
Ya sea que estés desarrollando una app reciente o ejecutando un servicio de tráfico alto, puedes beneficiarte de las estadísticas y recomendaciones de esta guía sobre cómo escalar sin problemas con FCM. Estos conceptos y prácticas pueden ayudarte a evitar efectos negativos cuando necesitas enviar grandes volúmenes de mensajes.
Términos y conceptos clave
Solicitud de mensaje: Es una solicitud de mensaje de FCM. Se usa indistintamente con “solicitud”, “mensaje” o “consulta”.
Solicitudes por segundo (RPS): Es una métrica para describir la tasa de solicitudes entrantes a FCM. Se usan indistintamente con las consultas por segundo (QPS).
Tokens de cuota, buckets de tokens y recargas: Cuando se envían mensajes con la API de FCM HTTP v1, cada solicitud consume un token de cuota asignado en un período determinado. Este período, llamado “Bucket de tokens”, se rellena por completo al final del período. Por ejemplo, la API de HTTP v1 asigna 600,000 tokens de cuota para cada bucket de tokens de 1 minuto, que se vuelve a llenar al final de cada período de 1 minuto.
Limitación del servidor: Cuando el volumen de tráfico supera la capacidad
del servicio de FCM, las solicitudes que superan la capacidad de entrega se rechazan para limitar la frecuencia
del flujo de entrada. Es posible que se devuelvan respuestas de error 429 con encabezados retry-after para indicar que debes esperar un período determinado antes de reintentar la solicitud.
Limitación del cliente: Cuando los clientes observan fallas de solicitudes, latencia alta o errores de 429, deben limitar de forma voluntaria el flujo de salida para evitar exacerbar la congestión.
Retirada exponencial: Cuando reintentes errores, agrega retrasos de tiempo que aumentan de forma exponencial. Por ejemplo: 1 s, 2 s, 4 s, 8 s, 16 s, 32 s, etcétera.
Jittering: Evita reintentar las solicitudes en intervalos exactos. Con el jitter, puedes variar los retrasos de reintento a través de un proceso aleatorio para distribuirlos de manera uniforme con el tiempo (por ejemplo: 0.9 s, 2.3 s, 4.1 s, 8.5 s, 17.9 s y 34.7 s).
Amplificación de reintento: Cuando se reintentan las solicitudes fallidas sin retirada exponencial ni jitter, a menudo se acumulan y aumentan la carga de tráfico continua, lo que podría “amplificar” y exacerbar los problemas de congestión de tráfico.
El problema: aumentos repentinos de tráfico
FCM procesa millones de solicitudes por segundo (RPS). Los aumentos repentinos de tráfico son el principal factor que más contribuye a la congestión sistémica, los problemas de latencia y las interrupciones.
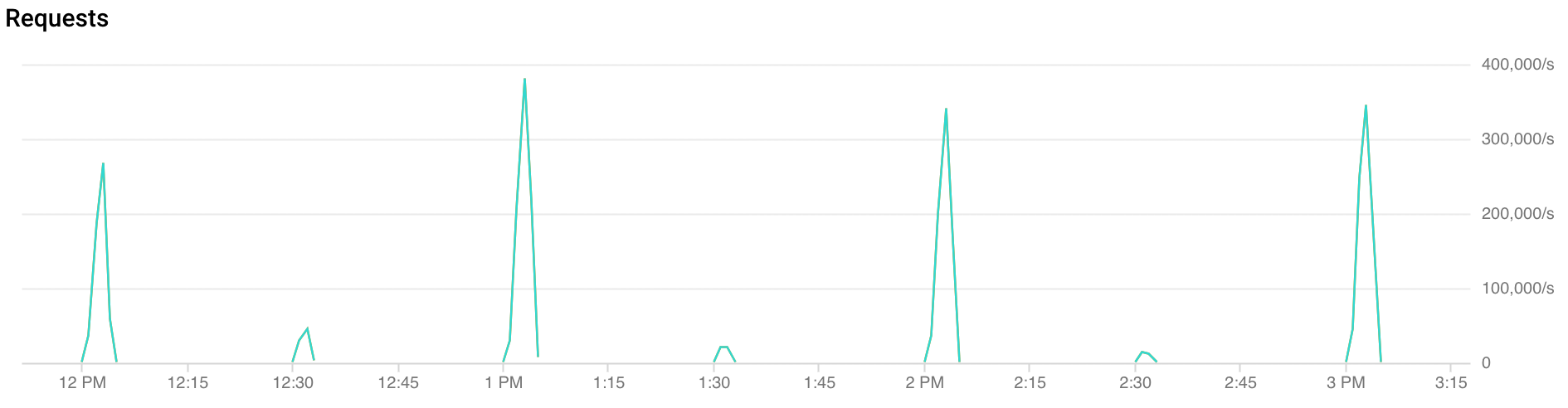
¿Qué es un aumento repentino de tráfico?
Existen varios tipos diferentes de aumentos repentinos de tráfico.
Aumentos repentinos en horarios: FCM recibe más del doble de tráfico durante los primeros 30 segundos a 2 minutos de cada hora. También se observan aumentos repentinos similares, aunque menores, en las marcas de media hora y cuarto de hora (por ejemplo: 00:15, 00:30 y 00:45).
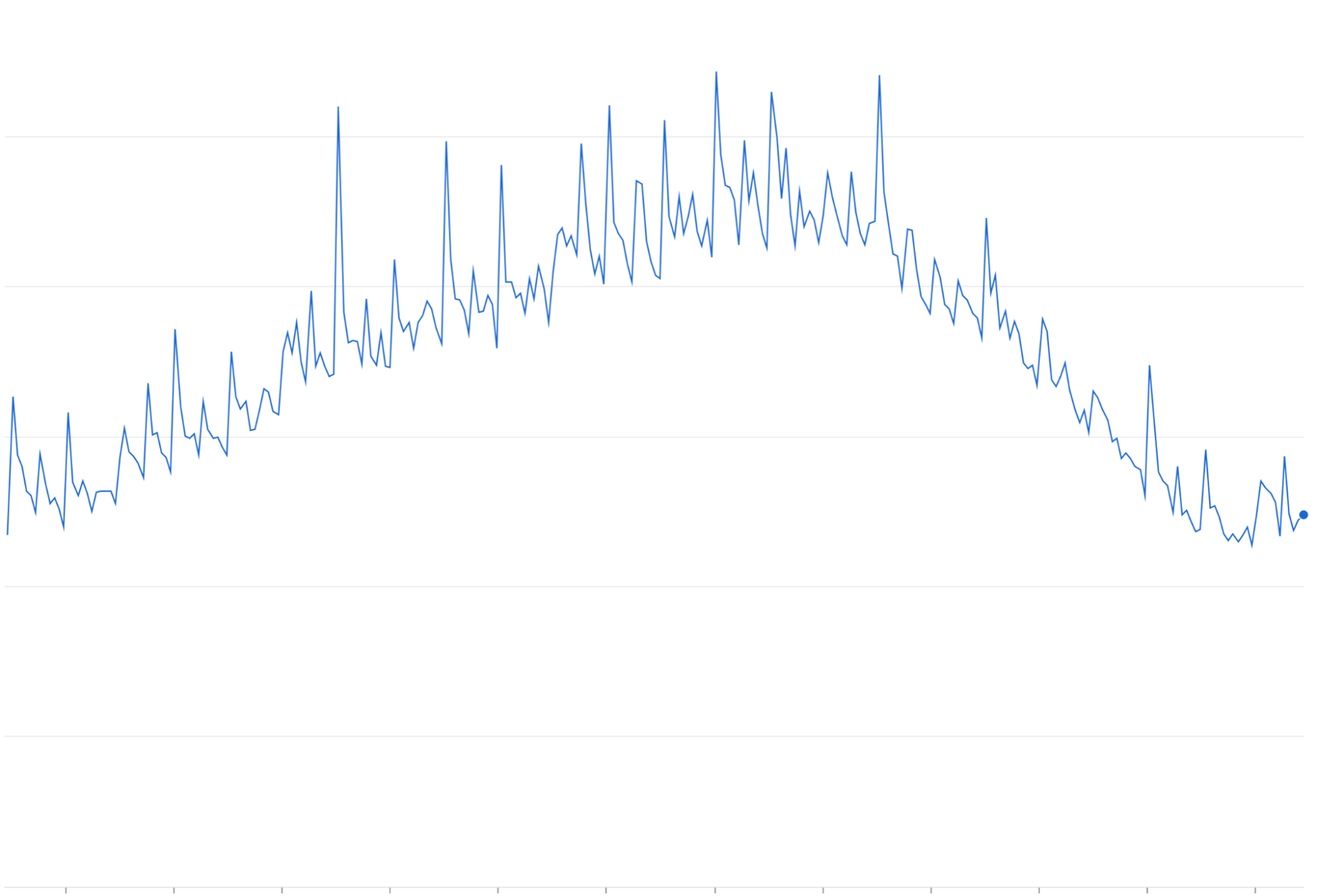
Reintenta la amplificación: Volver a intentar las solicitudes fallidas o que agotaron el tiempo de espera sin retirada exponencial puede acumularse en oleadas de tráfico repetidas sobre los aumentos de tráfico existentes.
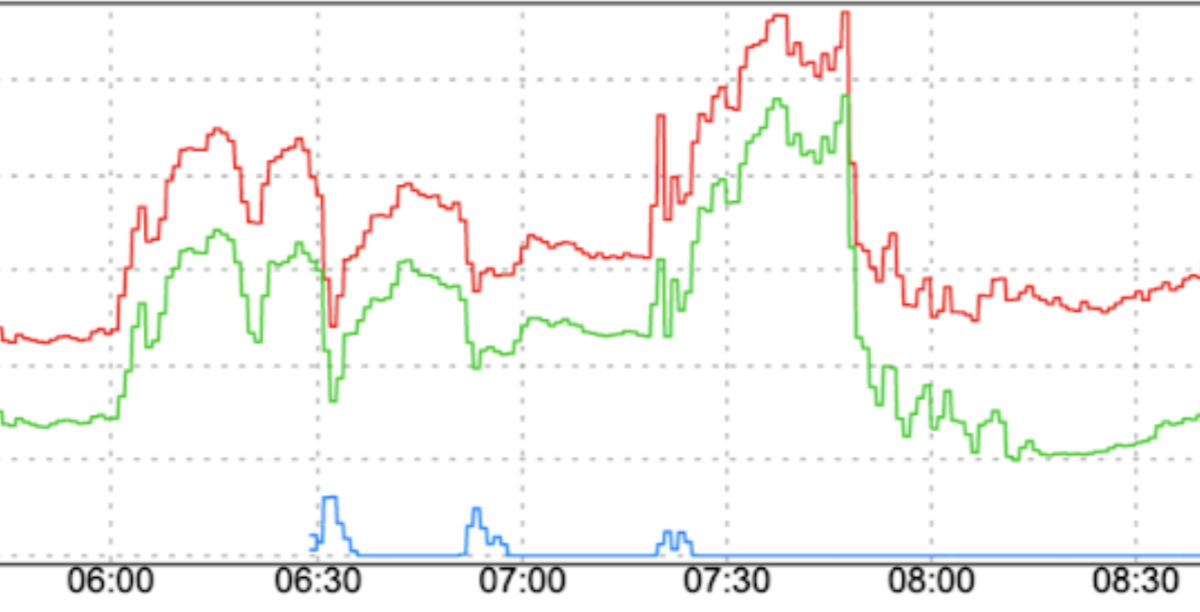
Cambios abruptos en el patrón de tráfico: Dirigir el tráfico nuevo a FCM o trasladar el tráfico a FCM entre regiones sin suavizar factores, como el aumento gradual, puede causar aumentos repentinos.
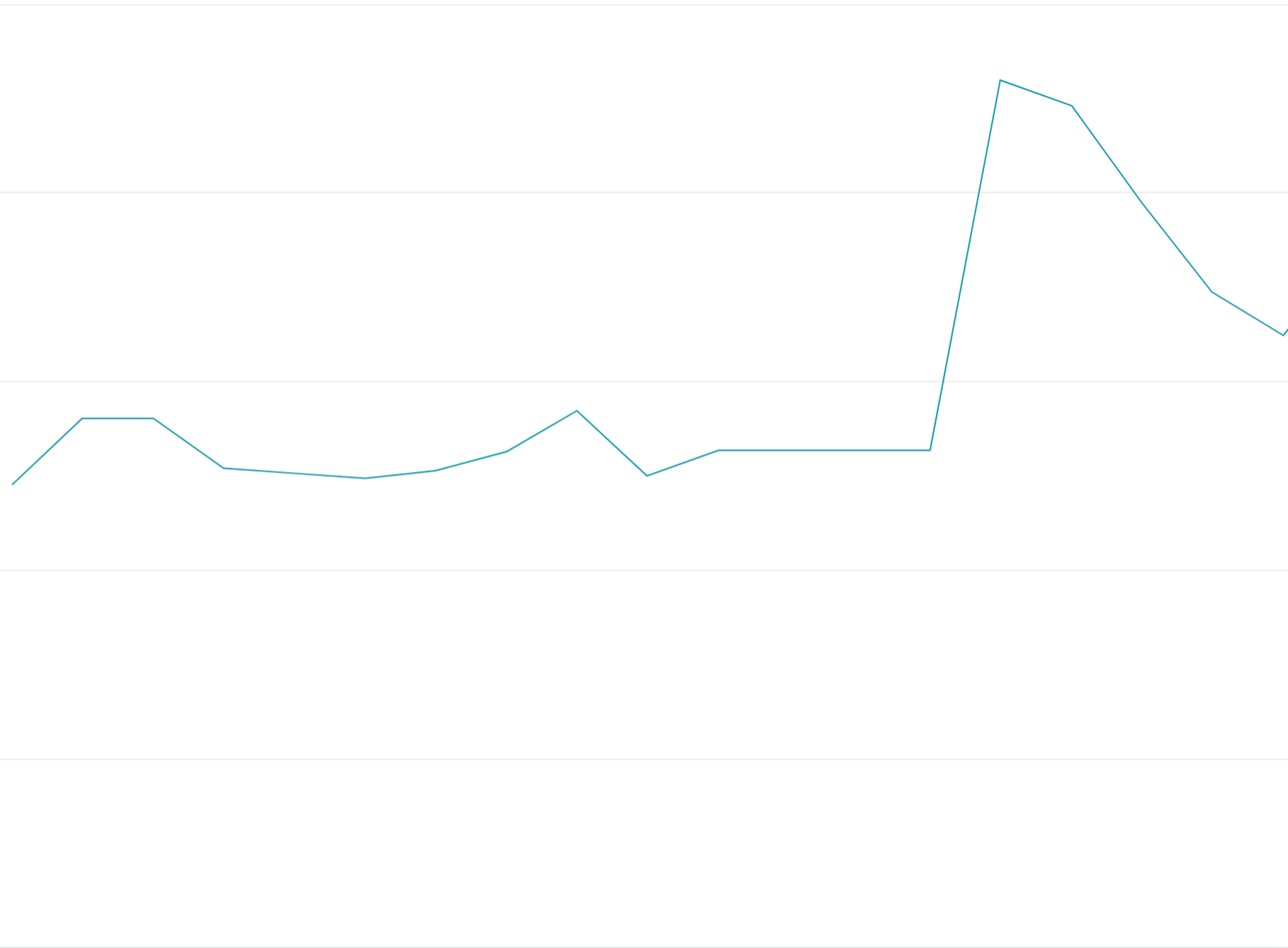
Uso de tokens de cuota de carga decreciente: Si agotas todos los tokens de cuota al inicio de los períodos de cuota, en lugar de distribuir las solicitudes de manera uniforme entre las ventanas de cuota, se crearán oscilaciones de activación que son difíciles y costosas para balancear cargas.
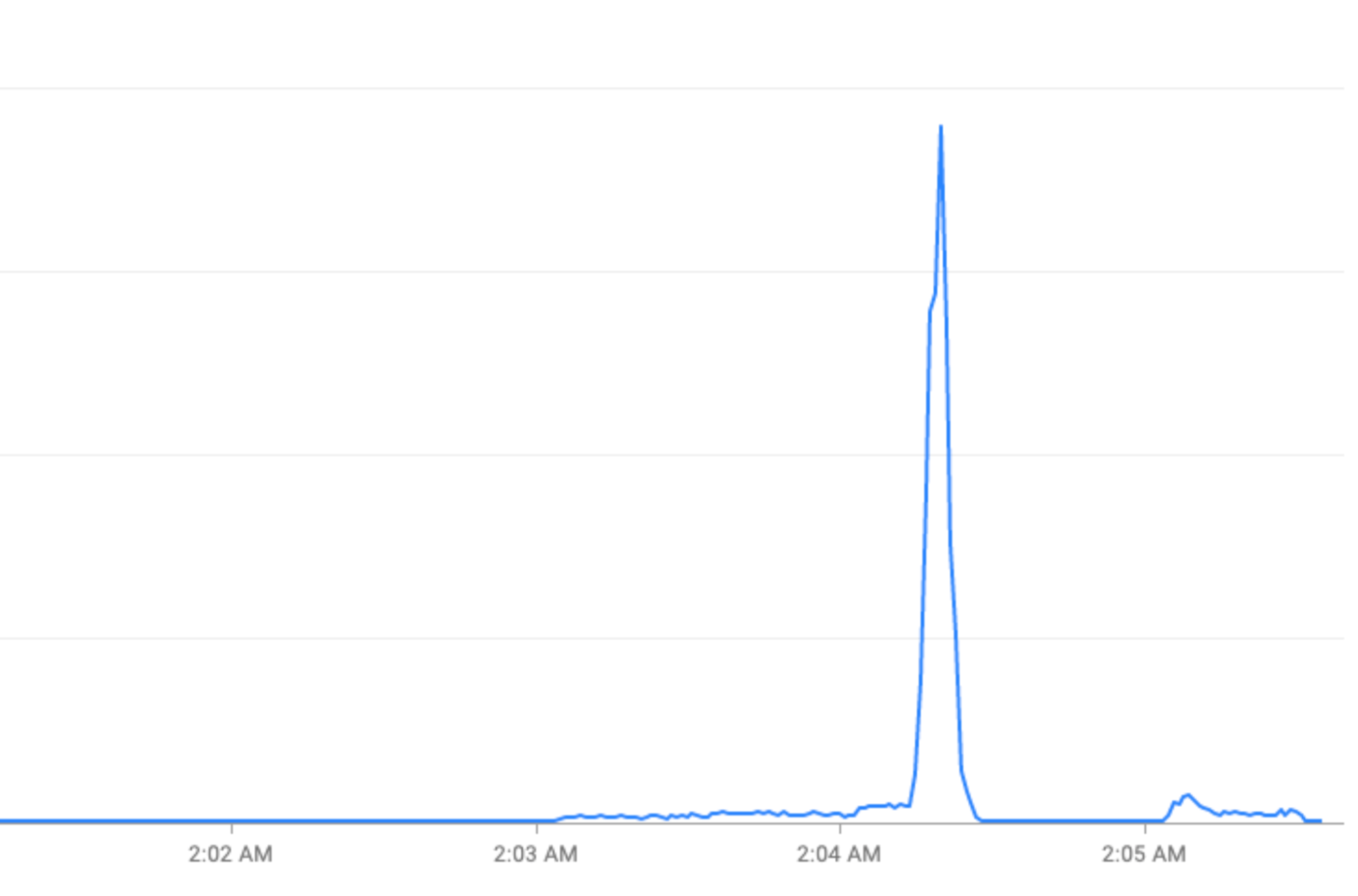
Eventos especiales: El tráfico aumenta repentinamente durante las festividades (víspera de Año Nuevo) o eventos deportivos (Copa Mundial de la FIFA).
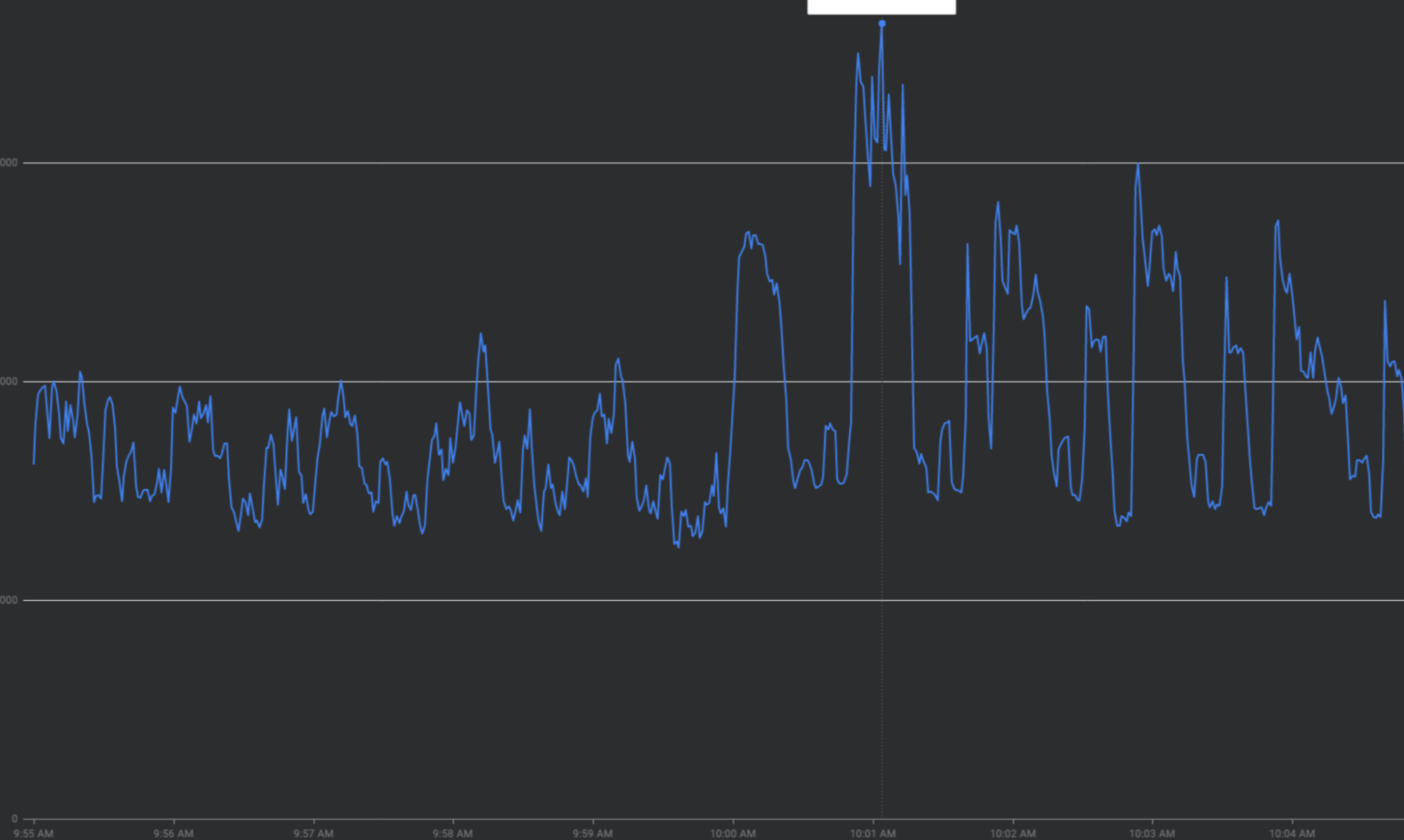
Soluciona los aumentos repentinos de tráfico “aplanando la curva”
En esta sección, se describen las estrategias para reducir los aumentos repentinos de tráfico siempre que sea posible, es decir, estrategias para “aplanar la curva”.
Usa FCM solo para los casos de uso adecuados
Hay algunos casos de uso en los que no es necesario ni apropiado usar FCM para enviar una notificación.
Por ejemplo, en el caso de las notificaciones de eventos de calendario, puedes programar una tarea local en tu app para que muestre una notificación en los momentos adecuados en lugar de enviarla desde tu servidor de apps. Limita los mensajes de FCM a las sincronizaciones de calendario.
Evita los aumentos repentinos de tráfico
Un antipatrón de escalamiento es enviar notificaciones de FCM tan rápido como lo permitan los sistemas, en lugar de aplicar una limitación del servidor. Ten en cuenta lo siguiente:
- ¿Todos tus clientes necesitan recibir la misma notificación en un período de 1 minuto? Por ejemplo, ¿un plazo de entrega de 5 minutos satisfaría las necesidades de tu empresa?
- ¿Es posible segmentar a tus clientes en función de la prioridad para suavizar los aumentos repentinos?
- ¿Puedes programar las notificaciones con anticipación?
Siempre que sea posible, evita las estrategias que agoten de inmediato tu cuota de envío de FCM. Solo debes repetir el patrón en cuanto se vuelva a cargar tu bucket de tokens. Este patrón de acceso crea problemas de balanceo de cargas para FCM y sus sistemas dependientes. Aumenta el tráfico de la manera más gradual posible. Como mínimo, aumenta de 0 a la cantidad máxima de RPS en un período de 60 segundos. Prefiere períodos más largos para un RPS más alto.
Evita el tráfico “en horario”
Cuando sea posible, evita enviar mensajes en una ventana de 2 minutos después de cada una de las marcas de minuto :00, :15, :30 y :45.
Implementa la limitación del servidor
Implementa la limitación del servidor para supervisar y administrar el flujo de tráfico a FCM.
Administra los reintentos
Si bien FCM se esfuerza por ofrecer alta disponibilidad, a veces se agota el tiempo de espera de algunas solicitudes o fallan. Si bien los motivos varían, las siguientes prácticas recomendadas optimizan el comportamiento de reintento para entregar mensajes lo antes posible y, a la vez, minimizar el impacto en la congestión del tráfico.
Tiempos de espera
Establece un tiempo de espera de al menos 10 segundos en las solicitudes de envío antes de reintentarlo. La mayoría de las llamadas de procedimiento remoto internas de FCM usan un tiempo de espera de 10 segundos.
Errores
- En el caso de los errores 400, 401, 403 y 404, anula la operación y no vuelvas a intentarlo.
- En el caso de los errores 429, vuelve a intentarlo después de esperar la duración establecida en el encabezado de reintentos posteriores. Si no se establece un encabezado de reintento posterior, la configuración predeterminada será de 60 segundos.
- En caso de errores del tipo 500, vuelve a intentarlo con una retirada exponencial.
Retirada exponencial
Para evitar la amplificación de reintentos, implementa una retirada exponencial con jitter para reintentar las solicitudes. El SDK de Firebase Admin, por ejemplo, implementa una retirada exponencial.
A continuación, se incluyen otros parámetros de configuración recomendados:
- Intervalo mínimo: No vuelvas a intentar de inmediato una solicitud con errores con FCM. Espera al menos 10 segundos antes de reintentar una solicitud con errores.
- Intervalo máximo: Establece un intervalo máximo para descartar las solicitudes que ya no son oportunas, en lugar de reintentarlo de manera indefinida.
Si una solicitud se reintenta de forma continua con una retirada exponencial y continúa fallando después de 60 minutos, se clasifica de forma incorrecta como un error que se puede intentar de nuevo o como si FCM está experimentando una interrupción en la que los reintentos pueden exacerbar la situación de forma involuntaria.
Crea planes de lanzamiento y reversión, y realiza cambios graduales
Cuando realices cambios de tráfico a gran escala, como aumentar el tráfico a FCM o cambiar el tráfico entre regiones o redes, diseñar un plan de lanzamiento o reversión, y también implementar cambios graduales protegerá a los usuarios, tu servicio y FCM.
- Un plan de lanzamiento alinea las expectativas para las partes interesadas. En algunas situaciones (que se analizan a continuación), te recomendamos que compartas tu plan de lanzamiento con anticipación con el equipo de FCM para evitar sorpresas.
- Un plan de reversión te permite considerar las contingencias y preparar mecanismos para recuperarte de manera rápida y segura de fallas imprevistas.
- Realizar cambios graduales tiene dos aspectos:
- Aumentos “paso a paso”: los pasos deben ser de 1% -> 5% -> 10% -> 25% -> 50% -> 75% -> 100% o deben ser más precisos. “Inmersión” (se observa el comportamiento del sistema bajo carga) en cada paso durante 1 día a 1 semana. Esto te permite detectar posibles problemas antes del próximo paso a paso.
- Aumentos graduales del tráfico: Cuando realices cada “paso” para aumentar el tráfico, suaviza el tráfico durante al menos una hora. Esto permite que la infraestructura de balanceo de cargas de FCM escale de forma adecuada el tráfico nuevo y, al mismo tiempo, minimiza el potencial de hotspots y congestión.
A continuación, se presenta una situación hipotética para migrar 500,000 RPS a nivel global de la API de HTTP heredada de FCM a la API de HTTP v1 de FCM:
| Semana | Step | Estrategia de aumento gradual |
|---|---|---|
| 0 | 1% de aumento de volumen gradual | Realiza ajustes sin problemas de 0 a 5,000 RPS a FCM HTTP v1 en el transcurso de una hora. |
| 1 | 5% de aumento de volumen gradual | Realiza ajustes sin problemas de 5,000 a 25,000 RPS durante 2 horas. |
| 2 | 10% de aumento de volumen gradual | Aumento sin problemas de 25,000 a 50,000 RPS durante 2 horas |
| 3 | 25% de aumento de volumen gradual | Aumento de 50,000 a 125,000 RPS durante 3 horas |
| 4 | 50% de aumento de volumen gradual | Aumento de 125,000 a 250,000 RPS durante 6 horas |
| 5 | 75% de aumento de volumen gradual | Aumento de 250,000 a 375,000 RPS durante 6 horas |
| 6 | 100% de aumento de volumen gradual | Aumento de 375,000 a 500,000 RPS durante 6 horas |
Plan de reversión hipotético:
- Si la latencia del percentil 95 aumenta a más de 500 ms o si la proporción de errores supera el 1% durante más de una hora en algún paso, usa la configuración dinámica para volver al paso anterior de inmediato.
- Continúa con las reversiones a los pasos anteriores hasta que la latencia y la proporción de errores vuelvan a los niveles nominales.
Cuándo comunicarse con FCM
Comunícate con FCM a través de la Asistencia de Firebase si se cumple alguna de las siguientes condiciones:
- Las cuotas predeterminadas ya no se ajustan a tu caso de uso.
- Cambias tus patrones de envío en un período de 3 meses a una escala de 100,000 RPS a nivel global o 30,000 RPS a nivel continental.