy cập vượt quá khả năng của dịch vụ FCM, các yêu cầu vượt quá khả năng phục vụ sẽ bị từ chối để giới hạn tốc độ luồng truy cập. Thông báo phản hồi lỗi 429 có tiêu đề retry-after có thể được trả về để cho biết rằng bạn nên đợi một khoảng thời gian nhất định trước khi thử lại yêu cầu.
Điều tiết phía máy khách: Khi máy khách nhận thấy lỗi yêu cầu, độ trễ cao, hoặc lỗi 429, máy khách nên tự nguyện giới hạn tốc độ luồng gửi đi để tránh làm tình trạng tắc nghẽn trở nên trầm trọng hơn.
Thuật toán thời gian đợi luỹ thừa: Khi thử lại các lỗi, hãy thêm độ trễ thời gian tăng theo cấp số nhân. Ví dụ: 1 giây, 2 giây, 4 giây, 8 giây, 16 giây, 32 giây, v.v.
Jittering: Tránh thử lại các yêu cầu theo khoảng thời gian chính xác. Với jittering, bạn sẽ thay đổi độ trễ khi thử lại thông qua một quy trình ngẫu nhiên để phân phối chúng một cách đồng đều theo thời gian (ví dụ: 0,9 giây, 2,3 giây, 4,1 giây, 8,5 giây, 17,9 giây, 34,7 giây).
Khuếch đại thử lại: Khi các yêu cầu không thành công được thử lại mà không có thuật toán thời gian đợi luỹ thừa backoff/jittering, chúng thường tích luỹ và làm tăng tải lưu lượng truy cập đang diễn ra, có khả năng "khuếch đại" và làm trầm trọng thêm các vấn đề về tắc nghẽn lưu lượng truy cập.
Vấn đề: lưu lượng truy cập tăng đột biến
FCM xử lý hàng triệu yêu cầu mỗi giây (RPS). Nguyên nhân lớn nhất gây ra tình trạng tắc nghẽn hệ thống, vấn đề về độ trễ và ngừng hoạt động là lưu lượng truy cập tăng đột biến.
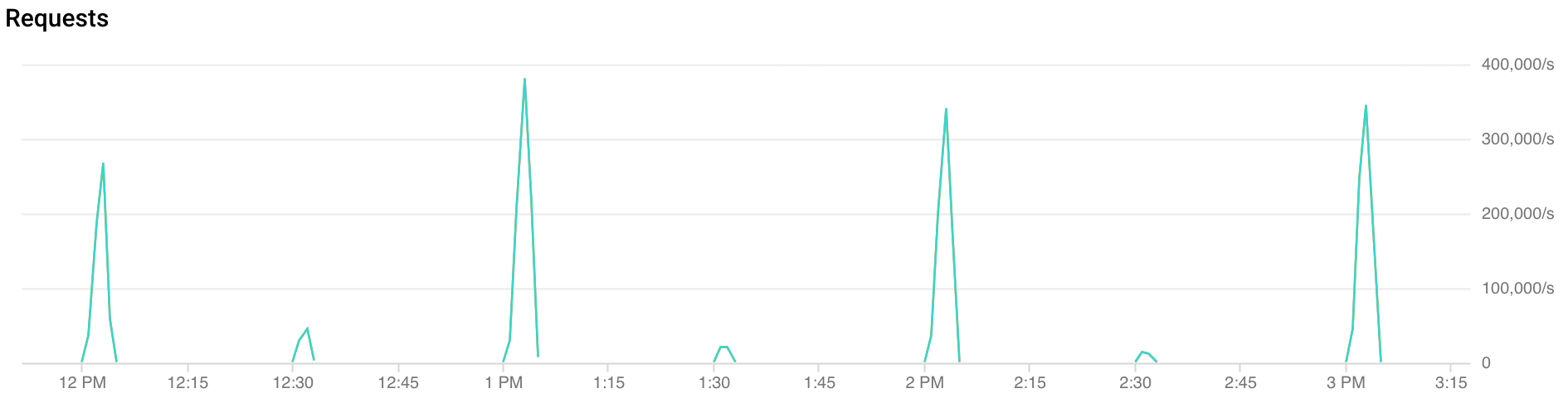
Lưu lượng truy cập tăng đột biến là gì?
Có nhiều loại lưu lượng truy cập tăng đột biến.
Lưu lượng truy cập tăng đột biến vào đầu giờ: FCM nhận được lưu lượng truy cập gấp đôi trong 30 giây đến 2 phút đầu tiên của mỗi giờ. Các mức tăng đột biến tương tự, mặc dù ít hơn, cũng được quan sát thấy ở các mốc nửa giờ và một phần tư giờ (ví dụ: 00:15, 00:30, 00:45)
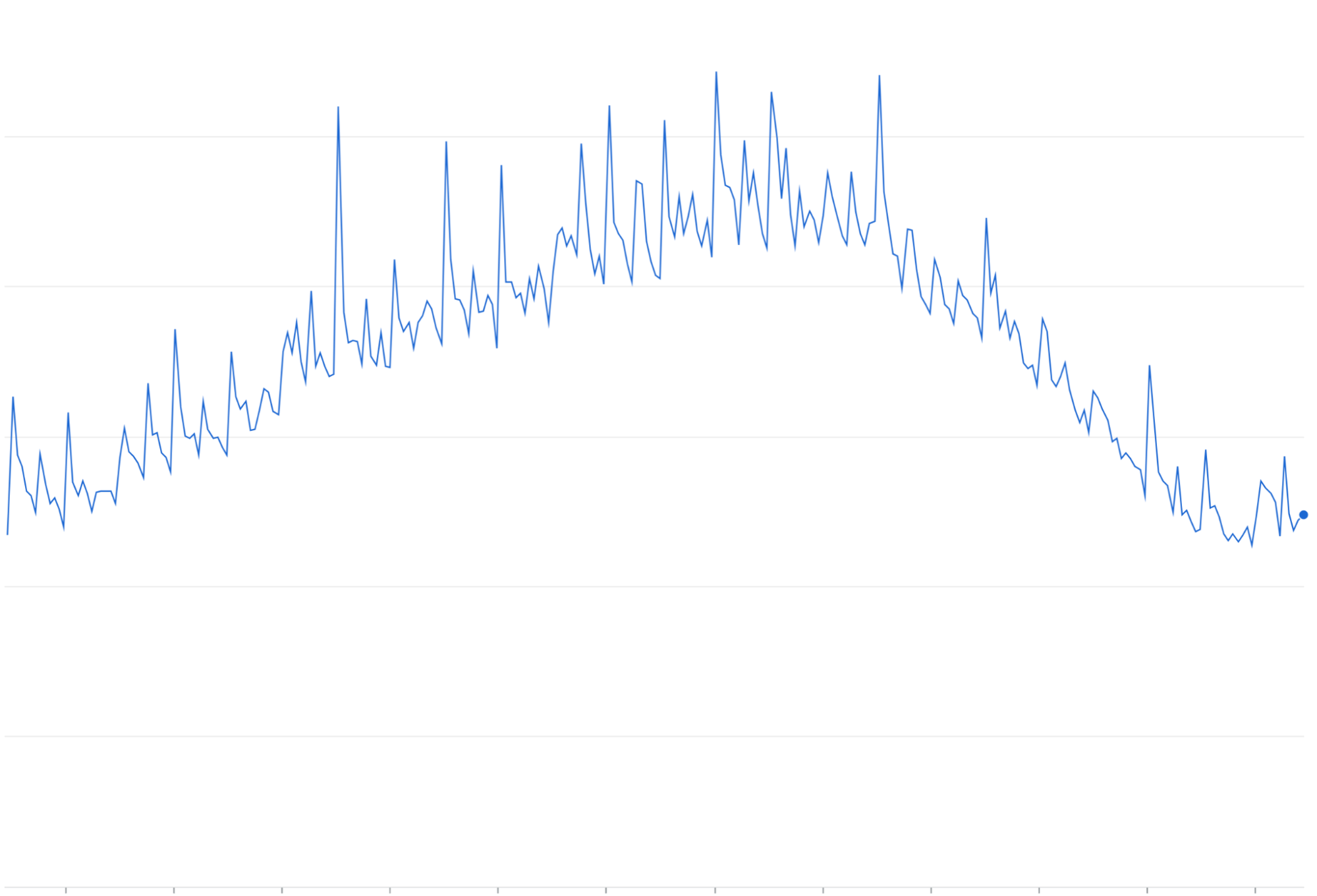
**Khuếch đại thử lại**: Thử lại các yêu cầu không thành công hoặc hết thời gian chờ mà không có Thuật toán thời gian đợi luỹ thừa có thể tích luỹ thành các đợt lưu lượng truy cập lặp lại trên đỉnh lưu lượng truy cập hiện có.
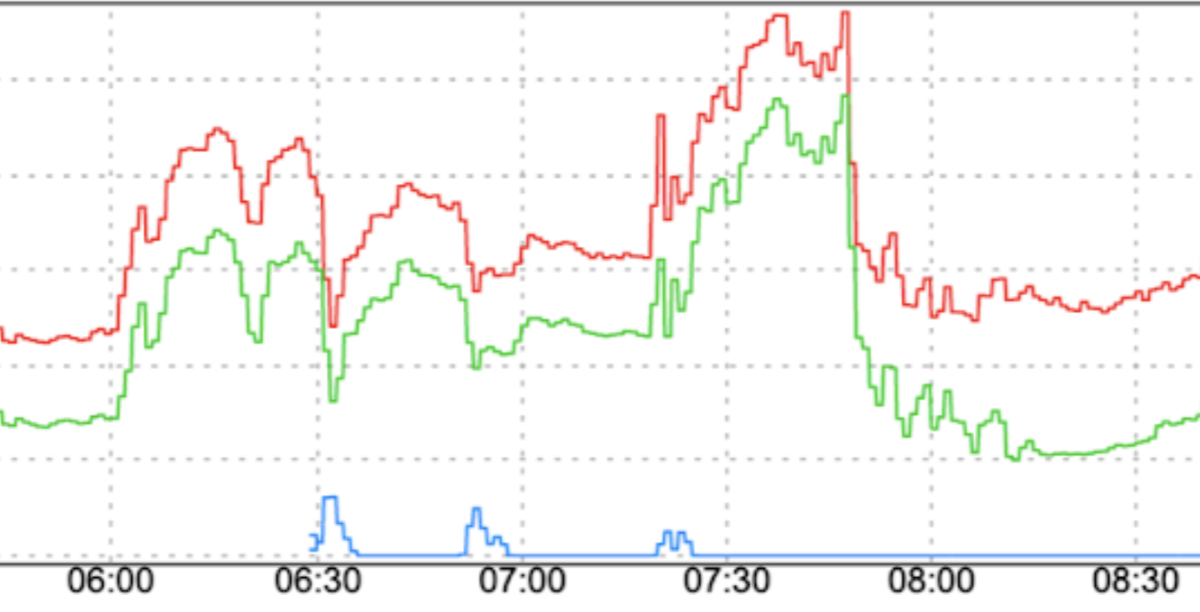
Thay đổi đột ngột về mô hình lưu lượng truy cập: Việc chuyển hướng lưu lượng truy cập mới đến FCM hoặc chuyển lưu lượng truy cập đến FCM trên các vùng mà không có các yếu tố làm mượt như tăng dần có thể gây ra tình trạng tăng đột biến.
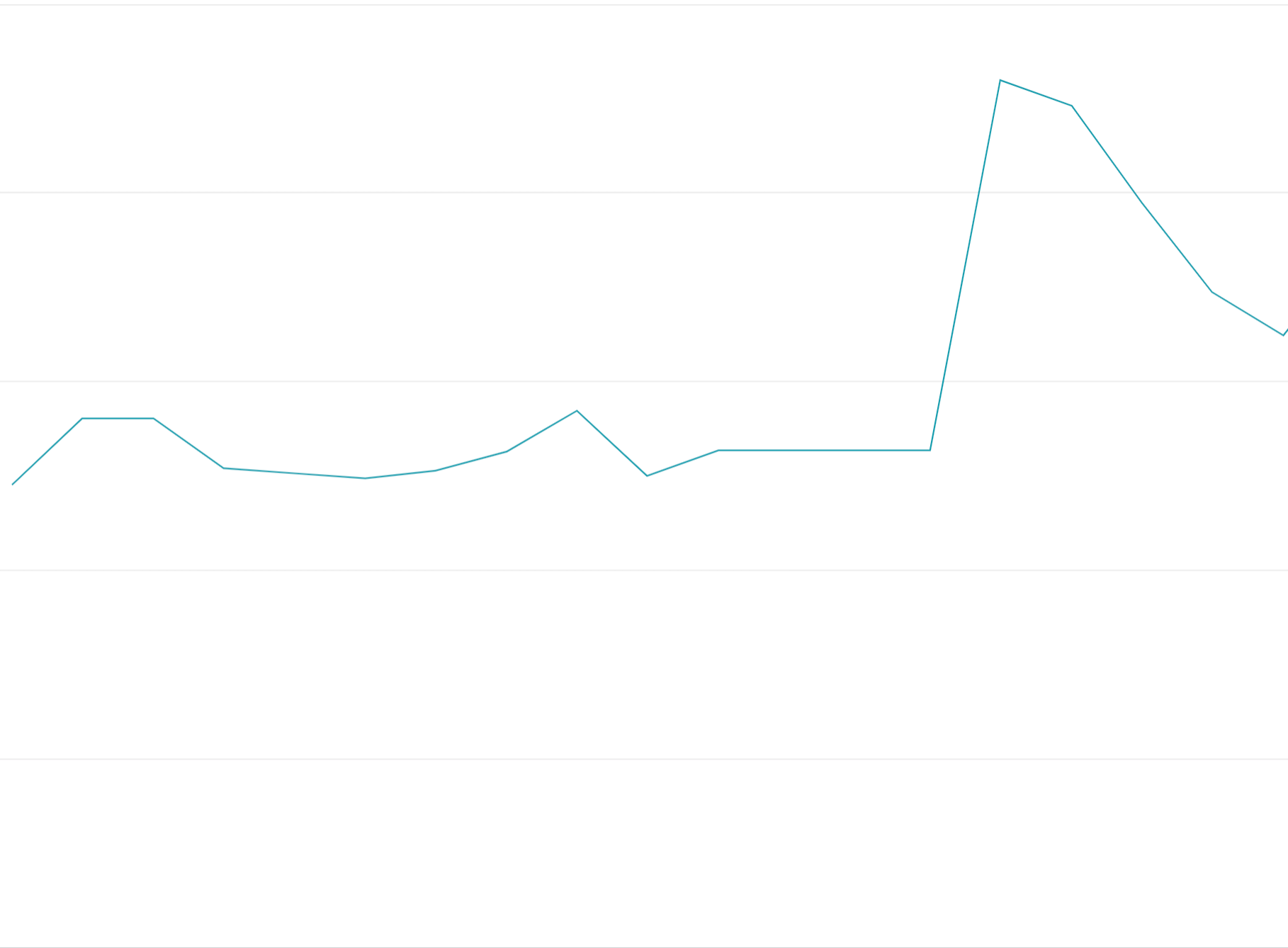
Sử dụng mã thông báo hạn mức trước: Việc sử dụng hết tất cả mã thông báo hạn mức khi bắt đầu khoảng thời gian hạn mức thay vì phân bổ các yêu cầu một cách đồng đều trên các khoảng thời gian hạn mức sẽ tạo ra các dao động bật/tắt khó cân bằng tải và tốn kém.
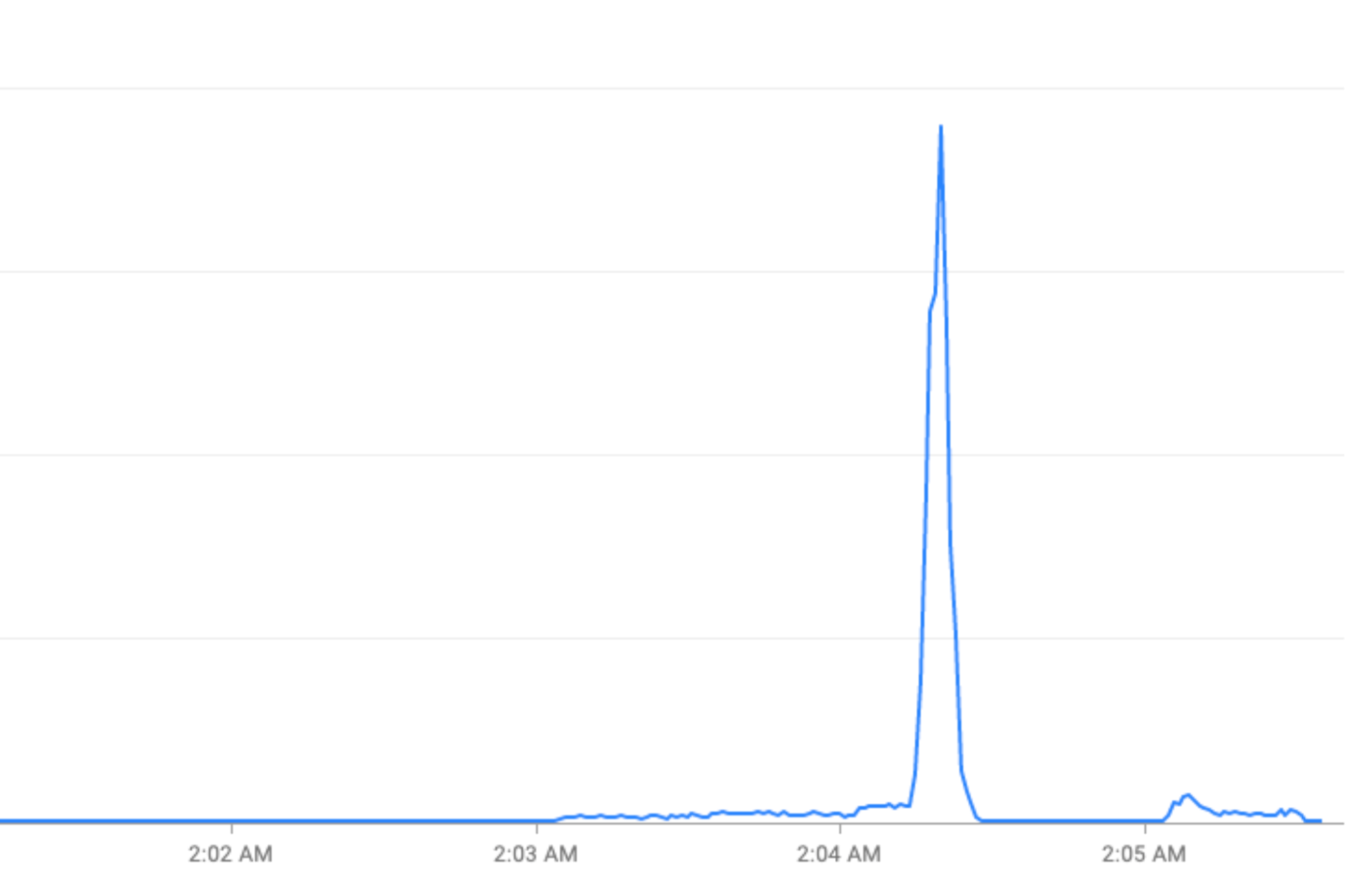
Sự kiện đặc biệt: Lưu lượng truy cập tăng đột biến trong các ngày lễ (Đêm giao thừa) hoặc sự kiện thể thao (Giải vô địch bóng đá thế giới).
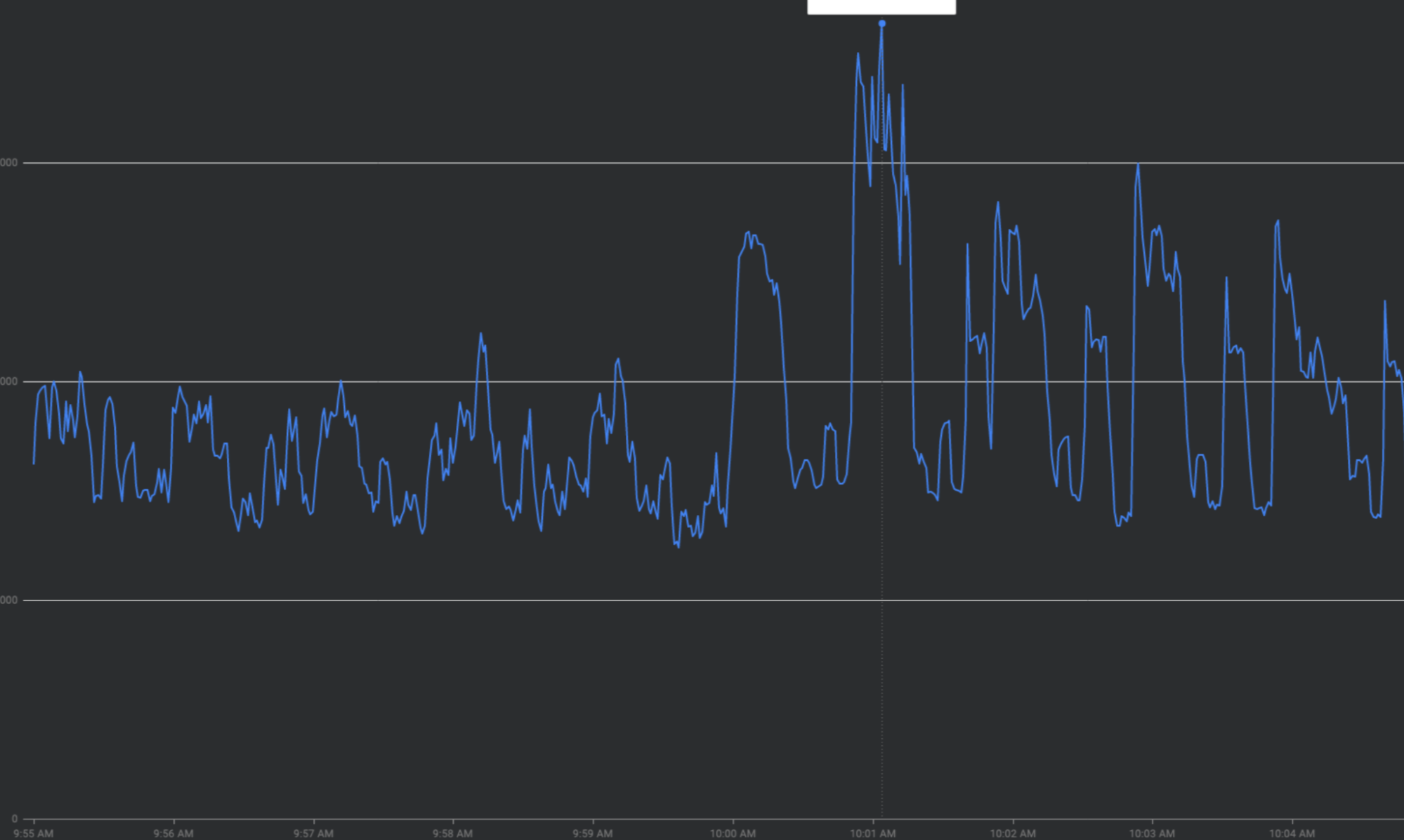
Khắc phục tình trạng lưu lượng truy cập tăng đột biến bằng cách "làm phẳng đường cong"
Phần này mô tả các chiến lược để làm mượt các đợt lưu lượng truy cập tăng đột biến khi có thể – các chiến lược để "làm phẳng đường cong".
Chỉ sử dụng FCM cho các trường hợp sử dụng phù hợp
Có một số trường hợp sử dụng mà việc sử dụng FCM để gửi thông báo là không cần thiết hoặc không phù hợp.
Ví dụ: đối với thông báo sự kiện trên lịch, bạn có thể lên lịch một tác vụ cục bộ trong ứng dụng để hiển thị thông báo vào thời điểm thích hợp thay vì gửi thông báo đó từ máy chủ ứng dụng. Giới hạn thông báo FCM cho quá trình đồng bộ hoá lịch.
Tránh tình trạng tăng đột biến
Một mô hình chống mở rộng quy mô là gửi thông báo FCM nhanh nhất có thể theo hệ thống, thay vì áp dụng biện pháp điều tiết phía máy chủ. Hãy cân nhắc những điều sau:
- Tất cả khách hàng của bạn có cần nhận cùng một thông báo trong vòng 1 phút không? Ví dụ: khoảng thời gian gửi 5 phút có đáp ứng được nhu cầu kinh doanh của bạn không?
- Bạn có thể phân đoạn khách hàng dựa trên mức độ ưu tiên để làm mượt các đợt tăng đột biến không?
- Bạn có thể lên lịch thông báo trước thời gian không?
Bất cứ khi nào có thể: tránh các chiến lược dẫn đến việc sử dụng hết hạn mức gửi FCM ngay lập tức, chỉ để lặp lại mô hình ngay khi thùng đựng thẻ của bạn được nạp lại. Mô hình truy cập này tạo ra các vấn đề về cân bằng tải cho FCM và các hệ thống phụ thuộc của nó. Tăng dần lưu lượng truy cập càng nhiều càng tốt. Tối thiểu, hãy tăng từ 0 lên RPS tối đa trong khoảng thời gian 60 giây. Ưu tiên khoảng thời gian dài hơn cho RPS cao hơn.
Tránh lưu lượng truy cập "vào đầu giờ"
Khi có thể: tránh gửi thông báo trong khoảng thời gian 2 phút của mỗi mốc :00, :15, :30 và :45 phút.
Triển khai biện pháp điều tiết phía máy chủ
Triển khai biện pháp điều tiết phía máy chủ để giám sát và quản lý luồng lưu lượng truy cập đến FCM.
Xử lý các lần thử lại
Mặc dù FCM cố gắng có tính khả dụng cao, nhưng đôi khi một số yêu cầu sẽ hết thời gian chờ hoặc không thành công. Mặc dù lý do khác nhau, nhưng các phương pháp hay nhất sau đây sẽ tối ưu hoá hành vi thử lại để gửi thông báo càng sớm càng tốt trong khi giảm thiểu tác động đến tình trạng tắc nghẽn lưu lượng truy cập.
Số lần bị tạm ngừng
Đặt thời gian chờ ít nhất 10 giây cho các yêu cầu gửi trước khi thử lại. Hầu hết các Lệnh gọi thủ tục từ xa nội bộ của FCM đều sử dụng thời gian chờ 10 giây.
Lỗi
- Đối với lỗi 400, 401, 403, 404: huỷ bỏ và không thử lại.
- Đối với lỗi 429: thử lại sau khi đợi khoảng thời gian được đặt trong tiêu đề retry-after. Nếu không có tiêu đề retry-after, hãy đặt giá trị mặc định là 60 giây.
- Đối với lỗi 500: thử lại bằng thuật toán thời gian đợi luỹ thừa.
Thuật toán thời gian đợi luỹ thừa
Để tránh khuếch đại thử lại, hãy triển khai thuật toán thời gian đợi luỹ thừa với jittering để thử lại các yêu cầu. Ví dụ: SDK của Firebase dành cho quản trị viên triển khai thuật toán thời gian đợi luỹ thừa.
Dưới đây là một số chế độ cài đặt được đề xuất khác:
- Khoảng thời gian tối thiểu: Không thử lại ngay yêu cầu không thành công bằng FCM. Đợi ít nhất 10 giây trước khi thử lại yêu cầu không thành công.
- Khoảng thời gian tối đa: Đặt khoảng thời gian tối đa để loại bỏ các yêu cầu không còn kịp thời, thay vì thử lại vô thời hạn.
Nếu một yêu cầu liên tục được thử lại bằng thuật toán thời gian đợi luỹ thừa và vẫn không thành công sau 60 phút, thì yêu cầu đó bị phân loại sai là lỗi có thể thử lại hoặc FCM đang gặp sự cố ngừng dịch vụ khiến các lần thử lại có thể vô tình làm trầm trọng thêm tình hình.
Lập kế hoạch triển khai và khôi phục, đồng thời thực hiện các thay đổi dần dần
Khi thực hiện các thay đổi lớn về lưu lượng truy cập, chẳng hạn như tăng lưu lượng truy cập đến FCM hoặc chuyển lưu lượng truy cập trên các vùng hoặc mạng, việc thiết kế kế hoạch phát hành/khôi phục và triển khai các thay đổi dần dần sẽ bảo vệ người dùng, dịch vụ và FCM.
- Kế hoạch triển khai giúp các bên liên quan có cùng kỳ vọng. Trong một số trường hợp (được thảo luận bên dưới), bạn có thể muốn chia sẻ kế hoạch triển khai trước thời gian với nhóm FCM để tránh bất ngờ.
- Kế hoạch khôi phục cho phép bạn tính đến các tình huống bất ngờ và chuẩn bị các cơ chế để nhanh chóng và an toàn khôi phục sau các lỗi không lường trước.
- Việc thực hiện các thay đổi dần dần có hai khía cạnh:
- Tăng dần "từng bước": Các bước phải là 1% -> 5% -> 10% -> 25% -> 50% -> 75% -> 100% hoặc chi tiết hơn. "Soak" (quan sát hành vi của hệ thống khi tải) mỗi bước trong 1 ngày đến 1 tuần. Điều này cho phép bạn phát hiện các vấn đề tiềm ẩn trước "bước tăng" tiếp theo
- Tăng dần lưu lượng truy cập: Khi thực hiện từng "bước" để tăng lưu lượng truy cập, hãy làm mượt lưu lượng truy cập trong khoảng thời gian ít nhất một giờ. Điều này cho phép cơ sở hạ tầng cân bằng tải của FCM mở rộng quy mô lưu lượng truy cập mới một cách thích hợp trong khi giảm thiểu khả năng xảy ra các điểm nóng và tắc nghẽn.
Dưới đây là một kịch bản giả định để di chuyển 500.000 RPS trên toàn cầu từ FCM Legacy HTTP API sang FCM HTTP v1 API:
| Tuần | Bước | Chiến lược tăng dần |
|---|---|---|
| 0 | Tăng 1% | Tăng dần từ 0 lên 5.000 RPS đến FCM HTTP v1 trong vòng một giờ. |
| 1 | Tăng 5% | Tăng dần từ 5.000 lên 25.000 RPS trong 2 giờ. |
| 2 | Tăng 10% | Tăng dần từ 25.000 lên 50.000 RPS trong 2 giờ |
| 3 | Tăng 25% | Tăng từ 50.000 lên 125.000 RPS trong 3 giờ |
| 4 | Tăng 50% | Tăng từ 125.000 lên 250.000 RPS trong 6 giờ |
| 5 | Tăng 75% | Tăng từ 250.000 lên 375.000 RPS trong 6 giờ |
| 6 | Tăng 100% | Tăng từ 375.000 lên 500.000 RPS trong 6 giờ |
Kế hoạch khôi phục giả định:
- Nếu độ trễ ở phân vị thứ 95 tăng lên hơn 500 mili giây hoặc nếu tỷ lệ lỗi vượt quá 1% trong hơn một giờ ở bất kỳ bước nào, hãy sử dụng cấu hình động để khôi phục ngay lập tức về bước trước đó.
- Tiếp tục khôi phục về các bước trước đó cho đến khi độ trễ và tỷ lệ lỗi trở về mức danh nghĩa.
Khi nào cần liên hệ với FCM
Liên hệ với FCM thông qua Nhóm hỗ trợ của Firebase nếu bạn gặp phải bất kỳ trường hợp nào sau đây:
- Hạn mức mặc định không còn đáp ứng được trường hợp sử dụng của bạn
- Bạn đang thay đổi mô hình gửi trong khoảng thời gian 3 tháng ở quy mô 100.000 RPS trên toàn cầu hoặc 30.000 RPS trên lục địa.