
La ejecución de código es una herramienta que permite que el modelo genere y ejecute código de Python. El modelo puede aprender de forma iterativa a partir de los resultados de la ejecución del código hasta llegar a un resultado final.
Puedes usar la ejecución de código para crear funciones que se beneficien del razonamiento basado en código y que generen resultados de texto. Por ejemplo, puedes usar la ejecución de código para resolver ecuaciones o procesar texto. También puedes usar las bibliotecas incluidas en el entorno de ejecución de código para realizar tareas más especializadas.
Al igual que con todas las herramientas que le proporcionas al modelo, este decide cuándo usar la ejecución de código.
Ir a la implementación de código
Comparación entre la ejecución de código y la llamada a funciones
La ejecución de código y la llamada a funciones son funciones similares. En general, deberías preferir usar la ejecución de código si el modelo puede controlar tu caso de uso. La ejecución de código también es más fácil de usar porque solo debes habilitarla.
Estas son algunas diferencias adicionales entre la ejecución de código y la llamada a funciones:
| Ejecución de código | Llamada a función |
|---|---|
| Usa la ejecución de código si quieres que el modelo escriba y ejecute código de Python por ti y devuelva el resultado. | Usa la llamada a funciones si ya tienes tus propias funciones que deseas ejecutar de forma local. |
| La ejecución de código permite que el modelo ejecute código en el backend de la API en un entorno fijo y aislado. | La llamada a funciones te permite ejecutar las funciones que solicita el modelo en el entorno que desees. |
| La ejecución de código se resuelve en una sola solicitud. Si bien puedes usar la ejecución de código con la capacidad de chat de forma opcional, no es un requisito. | La llamada a función requiere una solicitud adicional para devolver el resultado de cada llamada a función. Por lo tanto, debes usar la función de chat. |
Modelos compatibles
gemini-3.1-pro-previewgemini-3.5-flashgemini-3.1-flash-litegemini-2.5-progemini-2.5-flashgemini-2.5-flash-lite
Usar la ejecución de código
Puedes usar la ejecución de código con entradas multimodales y solo de texto, pero la respuesta siempre será solo de texto o código.
Antes de comenzar
|
Haz clic en tu proveedor de Gemini API para ver el contenido y el código específicos del proveedor en esta página. |
Si aún no lo has hecho, completa la guía de introducción, en la que se describe cómo configurar tu proyecto de Firebase, conectar tu app a Firebase, agregar el SDK, inicializar el servicio de backend para el proveedor de Gemini API que elijas y crear una instancia de GenerativeModel.
Para probar y, luego, iterar tus instrucciones, te recomendamos usar Google AI Studio.
Habilita la ejecución de código
|
Antes de probar esta muestra, completa la sección
Antes de comenzar de esta guía
para configurar tu proyecto y tu app. En esa sección, también harás clic en un botón para el proveedor de Gemini API que elijas, de modo que veas contenido específico del proveedor en esta página. |
Cuando crees la instancia de GenerativeModel, proporciona CodeExecution como una herramienta que el modelo puede usar para generar su respuesta. Esto permite que el modelo genere y ejecute código de Python.
Swift
import FirebaseAILogic
// Initialize the Gemini Developer API backend service.
let ai = FirebaseAI.firebaseAI(backend: .googleAI())
// Create a `GenerativeModel` instance with a model that supports your use case
let model = ai.generativeModel(
modelName: "GEMINI_MODEL_NAME",
// Provide code execution as a tool that the model can use to generate its response.
tools: [.codeExecution()]
)
let prompt = """
What is the sum of the first 50 prime numbers?
Generate and run code for the calculation, and make sure you get all 50.
"""
let response = try await model.generateContent(prompt)
guard let candidate = response.candidates.first else {
print("No candidates in response.")
return
}
for part in candidate.content.parts {
if let textPart = part as? TextPart {
print("Text = \(textPart.text)")
} else if let executableCode = part as? ExecutableCodePart {
print("Code = \(executableCode.code), Language = \(executableCode.language)")
} else if let executionResult = part as? CodeExecutionResultPart {
print("Outcome = \(executionResult.outcome), Result = \(executionResult.output ?? "no output")")
}
}
Kotlin
// Initialize the Gemini Developer API backend service.
// Create a `GenerativeModel` instance with a model that supports your use case.
val model = Firebase.ai(backend = GenerativeBackend.googleAI()).generativeModel(
modelName = "GEMINI_MODEL_NAME",
// Provide code execution as a tool that the model can use to generate its response.
tools = listOf(Tool.codeExecution())
)
val prompt = "What is the sum of the first 50 prime numbers? " +
"Generate and run code for the calculation, and make sure you get all 50."
val response = model.generateContent(prompt)
response.candidates.first().content.parts.forEach {
if(it is TextPart) {
println("Text = ${it.text}")
}
if(it is ExecutableCodePart) {
println("Code = ${it.code}, Language = ${it.language}")
}
if(it is CodeExecutionResultPart) {
println("Outcome = ${it.outcome}, Result = ${it.output}")
}
}
Java
// Initialize the Gemini Developer API backend service.
// Create a `GenerativeModel` instance with a model that supports your use case.
GenerativeModel ai = FirebaseAI.getInstance(GenerativeBackend.googleAI())
.generativeModel("GEMINI_MODEL_NAME",
null,
null,
// Provide code execution as a tool that the model can use to generate its response.
List.of(Tool.codeExecution()));
// Use the GenerativeModelFutures Java compatibility layer which offers
// support for ListenableFuture and Publisher APIs
GenerativeModelFutures model = GenerativeModelFutures.from(ai);
String text = "What is the sum of the first 50 prime numbers? " +
"Generate and run code for the calculation, and make sure you get all 50.";
Content prompt = new Content.Builder()
.addText(text)
.build();
ListenableFuture response = model.generateContent(prompt);
Futures.addCallback(response, new FutureCallback() {
@Override
public void onSuccess(GenerateContentResponse response) {
// Access the first candidate's content parts
List parts = response.getCandidates().get(0).getContent().getParts();
for (Part part : parts) {
if (part instanceof TextPart) {
TextPart textPart = (TextPart) part;
System.out.println("Text = " + textPart.getText());
} else if (part instanceof ExecutableCodePart) {
ExecutableCodePart codePart = (ExecutableCodePart) part;
System.out.println("Code = " + codePart.getCode() + ", Language = " + codePart.getLanguage());
} else if (part instanceof CodeExecutionResultPart) {
CodeExecutionResultPart resultPart = (CodeExecutionResultPart) part;
System.out.println("Outcome = " + resultPart.getOutcome() + ", Result = " + resultPart.getOutput());
}
}
}
@Override
public void onFailure(Throwable t) {
t.printStackTrace();
}
}, executor);
Web
import { initializeApp } from "firebase/app";
import { getAI, getGenerativeModel, GoogleAIBackend } from "firebase/ai";
// TODO(developer) Replace the following with your app's Firebase configuration
// See: https://firebase.google.com/docs/web/learn-more#config-object
const firebaseConfig = {
// ...
};
// Initialize FirebaseApp
const firebaseApp = initializeApp(firebaseConfig);
// Initialize the Gemini Developer API backend service.
const ai = getAI(firebaseApp, { backend: new GoogleAIBackend() });
// Create a `GenerativeModel` instance with a model that supports your use case.
const model = getGenerativeModel(
ai,
{
model: "GEMINI_MODEL_NAME",
// Provide code execution as a tool that the model can use to generate its response.
tools: [{ codeExecution: {} }]
}
);
const prompt = "What is the sum of the first 50 prime numbers? " +
"Generate and run code for the calculation, and make sure you get all 50."
const result = await model.generateContent(prompt);
const response = await result.response;
const parts = response.candidates?.[0].content.parts;
if (parts) {
parts.forEach((part) => {
if (part.text) {
console.log(`Text: ${part.text}`);
} else if (part.executableCode) {
console.log(
`Code: ${part.executableCode.code}, Language: ${part.executableCode.language}`
);
} else if (part.codeExecutionResult) {
console.log(
`Outcome: ${part.codeExecutionResult.outcome}, Result: ${part.codeExecutionResult.output}`
);
}
});
}
Dart
import 'package:firebase_core/firebase_core.dart';
import 'package:firebase_ai/firebase_ai.dart';
import 'firebase_options.dart';
// Initialize FirebaseApp
await Firebase.initializeApp(
options: DefaultFirebaseOptions.currentPlatform,
);
// Initialize the Gemini Developer API backend service.
// Create a `GenerativeModel` instance with a model that supports your use case.
final model = FirebaseAI.googleAI().generativeModel(
model: 'GEMINI_MODEL_NAME',
// Provide code execution as a tool that the model can use to generate its response.
tools: [
Tool.codeExecution(),
],
);
const prompt = 'What is the sum of the first 50 prime numbers? '
'Generate and run code for the calculation, and make sure you get all 50.';
final response = await model.generateContent([Content.text(prompt)]);
final buffer = StringBuffer();
for (final part in response.candidates.first.content.parts) {
if (part is TextPart) {
buffer.writeln(part.text);
} else if (part is ExecutableCodePart) {
buffer.writeln('Executable Code:');
buffer.writeln('Language: ${part.language}');
buffer.writeln('Code:');
buffer.writeln(part.code);
} else if (part is CodeExecutionResultPart) {
buffer.writeln('Code Execution Result:');
buffer.writeln('Outcome: ${part.outcome}');
buffer.writeln('Output:');
buffer.writeln(part.output);
}
}
Unity
using Firebase;
using Firebase.AI;
// Initialize the Gemini Developer API backend service.
var ai = FirebaseAI.GetInstance(FirebaseAI.Backend.GoogleAI());
// Create a `GenerativeModel` instance with a model that supports your use case.
var model = ai.GetGenerativeModel(
modelName: "GEMINI_MODEL_NAME",
// Provide code execution as a tool that the model can use to generate its response.
tools: new Tool[] { new Tool(new CodeExecution()) }
);
var prompt = "What is the sum of the first 50 prime numbers? " +
"Generate and run code for the calculation, and make sure you get all 50.";
var response = await model.GenerateContentAsync(prompt);
foreach (var part in response.Candidates.First().Content.Parts) {
if (part is ModelContent.TextPart tp) {
UnityEngine.Debug.Log($"Text = {tp.Text}");
} else if (part is ModelContent.ExecutableCodePart esp) {
UnityEngine.Debug.Log($"Code = {esp.Code}, Language = {esp.Language}");
} else if (part is ModelContent.CodeExecutionResultPart cerp) {
UnityEngine.Debug.Log($"Outcome = {cerp.Outcome}, Output = {cerp.Output}");
}
}
Aprende a elegir un modelo adecuados para tu caso de uso y tu app.
Cómo usar la ejecución de código en el chat
También puedes usar la ejecución de código como parte de un chat:
Swift
import FirebaseAILogic
// Initialize the Gemini Developer API backend service.
let ai = FirebaseAI.firebaseAI(backend: .googleAI())
// Create a `GenerativeModel` instance with a model that supports your use case
let model = ai.generativeModel(
modelName: "GEMINI_MODEL_NAME",
// Provide code execution as a tool that the model can use to generate its response.
tools: [.codeExecution()]
)
let prompt = """
What is the sum of the first 50 prime numbers?
Generate and run code for the calculation, and make sure you get all 50.
"""
let chat = model.startChat()
let response = try await chat.sendMessage(prompt)
guard let candidate = response.candidates.first else {
print("No candidates in response.")
return
}
for part in candidate.content.parts {
if let textPart = part as? TextPart {
print("Text = \(textPart.text)")
} else if let executableCode = part as? ExecutableCodePart {
print("Code = \(executableCode.code), Language = \(executableCode.language)")
} else if let executionResult = part as? CodeExecutionResultPart {
print("Outcome = \(executionResult.outcome), Result = \(executionResult.output ?? "no output")")
}
}
Kotlin
// Initialize the Gemini Developer API backend service.
// Create a `GenerativeModel` instance with a model that supports your use case.
val model = Firebase.ai(backend = GenerativeBackend.googleAI()).generativeModel(
modelName = "GEMINI_MODEL_NAME",
// Provide code execution as a tool that the model can use to generate its response.
tools = listOf(Tool.codeExecution())
)
val prompt = "What is the sum of the first 50 prime numbers? " +
"Generate and run code for the calculation, and make sure you get all 50."
val chat = model.startChat()
val response = chat.sendMessage(prompt)
response.candidates.first().content.parts.forEach {
if(it is TextPart) {
println("Text = ${it.text}")
}
if(it is ExecutableCodePart) {
println("Code = ${it.code}, Language = ${it.language}")
}
if(it is CodeExecutionResultPart) {
println("Outcome = ${it.outcome}, Result = ${it.output}")
}
}
Java
// Initialize the Gemini Developer API backend service.
// Create a `GenerativeModel` instance with a model that supports your use case.
GenerativeModel ai = FirebaseAI.getInstance(GenerativeBackend.googleAI())
.generativeModel("GEMINI_MODEL_NAME",
null,
null,
// Provide code execution as a tool that the model can use to generate its response.
List.of(Tool.codeExecution()));
// Use the GenerativeModelFutures Java compatibility layer which offers
// support for ListenableFuture and Publisher APIs
GenerativeModelFutures model = GenerativeModelFutures.from(ai);
String text = "What is the sum of the first 50 prime numbers? " +
"Generate and run code for the calculation, and make sure you get all 50.";
Content prompt = new Content.Builder()
.addText(text)
.build();
ChatFutures chat = model.startChat();
ListenableFuture response = chat.sendMessage(prompt);
Futures.addCallback(response, new FutureCallback() {
@Override
public void onSuccess(GenerateContentResponse response) {
// Access the first candidate's content parts
List parts = response.getCandidates().get(0).getContent().getParts();
for (Part part : parts) {
if (part instanceof TextPart) {
TextPart textPart = (TextPart) part;
System.out.println("Text = " + textPart.getText());
} else if (part instanceof ExecutableCodePart) {
ExecutableCodePart codePart = (ExecutableCodePart) part;
System.out.println("Code = " + codePart.getCode() + ", Language = " + codePart.getLanguage());
} else if (part instanceof CodeExecutionResultPart) {
CodeExecutionResultPart resultPart = (CodeExecutionResultPart) part;
System.out.println("Outcome = " + resultPart.getOutcome() + ", Result = " + resultPart.getOutput());
}
}
}
@Override
public void onFailure(Throwable t) {
t.printStackTrace();
}
}, executor);
Web
import { initializeApp } from "firebase/app";
import { getAI, getGenerativeModel, GoogleAIBackend } from "firebase/ai";
// TODO(developer) Replace the following with your app's Firebase configuration
// See: https://firebase.google.com/docs/web/learn-more#config-object
const firebaseConfig = {
// ...
};
// Initialize FirebaseApp
const firebaseApp = initializeApp(firebaseConfig);
// Initialize the Gemini Developer API backend service.
const ai = getAI(firebaseApp, { backend: new GoogleAIBackend() });
// Create a `GenerativeModel` instance with a model that supports your use case.
const model = getGenerativeModel(
ai,
{
model: "GEMINI_MODEL_NAME",
// Provide code execution as a tool that the model can use to generate its response.
tools: [{ codeExecution: {} }]
}
);
const prompt = "What is the sum of the first 50 prime numbers? " +
"Generate and run code for the calculation, and make sure you get all 50."
const chat = model.startChat()
const result = await chat.sendMessage(prompt);
const parts = result.response.candidates?.[0].content.parts;
if (parts) {
parts.forEach((part) => {
if (part.text) {
console.log(`Text: ${part.text}`);
} else if (part.executableCode) {
console.log(
`Code: ${part.executableCode.code}, Language: ${part.executableCode.language}`
);
} else if (part.codeExecutionResult) {
console.log(
`Outcome: ${part.codeExecutionResult.outcome}, Result: ${part.codeExecutionResult.output}`
);
}
});
}
Dart
import 'package:firebase_core/firebase_core.dart';
import 'package:firebase_ai/firebase_ai.dart';
import 'firebase_options.dart';
// Initialize FirebaseApp
await Firebase.initializeApp(
options: DefaultFirebaseOptions.currentPlatform,
);
// Initialize the Gemini Developer API backend service.
// Create a `GenerativeModel` instance with a model that supports your use case.
final model = FirebaseAI.googleAI().generativeModel(
model: 'GEMINI_MODEL_NAME',
// Provide code execution as a tool that the model can use to generate its response.
tools: [
Tool.codeExecution(),
],
);
final codeExecutionChat = await model.startChat();
const prompt = 'What is the sum of the first 50 prime numbers? '
'Generate and run code for the calculation, and make sure you get all 50.';
final response = await codeExecutionChat.sendMessage(Content.text(prompt));
final buffer = StringBuffer();
for (final part in response.candidates.first.content.parts) {
if (part is TextPart) {
buffer.writeln(part.text);
} else if (part is ExecutableCodePart) {
buffer.writeln('Executable Code:');
buffer.writeln('Language: ${part.language}');
buffer.writeln('Code:');
buffer.writeln(part.code);
} else if (part is CodeExecutionResultPart) {
buffer.writeln('Code Execution Result:');
buffer.writeln('Outcome: ${part.outcome}');
buffer.writeln('Output:');
buffer.writeln(part.output);
}
}
Unity
using Firebase;
using Firebase.AI;
// Initialize the Gemini Developer API backend service.
var ai = FirebaseAI.GetInstance(FirebaseAI.Backend.GoogleAI());
// Create a `GenerativeModel` instance with a model that supports your use case.
var model = ai.GetGenerativeModel(
modelName: "GEMINI_MODEL_NAME",
// Provide code execution as a tool that the model can use to generate its response.
tools: new Tool[] { new Tool(new CodeExecution()) }
);
var prompt = "What is the sum of the first 50 prime numbers? " +
"Generate and run code for the calculation, and make sure you get all 50.";
var chat = model.StartChat();
var response = await chat.SendMessageAsync(prompt);
foreach (var part in response.Candidates.First().Content.Parts) {
if (part is ModelContent.TextPart tp) {
UnityEngine.Debug.Log($"Text = {tp.Text}");
} else if (part is ModelContent.ExecutableCodePart esp) {
UnityEngine.Debug.Log($"Code = {esp.Code}, Language = {esp.Language}");
} else if (part is ModelContent.CodeExecutionResultPart cerp) {
UnityEngine.Debug.Log($"Outcome = {cerp.Outcome}, Output = {cerp.Output}");
}
}
Aprende a elegir un modelo adecuados para tu caso de uso y tu app.
Precios
No se aplican cargos adicionales por habilitar la ejecución de código y proporcionarla como herramienta para el modelo. Si el modelo decide usar la ejecución de código, se te facturará según la tarifa actual de los tokens de entrada y salida en función del modelo de Gemini que uses.
En el siguiente diagrama, se muestra el modelo de facturación para la ejecución de código:
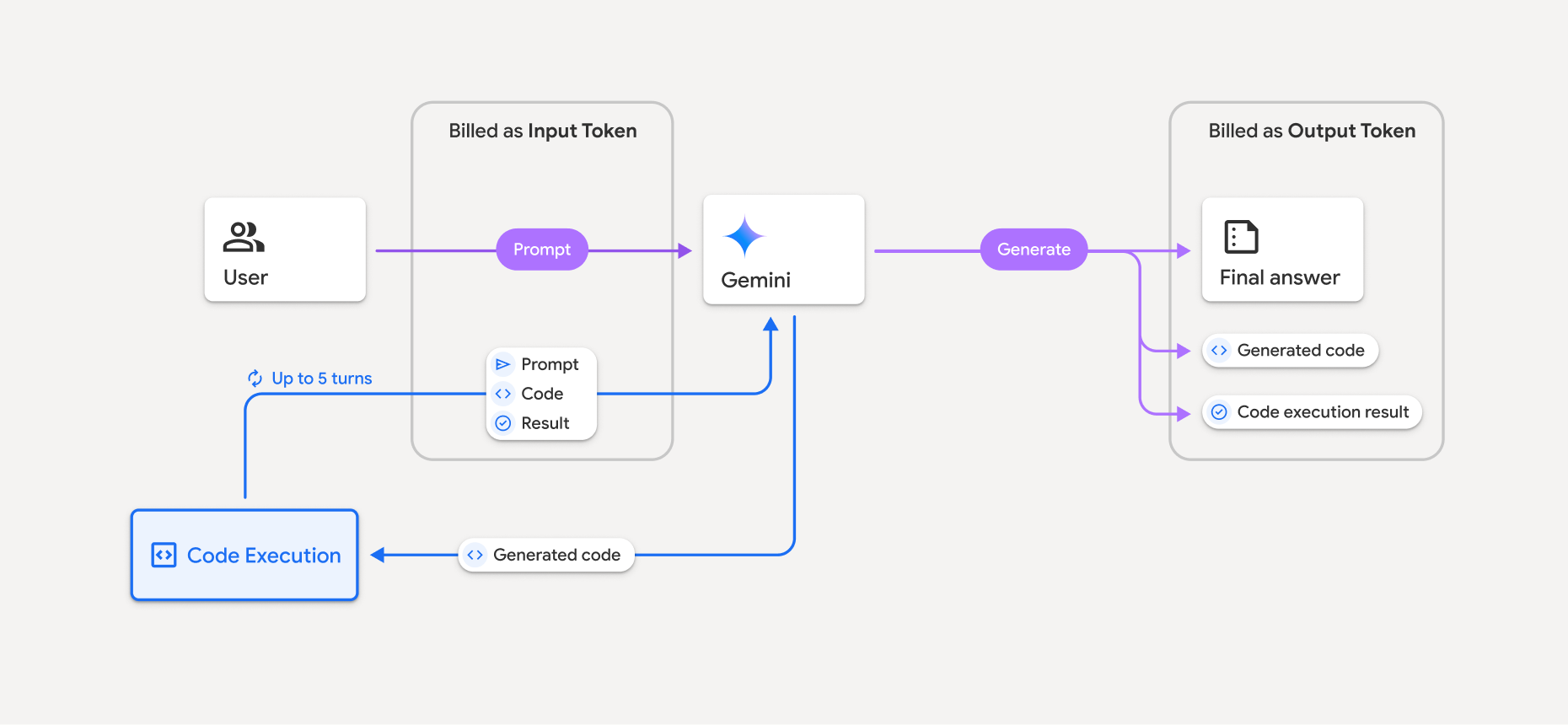
A continuación, se incluye un resumen de cómo se facturan los tokens cuando un modelo usa la ejecución de código:
La instrucción original se factura una vez. Sus tokens se etiquetan como tokens intermedios, que se facturan como tokens de entrada.
El código generado y el resultado del código ejecutado se facturan de la siguiente manera:
Cuando se usan durante la ejecución del código, se etiquetan como tokens intermedios y se facturan como tokens de entrada.
Cuando se incluyen como parte de la respuesta final, se facturan como tokens de salida.
El resumen final de la respuesta final se factura como tokens de salida.
El Gemini API incluye un recuento de tokens intermedio en la respuesta de la API, por lo que sabrás por qué se te cobra por los tokens de entrada más allá de tu instrucción inicial.
Ten en cuenta que el código generado puede incluir texto y resultados multimodales, como imágenes.
Limitaciones y recomendaciones
El modelo solo puede generar y ejecutar código de Python. No puede devolver otros artefactos, como archivos multimedia.
La ejecución de código puede durar un máximo de 30 segundos antes de que se agote el tiempo de espera.
En algunos casos, habilitar la ejecución de código puede provocar regresiones en otras áreas del resultado del modelo (por ejemplo, escribir un cuento).
La herramienta de ejecución de código no admite los URIs de archivos como entrada o salida. Sin embargo, la herramienta de ejecución de código admite la entrada de archivos y la salida de gráficos como bytes intercalados. Con estas capacidades de entrada y salida, puedes subir archivos CSV y de texto, hacer preguntas sobre los archivos y generar gráficos de Matplotlib como parte del resultado de la ejecución del código. Los tipos de MIME admitidos para los bytes intercalados son
.cpp,.csv,.java,.jpeg,.js,.png,.py,.tsy.xml.
Bibliotecas compatibles
El entorno de ejecución de código incluye las siguientes bibliotecas. No puedes instalar tus propias bibliotecas.
Envía comentarios sobre tu experiencia con Firebase AI Logic