
初期段階のアプリを拡張する場合でも、トラフィックの多いサービスをすでに実行している場合でも、このガイドの分析情報と推奨事項は、FCM を使用してスムーズにスケーリングするために活用できます。これらのコンセプトと手法は、大量のメッセージを送信する必要がある場合の悪影響の回避に役立ちます。
主な用語と概念
メッセージ リクエスト: FCM メッセージ リクエスト。「リクエスト」、「メッセージ」、「クエリ」と同じ意味で使用されます。
1 秒あたりのリクエスト数(RPS): FCM への受信リクエストのレートを示す指標。秒間クエリ数(QPS)と同じ意味で使用されます。
クォータ トークン、トークン バケット、リフィル: FCM HTTP v1 API に対してメッセージを送信すると、各リクエストは特定の時間枠に割り当てられたクォータ トークンを消費します。このウィンドウ(「トークン バケット」と呼ばれる)は、時間枠の終了時に完全に補充されます。たとえば、HTTP v1 API では、1 分間のトークン バケットごとに 60 万のクォータ トークンが割り当てられます。このトークン バケットは、1 分間の各ウィンドウの終了時に完全に補充されます。
サーバーサイド スロットリング: トラフィック量が FCM サービスの容量を超えると、処理能力を超えるリクエストは拒否され、上り(内向き)フローのレート制限が行われます。一定時間待機してからリクエストを再試行する必要があることを示すために、retry-after ヘッダーを含む 429 エラー レスポンスが返されることがあります。
クライアントサイド スロットリング: クライアントがリクエストの失敗、高レイテンシ、または 429 エラーを検出した場合、輻輳の悪化を回避するために、自発的に下り(外向き)フローのレート制限を行う必要があります。
指数バックオフ: エラーの再試行時に、時間遅延を指数関数的に増やします。例: 1 秒、2 秒、4 秒、8 秒、16 秒、32 秒など。
ジッター: 正確な間隔でのリクエストの再試行を回避します。ジッターでは、ランダムなプロセスで再試行の遅延を変化させ、時間の経過とともに均等に分散させます(例: 0.9 秒、2.3 秒、4.1 秒、8.5 秒、17.9 秒、34.7 秒)。
再試行の増幅: 失敗したリクエストが指数バックオフやジッタリングなしで再試行されると、それらのリクエストが蓄積されて進行中のトラフィック負荷に加わることが多く、トラフィックの輻輳問題を「増幅」して悪化させる可能性があります。
問題: トラフィックの急増
FCM は数百万件の 1 秒あたりリクエスト数(RPS)を処理します。システムの輻輳、レイテンシの問題、サービスの停止の最大の原因はトラフィックの急増です。
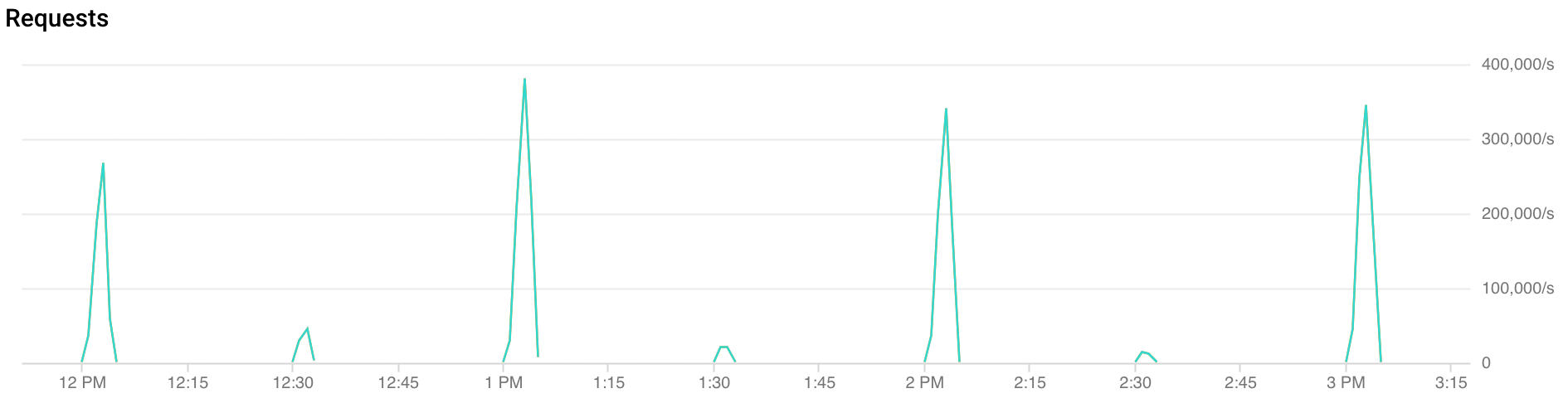
トラフィックの急増とは
トラフィックの急増には、いくつかの種類があります。
正時の急増: FCM は、毎時の最初の 30 秒から 2 分間に 2 倍以上のトラフィックを受信します。同様に、30 分と 15 分の時刻でも、やや少ないものの急増が見られます(例: 00:15、00:30、00:45)。
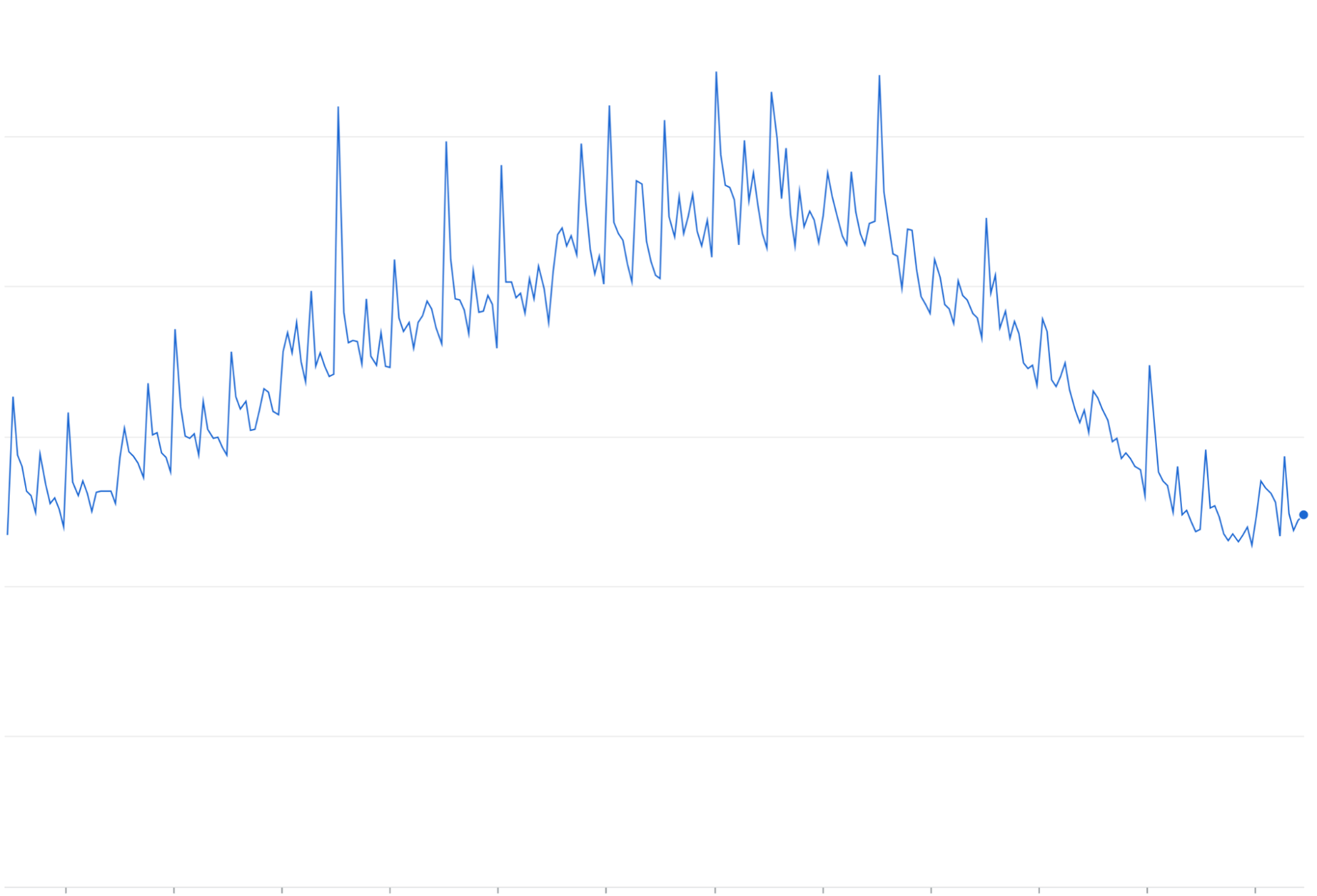
再試行の増幅:指数バックオフのない失敗したリクエストやタイムアウトしたリクエストの再試行は、既存のトラフィックの山の上に繰り返しトラフィックが蓄積される可能性があります。
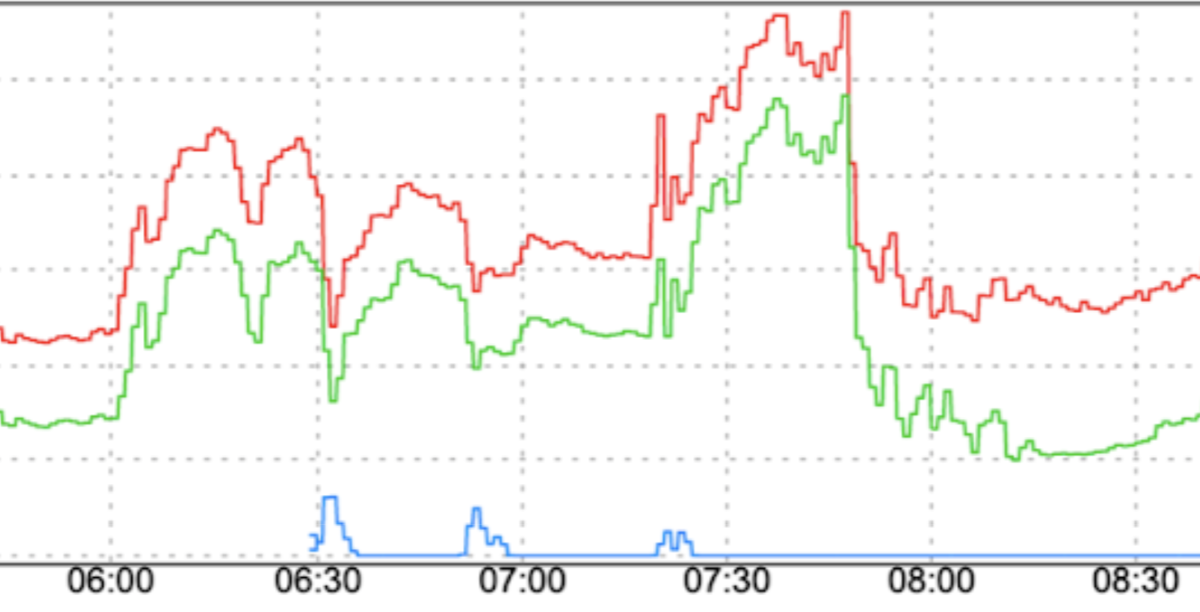
トラフィック パターンの急激な変化: 段階的な増加などの要素を平滑化せずに、新しいトラフィックを FCM に転送したり、リージョン間でトラフィックを FCM に移動したりすると、トラフィックが急増する可能性があります。
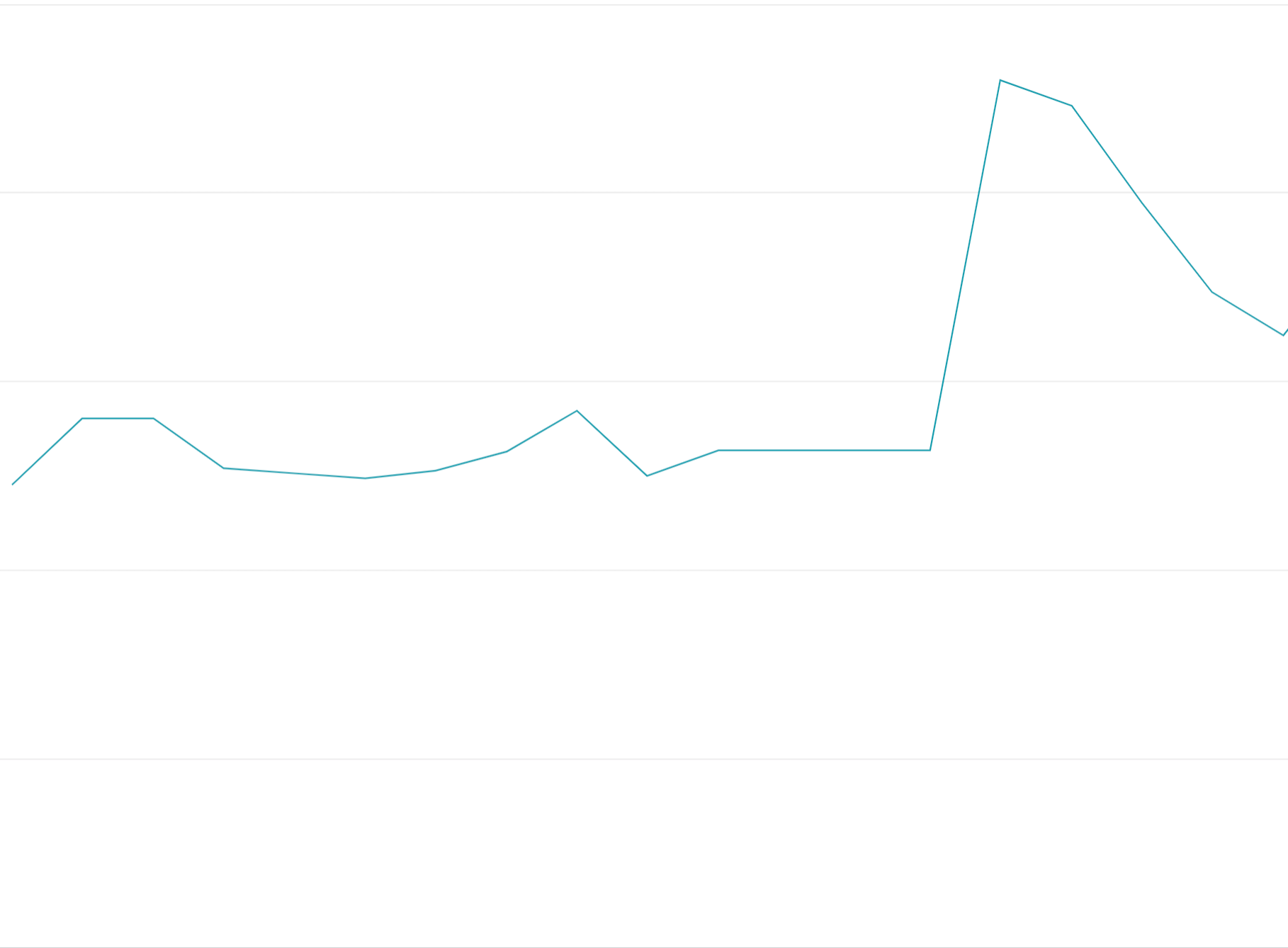
クォータ トークンの使用をフロントローディングする: 割り当てウィンドウ全体にリクエストを均等に分散するのではなく、割り当てウィンドウの開始時にすべてのクォータ トークンを使い切ると、ウィンドウではオンオフの変動が発生し、ロードバランスが困難で高コストになります。
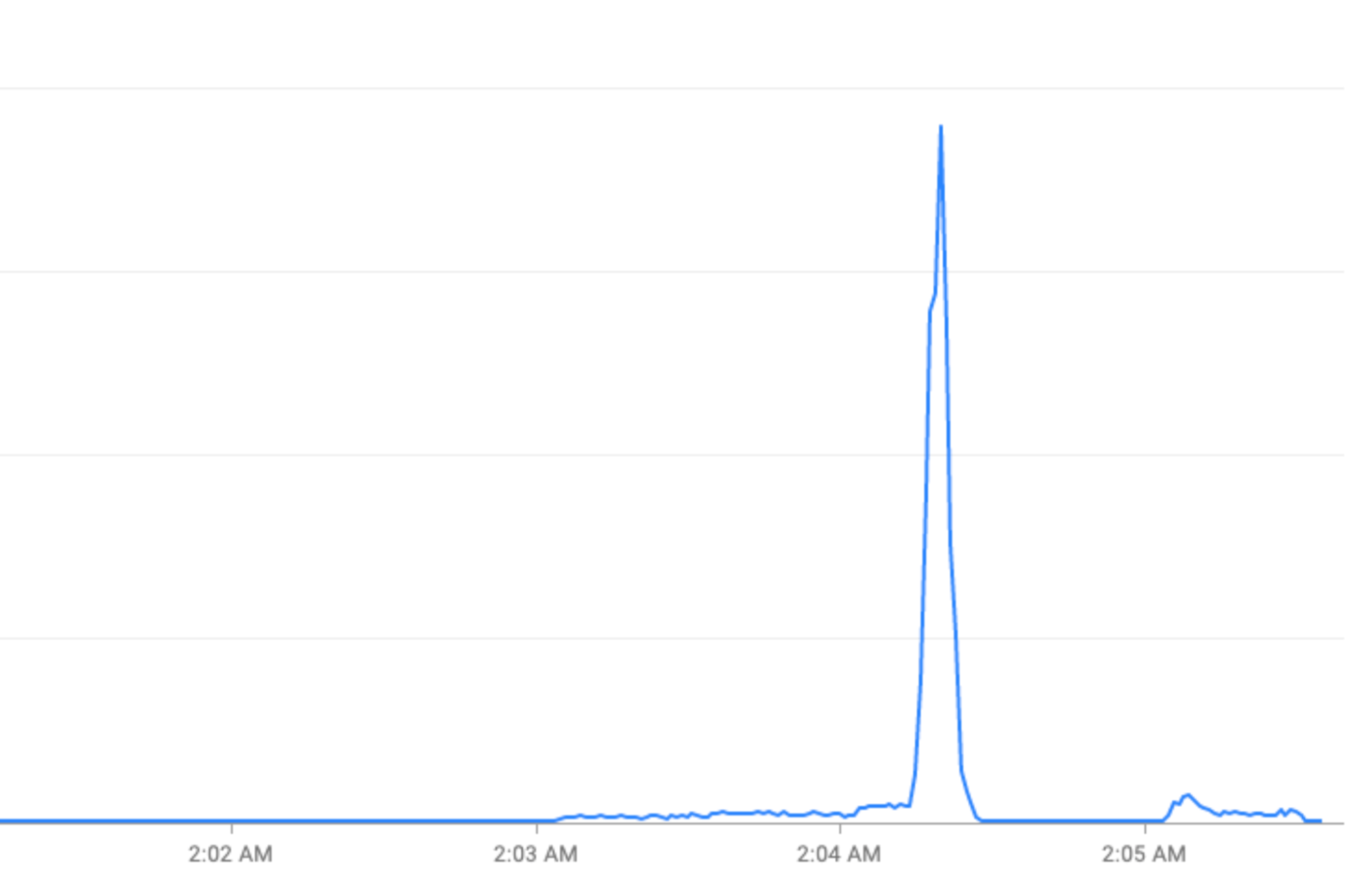
特別なイベント: 休日(大晦日など)やスポーツ イベント(FIFA ワールドカップなど)時にはトラフィックが急増します。
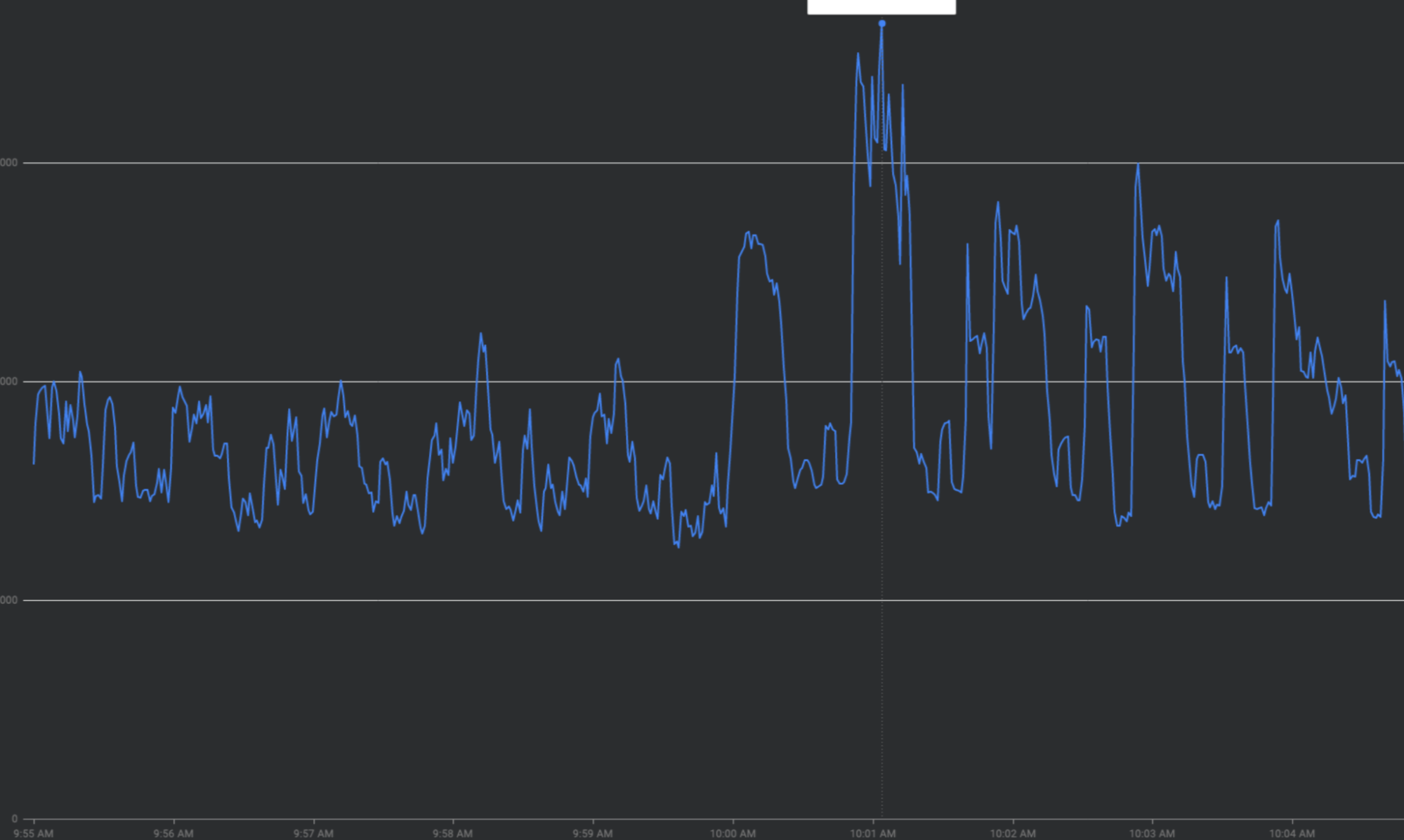
「曲線を平坦化」してトラフィックの急増に対処する
このセクションでは、トラフィックの急増を可能な限り平滑化するための戦略、つまり「曲線を平坦化する」方法について説明します。
適切なユースケースにのみ FCM を使用する
ユースケースによっては、FCM を使用した通知の配信が必要でない、または適切でない場合もあります。
たとえば、カレンダーの予定の通知の場合、アプリサーバーから通知を送信するのではなく、適切な時間に通知を表示するようにアプリ内のローカルタスクをスケジュールできます。FCM メッセージをカレンダー同期に限定します。
急増を回避する
スケーリングのアンチパターンの 1 つは、サーバーサイド スロットリングを適用せずに、システムが許す限り迅速に FCM 通知を送信することです。次の点を考慮してください。
- すべての顧客が 1 分以内に同じ通知をすべて受け取る必要がありますか?たとえば、配信時間が 5 分でもビジネスニーズは満たされますか?
- 顧客を優先度に基づいてセグメント化して、急増を緩和できますか?
- 通知を事前にスケジュール設定することはできますか?
可能な限り: FCM 送信割り当てをすぐに使い果たしてしまうような戦略は避け、トークン バケットが補充されたらすぐにパターンを繰り返すようにします。このアクセス パターンにより、FCM とその依存システムでロード バランシングの問題が発生します。トラフィックをできるだけ緩やかに増加させます。少なくとも、60 秒の時間枠で 0 から最大 RPS まで徐々に増やします。RPS が大きいほど、ウィンドウを長くします。
「正時の」トラフィックを回避する
可能な場合: :00、:15、:30、:45 の各時刻から 2 分以内にメッセージを送信しないようにします。
サーバーサイド スロットリングを実装する
サーバーサイド スロットリングを実装して、FCM へのトラフィック フローをモニタリングし、管理します。
再試行の処理
FCM では高可用性の確保を目指していますが、リクエストによってはタイムアウトになったり、失敗したりすることがあります。理由はさまざまですが、次のベスト プラクティスは、トラフィックの輻輳への影響を最小限に抑えながら、メッセージをできるだけ早く配信できるように再試行の動作を最適化します。
タイムアウト
再試行する前に、送信リクエストに少なくとも 10 秒のタイムアウトを設定します。FCM の内部リモート プロシージャ コールのほとんどで 10 秒のタイムアウトを使用します。
エラー
- 400、401、403、404 エラーの場合: 中止し、再試行しないでください。
- 429 エラーの場合: try-after ヘッダーで設定されている時間が経過した後で再試行します。retry-after ヘッダーが設定されていない場合、デフォルトは 60 秒です。
- 500 エラーの場合: 指数バックオフを使って再試行します。
指数バックオフ
再試行の増幅を回避するには、リクエストの再試行にジッターを伴う指数バックオフを実装します。たとえば、Firebase Admin SDK では指数バックオフが実装されます。
推奨される設定を次に示します。
- 最小間隔: 失敗したリクエストを FCM ですぐに再試行しないでください。10 秒以上待ってから、失敗したリクエストを再試行します。
- 最大間隔: 期限が過ぎたリクエストを無限に再試行するのではなく、破棄するための最大間隔を設定します。
指数バックオフを使ってリクエストを繰り返し再試行しても、60 分後にまだ失敗する場合は、再試行可能なエラーとして誤って分類されているか、FCM でサービスが停止が発生している状況で、再試行が意図せずに状況を悪化させている可能性があります。
ロールアウトとロールバックの計画を作成し、段階的に変更する
FCM へのトラフィックの増加や、リージョンやネットワーク間のトラフィックのシフトなど、大規模なトラフィック変更を行う場合、ロールアウト / ロールバック計画を設計し、段階的な変更を実装することで、ユーザー、サービス、FCM を保護できます。
- ロールアウト計画で関係者の期待を調整します。特定の状況(以下で説明)では、予想外の事態を避けるために、事前に FCM チームとロールアウト計画を共有することをおすすめします。
- ロールバック計画により、不測の事態に備え、予期しない障害から迅速かつ安全に復旧するためのメカニズムを準備できます。
- 段階的な変更には、次の 2 つの側面があります。
- 「段階的な」増加: ステップは 1% -> 5% -> 10% -> 25% -> 50% -> 75% -> 100%、またはそれよりも細かくします。1 日~1 週間、各ステップで「ソーク」(負荷がかかった状態でシステムの動作を観察)します。これにより、あるステップから次にステップに進む前に潜在的な問題を特定できます。
- 段階的なトラフィック増加: トラフィックを増加させる各「ステップ」を行う場合、少なくとも 1 時間はトラフィックを平滑化します。これにより、FCM のロード バランシング インフラストラクチャは、ホットスポットや輻輳の可能性を最小限に抑えながら、新しいトラフィックを適切にスケーリングできます。
ここでは、500,000 RPS を FCM レガシー HTTP API から FCM HTTP v1 API にグローバルに移行する架空のシナリオを示します。
| Week | ステップ | 段階的な増加の戦略 |
|---|---|---|
| 0 | 1% 増加 | 1 時間かけて FCM HTTP v1 に対して 0 RPS から 5,000 RPS にスムーズに増加させます。 |
| 1 | 5% 増加 | 2 時間で 5,000 RPS から 25,000 RPS にスムーズに増加させます。 |
| 2 | 10% 増加 | 2 時間で 25,000 RPS から 50,000 RPS にスムーズに増加させます |
| 3 | 25% 増加 | 3 時間で 50,000 RPS から 125,000 RPS に増加させます |
| 4 | 50% 増加 | 6 時間で 125,000 RPS から 250,000 RPS に増加させます |
| 5 | 75% 増加 | 6 時間で 250,000 RPS から 375,000 RPS に増加させます |
| 6 | 100% 増加 | 6 時間で 375,000 RPS から 500,000 RPS に増加させます |
架空のロールバック プラン:
- 95 パーセンタイルのレイテンシが 500 ミリ秒を超えて増加した場合、またはいずれかのステップでエラー率が 1 時間を超えて 1% を超過した場合には、動的構成を使用して直ちに前のステップにロールバックします。
- レイテンシとエラー率が公称レベルに戻るまで、前のステップにロールバックすることを続けます。
FCM へのお問い合わせの場合
次のいずれかに該当する場合、Firebase サポートを通じて FCM にお問い合わせください。
- デフォルトの割り当てがユースケースに合わなくなった
- グローバルで 100,000 RPS、大陸で 30,000 RPS のスケールで 3 か月以内に送信パターンを変更する。