
1. Przegląd
|
|

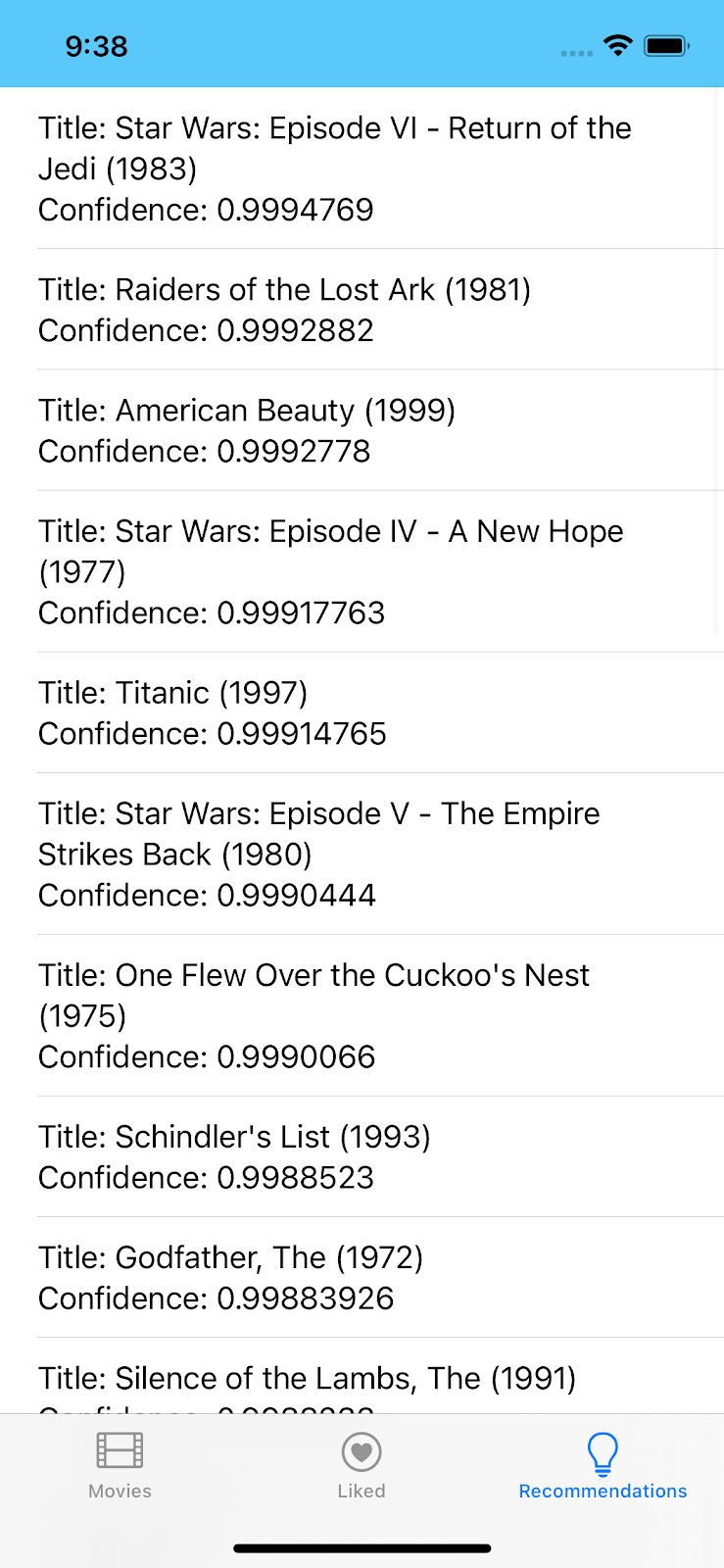
Witamy w samouczku dotyczącym rekomendacji z użyciem TensorFlow Lite i Firebase. Z tych ćwiczeń z programowania dowiesz się, jak używać TensorFlow Lite i Firebase do wdrażania w aplikacji modelu rekomendacji. Te ćwiczenia z programowania są oparte na tym przykładzie TensorFlow Lite.
Zalecenia umożliwiają aplikacjom korzystanie z uczenia maszynowego w celu inteligentnego wyświetlania najbardziej odpowiednich treści dla każdego użytkownika. Biorą pod uwagę wcześniejsze zachowania użytkowników, aby sugerować treści aplikacji, z którymi użytkownik może chcieć wejść w interakcję w przyszłości. W tym celu korzystają z modelu wytrenowanego na podstawie zbiorczych zachowań dużej liczby innych użytkowników.
Z tego samouczka dowiesz się, jak za pomocą Firebase Analytics uzyskiwać dane o użytkownikach aplikacji, na podstawie tych danych tworzyć model uczenia maszynowego do generowania rekomendacji, a następnie używać tego modelu w aplikacji na iOS do przeprowadzania wnioskowania i uzyskiwania rekomendacji. W szczególności nasze rekomendacje będą sugerować, które filmy użytkownik najprawdopodobniej obejrzy, biorąc pod uwagę listę filmów, które wcześniej polubił.
Czego się nauczysz
- Integrowanie Firebase Analytics z aplikacją na Androida w celu zbierania danych o zachowaniach użytkowników
- Eksportowanie tych danych do Google BigQuery
- Wstępne przetwarzanie danych i trenowanie modelu rekomendacji TF Lite
- Wdrażanie modelu TF Lite w Firebase ML i uzyskiwanie do niego dostępu z aplikacji
- Przeprowadzanie wnioskowania na urządzeniu za pomocą modelu w celu sugerowania użytkownikom rekomendacji
Czego potrzebujesz
- Xcode 11 (lub nowszy)
- CocoaPods 1.9.1 lub nowszy
Jak zamierzasz korzystać z tego samouczka?
Jak oceniasz swoje doświadczenie w tworzeniu aplikacji na iOS?
2. Tworzenie projektu w konsoli Firebase
Dodawanie Firebase do projektu
- Otwórz konsolę Firebase.
- Wybierz Utwórz nowy projekt i nadaj mu nazwę „Firebase ML iOS Codelab”.
3. Pobieranie przykładowego projektu
Pobieranie kodu
Zacznij od sklonowania przykładowego projektu i uruchomienia polecenia pod update w katalogu projektu:
git clone https://github.com/FirebaseExtended/codelab-contentrecommendation-ios.git cd codelab-contentrecommendation-ios/start pod install --repo-update
Jeśli nie masz zainstalowanego narzędzia git, możesz też pobrać projekt przykładowy ze strony GitHub lub klikając ten link. Po pobraniu projektu uruchom go w Xcode i poeksperymentuj z rekomendacją, aby sprawdzić, jak działa.
Konfigurowanie Firebase
Aby utworzyć nowy projekt w Firebase, postępuj zgodnie z dokumentacją. Gdy utworzysz projekt, pobierz z konsoli Firebase plik GoogleService-Info.plist projektu i przeciągnij go do katalogu głównego projektu Xcode.

Dodaj Firebase do pliku Podfile i uruchom polecenie pod install.
pod 'FirebaseAnalytics' pod 'FirebaseMLModelDownloader', '9.3.0-beta' pod 'TensorFlowLiteSwift'
W metodzie didFinishLaunchingWithOptions pliku AppDelegate zaimportuj Firebase na początku pliku.
import FirebaseCore
Dodaj wywołanie, aby skonfigurować Firebase.
FirebaseApp.configure()
Uruchom projekt ponownie, aby sprawdzić, czy aplikacja jest prawidłowo skonfigurowana i nie ulega awarii podczas uruchamiania.
- Sprawdź, czy opcja „Włącz Google Analytics w tym projekcie” jest włączona.
- Wykonaj pozostałe kroki konfiguracji w konsoli Firebase, a potem kliknij Utwórz projekt (lub Dodaj Firebase, jeśli używasz istniejącego projektu Google).
4. Dodawanie do aplikacji Firebase Analytics
W tym kroku dodasz do aplikacji Firebase Analytics, aby rejestrować dane o zachowaniu użytkowników (w tym przypadku informacje o tym, które filmy im się podobają). Dane te będą w przyszłości używane zbiorczo do trenowania modelu rekomendacji.
Konfigurowanie Firebase Analytics w aplikacji
LikedMoviesViewModel zawiera funkcje do przechowywania filmów, które podobają się użytkownikowi. Za każdym razem, gdy użytkownik polubi nowy film, chcemy też wysyłać zdarzenie dziennika Analytics, aby zarejestrować to polubienie.
Dodaj poniższy kod, aby zarejestrować zdarzenie analityczne, gdy użytkownik kliknie przycisk „Lubię” przy filmie.
AllMoviesCollectionViewController.swift
import FirebaseAnalytics
//
override func collectionView(_ collectionView: UICollectionView, didSelectItemAt indexPath: IndexPath) {
//
if movie.liked == nil {
movie.liked = true
Analytics.logEvent(AnalyticsEventSelectItem, parameters: [AnalyticsParameterItemID: movie.id])
} else {
movie.liked?.toggle()
}
}
5. Testowanie integracji z Analytics
W tym kroku wygenerujemy w aplikacji zdarzenia Analytics i sprawdzimy, czy są one wysyłane do konsoli Firebase.
Włączanie logowania debugowania w Analytics
Zdarzenia logowane przez aplikację są zwykle grupowane w ciągu około godziny i przesyłane razem. Dzięki temu oszczędzasz baterię na urządzeniach użytkowników i ograniczasz wykorzystanie danych sieciowych. Aby jednak zweryfikować implementację Analytics (i wyświetlić dane Analytics w raporcie DebugView), możesz włączyć tryb debugowania na urządzeniu używanym do programowania, aby przesyłać zdarzenia z minimalnym opóźnieniem.
Aby włączyć tryb debugowania Analytics na urządzeniu, którego używasz do programowania, wpisz w Xcode ten argument wiersza poleceń:
-FIRDebugEnabled
W tym momencie integracja Firebase Analytics z aplikacją została zakończona. Gdy użytkownicy będą korzystać z aplikacji i polubią filmy, ich polubienia będą rejestrowane zbiorczo. W dalszej części tego laboratorium użyjemy tych zagregowanych danych do wytrenowania modelu rekomendacji. Poniższy krok jest opcjonalny i pozwala wyświetlać w konsoli Firebase te same zdarzenia Analytics, które były widoczne w Logcat. Możesz przejść do następnej strony.
Opcjonalnie: potwierdź zdarzenia Analytics w konsoli Firebase
- Otwórz konsolę Firebase.
- W sekcji Analytics kliknij DebugView.
- W Xcode kliknij Run (Uruchom), aby uruchomić aplikację i dodać kilka filmów do listy polubionych.
- W widoku DebugView w konsoli Firebase sprawdź, czy te zdarzenia są rejestrowane podczas dodawania filmów w aplikacji.
6. Eksportowanie danych z Analytics do BigQuery
BigQuery to usługa Google Cloud, która umożliwia analizowanie i przetwarzanie dużych ilości danych. W tym kroku połączysz projekt w konsoli Firebase z BigQuery, aby dane Analytics generowane przez Twoją aplikację były automatycznie eksportowane do BigQuery.
Włączanie eksportowania do BigQuery
- Otwórz konsolę Firebase.
- Obok opcji Przegląd projektu kliknij ikonę koła zębatego Ustawienia, a następnie wybierz Ustawienia projektu.
- Kliknij kartę Integracje.
- W bloku BigQuery kliknij Połącz (lub Zarządzaj).
- W kroku Łączenie Firebase z BigQuery kliknij Dalej.
- W sekcji Skonfiguruj integrację kliknij przełącznik, aby włączyć wysyłanie danych Google Analytics, a następnie wybierz Połącz z BigQuery.
W projekcie w konsoli Firebase włączono automatyczne wysyłanie danych o zdarzeniach Firebase Analytics do BigQuery. Dzieje się to automatycznie bez konieczności podejmowania dalszych działań, jednak pierwszy eksport, który tworzy zbiór danych analitycznych w BigQuery, może nastąpić dopiero po 24 godzinach. Po utworzeniu zbioru danych Firebase stale eksportuje nowe zdarzenia Analytics do BigQuery do tabeli danych częściowych i grupuje zdarzenia z poprzednich dni w tabeli zdarzeń.
Trenowanie modelu rekomendacji wymaga dużej ilości danych. Nie mamy jeszcze aplikacji generującej duże ilości danych, więc w następnym kroku zaimportujemy do BigQuery przykładowy zbiór danych, którego będziemy używać w dalszej części tego samouczka.
7. Używanie BigQuery do uzyskiwania danych treningowych modelu
Po połączeniu konsoli Firebase z eksportem do BigQuery dane zdarzeń analitycznych aplikacji będą po pewnym czasie automatycznie wyświetlane w konsoli BigQuery. Aby uzyskać wstępne dane na potrzeby tego samouczka, w tym kroku zaimportujemy do konsoli BigQuery istniejący przykładowy zbiór danych, który posłuży nam do trenowania modelu rekomendacji.
Importowanie przykładowego zbioru danych do BigQuery
- Otwórz panel BigQuery w konsoli Google Cloud.
- W menu wybierz nazwę projektu.
- Aby wyświetlić szczegóły, w dolnej części menu po lewej stronie BigQuery wybierz nazwę projektu.
- Kliknij Utwórz zbiór danych, aby otworzyć panel tworzenia zbioru danych.
- Wpisz „firebase_recommendations_dataset” w polu Identyfikator zbioru danych i kliknij Utwórz zbiór danych.
- Nowy zbiór danych pojawi się w menu po lewej stronie pod nazwą projektu. Kliknij ją.
- Kliknij Utwórz tabelę, aby otworzyć panel tworzenia tabeli.
- W menu Utwórz tabelę z wybierz „Google Cloud Storage”.
- W polu Wybierz plik z zasobnika w GCS wpisz „gs://firebase-recommendations/recommendations-test/formatted_data_filtered.txt”.
- W menu Format pliku wybierz „JSONL”.
- W polu Nazwa tabeli wpisz „recommendations_table”.
- Zaznacz pole w sekcji Schemat > Automatyczne wykrywanie > Schemat i parametry wejściowe.
- Kliknij Utwórz tabelę.
Przeglądanie przykładowego zbioru danych
Na tym etapie możesz opcjonalnie przeanalizować schemat i wyświetlić podgląd tego zbioru danych.
- W menu po lewej stronie kliknij firebase-recommendations-dataset, aby rozwinąć tabele, które zawiera.
- Wybierz tabelę recommendations-table, aby wyświetlić jej schemat.
- Kliknij Podgląd, aby wyświetlić rzeczywiste dane zdarzeń Analytics, które zawiera ta tabela.
Tworzenie danych logowania do konta usługi
Teraz utworzymy w projekcie w konsoli Google Cloud dane logowania konta usługi, których użyjemy w następnym kroku w środowisku Colab, aby uzyskać dostęp do danych BigQuery i je wczytać.
- Sprawdź, czy w projekcie Google Cloud włączone są płatności.
- Włącz interfejsy BigQuery API i BigQuery Storage API. < kliknij tutaj>
- Otwórz stronę tworzenia klucza do konta usługi.
- Na liście Konto usługi wybierz Nowe konto usługi.
- W polu Nazwa konta usługi wpisz nazwę.
- Na liście Rola wybierz Projekt > Właściciel.
- Kliknij Utwórz. Na komputer zostanie pobrany plik JSON zawierający klucz.
W następnym kroku użyjemy Google Colab do wstępnego przetworzenia tych danych i wytrenowania naszego modelu rekomendacji.
8. Przetwarzanie wstępne danych i trenowanie modelu rekomendacji
W tym kroku użyjemy notatnika Colab, aby wykonać te czynności:
- zaimportować dane BigQuery do notatnika Colab;
- przetworzyć wstępnie dane, aby przygotować je do trenowania modelu;
- wytrenować model rekomendacji na podstawie danych analitycznych,
- wyeksportować model jako model TF Lite,
- wdrożyć model w konsoli Firebase, aby można było go używać w aplikacji;
Zanim uruchomimy notatnik szkoleniowy Colab, najpierw włączymy interfejs Firebase Model Management API, aby Colab mógł wdrożyć wytrenowany model w naszej konsoli Firebase.
Włączanie interfejsu Firebase Model Management API
Utwórz zasobnik do przechowywania modeli ML
W konsoli Firebase otwórz sekcję Pamięć i kliknij Rozpocznij. 
Postępuj zgodnie z instrukcjami, aby skonfigurować zasobnik.
Włączanie interfejsu Firebase ML API
Otwórz stronę interfejsu Firebase ML API w konsoli Google Cloud i kliknij Włącz.
Trenowanie i wdrażanie modelu za pomocą notatnika Colab
Otwórz notatnik Colab, korzystając z tego linku, i wykonaj podane w nim czynności. Po wykonaniu czynności w notatniku Colab w konsoli Firebase pojawi się wdrożony plik modelu TF Lite, który możemy zsynchronizować z naszą aplikacją.
Otwórz w Colab
9. Pobieranie modelu w aplikacji
W tym kroku zmodyfikujemy aplikację, aby pobrać z systemów uczących się Firebase wytrenowany przez nas model.
Dodawanie zależności Firebase ML
Aby używać w aplikacji modeli uczenia maszynowego Firebase, musisz dodać to zależności. Powinna być już dodana (sprawdź to).
Podfile
import FirebaseCore
import FirebaseMLModelDownloader
Pobieranie modelu za pomocą interfejsu Firebase Model Manager API
Skopiuj poniższy kod do pliku ModelLoader.swift, aby skonfigurować warunki pobierania modelu i utworzyć zadanie pobierania, które zsynchronizuje model zdalny z naszą aplikacją.
ModelLoader.swift
static func downloadModel(named name: String,
completion: @escaping (CustomModel?, DownloadError?) -> Void) {
guard FirebaseApp.app() != nil else {
completion(nil, .firebaseNotInitialized)
return
}
guard success == nil && failure == nil else {
completion(nil, .downloadInProgress)
return
}
let conditions = ModelDownloadConditions(allowsCellularAccess: false)
ModelDownloader.modelDownloader().getModel(name: name, downloadType: .localModelUpdateInBackground, conditions: conditions) { result in
switch (result) {
case .success(let customModel):
// Download complete.
// The CustomModel object contains the local path of the model file,
// which you can use to instantiate a TensorFlow Lite classifier.
return completion(customModel, nil)
case .failure(let error):
// Download was unsuccessful. Notify error message.
completion(nil, .downloadFailed(underlyingError: error))
}
}
}
10. Integrowanie modelu rekomendacji TensorFlow Lite z aplikacją
Środowisko wykonawcze TensorFlow Lite umożliwi Ci używanie modelu w aplikacji do generowania rekomendacji. W poprzednim kroku zainicjowaliśmy interpreter TFLite za pomocą pobranego pliku modelu. W tym kroku najpierw wczytamy słownik i etykiety, które będą towarzyszyć naszemu modelowi w kroku wnioskowania. Następnie dodamy przetwarzanie wstępne, aby wygenerować dane wejściowe dla naszego modelu, oraz przetwarzanie końcowe, w którym wyodrębnimy wyniki wnioskowania.
Wczytaj słownik i etykiety
Etykiety użyte do wygenerowania kandydatów do rekomendacji przez model rekomendacji są wymienione w pliku sorted_movie_vocab.json w folderze zasobów. Skopiuj poniższy kod, aby wczytać te kandydatury.
RecommendationsViewController.swift
func getMovies() -> [MovieItem] {
let barController = self.tabBarController as! TabBarController
return barController.movies
}
Wdrażanie wstępnego przetwarzania
W kroku wstępnego przetwarzania zmieniamy format danych wejściowych, aby pasował do formatu oczekiwanego przez nasz model. Jeśli nie mamy jeszcze wielu polubień użytkowników, uzupełniamy długość danych wejściowych wartością zastępczą. Skopiuj poniższy kod:
RecommendationsViewController.swift
// Given a list of selected items, preprocess to get tflite input.
func preProcess() -> Data {
let likedMovies = getLikedMovies().map { (MovieItem) -> Int32 in
return MovieItem.id
}
var inputData = Data(copyingBufferOf: Array(likedMovies.prefix(10)))
// Pad input data to have a minimum of 10 context items (4 bytes each)
while inputData.count < 10*4 {
inputData.append(0)
}
return inputData
}
Uruchamianie interpretera w celu generowania rekomendacji
Używamy tu modelu pobranego w poprzednim kroku, aby przeprowadzić wnioskowanie na wstępnie przetworzonych danych wejściowych. Określamy typ danych wejściowych i wyjściowych dla naszego modelu i przeprowadzamy wnioskowanie, aby wygenerować rekomendacje filmów. Skopiuj poniższy kod do aplikacji.
RecommendationsViewController.swift
import TensorFlowLite
RecommendationsViewController.swift
private var interpreter: Interpreter?
func loadModel() {
// Download the model from Firebase
print("Fetching recommendations model...")
ModelDownloader.fetchModel(named: "recommendations") { (filePath, error) in
guard let path = filePath else {
if let error = error {
print(error)
}
return
}
print("Recommendations model download complete")
self.loadInterpreter(path: path)
}
}
func loadInterpreter(path: String) {
do {
interpreter = try Interpreter(modelPath: path)
// Allocate memory for the model's input `Tensor`s.
try interpreter?.allocateTensors()
let inputData = preProcess()
// Copy the input data to the input `Tensor`.
try self.interpreter?.copy(inputData, toInputAt: 0)
// Run inference by invoking the `Interpreter`.
try self.interpreter?.invoke()
// Get the output `Tensor`
let confidenceOutputTensor = try self.interpreter?.output(at: 0)
let idOutputTensor = try self.interpreter?.output(at: 1)
// Copy output to `Data` to process the inference results.
let confidenceOutputSize = confidenceOutputTensor?.shape.dimensions.reduce(1, {x, y in x * y})
let idOutputSize = idOutputTensor?.shape.dimensions.reduce(1, {x, y in x * y})
let confidenceResults =
UnsafeMutableBufferPointer<Float32>.allocate(capacity: confidenceOutputSize!)
let idResults =
UnsafeMutableBufferPointer<Int32>.allocate(capacity: idOutputSize!)
_ = confidenceOutputTensor?.data.copyBytes(to: confidenceResults)
_ = idOutputTensor?.data.copyBytes(to: idResults)
postProcess(idResults, confidenceResults)
print("Successfully ran inference")
DispatchQueue.main.async {
self.tableView.reloadData()
}
} catch {
print("Error occurred creating model interpreter: \(error)")
}
}
Wdrożenie przetwarzania końcowego
Na koniec przetwarzamy dane wyjściowe z naszego modelu, wybierając wyniki o najwyższym poziomie ufności i usuwając zawarte w nich wartości (filmy, które użytkownik już polubił). Skopiuj poniższy kod do aplikacji.
RecommendationsViewController.swift
// Postprocess to get results from tflite inference.
func postProcess(_ idResults: UnsafeMutableBufferPointer<Int32>, _ confidenceResults: UnsafeMutableBufferPointer<Float32>) {
for i in 0..<10 {
let id = idResults[i]
let movieIdx = getMovies().firstIndex { $0.id == id }
let title = getMovies()[movieIdx!].title
recommendations.append(Recommendation(title: title, confidence: confidenceResults[i]))
}
}
Przetestuj aplikację!
Uruchom ponownie aplikację. Gdy wybierzesz kilka filmów, automatycznie pobierze ona nowy model i zacznie generować rekomendacje.
11. Gratulacje!
W aplikacji masz już funkcję rekomendacji opartą na TensorFlow Lite i Firebase. Pamiętaj, że techniki i potok przedstawione w tym ćwiczeniu z programowania można uogólnić i wykorzystać do wyświetlania innych rodzajów rekomendacji.
Omówione zagadnienia
- Firebase ML
- Firebase Analytics
- Eksportowanie zdarzeń analitycznych do BigQuery
- Wstępne przetwarzanie zdarzeń Analytics
- Trenowanie modelu rekomendacji TensorFlow
- Eksportowanie modelu i wdrażanie go w konsoli Firebase
- Wyświetlanie rekomendacji filmów w aplikacji
Następne kroki
- Wdróż w aplikacji rekomendacje ML Firebase.
Więcej informacji
Masz pytanie?
Zgłaszanie problemów